9.0 Présentation
9.0.1 Pourquoi devrais-je suivre ce module?
Bienvenue sur les concepts FHRP!
Votre réseau est opérationnel. Vous avez conquis la redondance de couche 2 sans boucles de couche 2. Tous vos appareils obtiennent leurs adresses dynamiquement. Vous êtes excellent à l’administration des réseaux ! Mais attends. Un de vos routeurs, le routeur de passerelle par défaut en fait, est tombé en panne. Aucun de vos hôtes ne peut envoyer de messages en dehors du réseau immédiat. Cela va prendre un certain temps pour que ce routeur de passerelle par défaut fonctionne à nouveau. Vous avez beaucoup de gens en colère qui vous demandent quand le réseau retournera.
Vous pouvez éviter ce problème facilement. Les protocoles de redondance de premier saut (FHRP) sont la solution dont vous avez besoin. Ce module explique le fonctionnement du protocoles FHRP et tous les types de protocoles FHRP qui sont à votre disposition. L’un de ces types est un FHRP propriétaire de CISCO appelé le protocole HSRP (Hot Standby Router Protocol). Vous apprendrez comment le protocole HSRP fonctionne, puis terminerez une activité Packet Tracer où vous allez configurer et vérifier le protocole HSRP. N’attendez pas, commencez!
9.0.2 Qu’est-ce que je vais apprendre dans ce module?
Titre du module: Concepts du FHRP (protocoles de redondance au premier saut)
Objectif du module: Expliquer comment les protocoles FHRP fournissent des services de passerelle par défaut dans un réseau redondant.
| Titre du rubrique | Objectif du rubrique |
|---|---|
| Protocoles de redondance au premier saut | Expliquer l’objectif et le fonctionnement des protocoles FHRP (First Hop Redundancy). |
| HSRP | Expliquer le fonctionnement du protocole HSRP. |
9.1 Protocoles de redondance au premier saut
9.1.1 Limitations de passerelle par défaut
En cas de défaillance d’un routeur ou d’une interface de routeur (servant de passerelle par défaut), les hôtes configurés avec cette passerelle par défaut sont isolés des réseaux extérieurs. Un mécanisme est nécessaire pour offrir des passerelles par défaut alternatives dans les réseaux commutés où deux routeurs ou plus sont connectés aux mêmes VLAN. Ce mécanisme est fourni par les protocoles de redondance de premier saut (FHRP).
Dans un réseau commuté, chaque client reçoit une seule passerelle par défaut. Il n’est pas possible d’utiliser une passerelle secondaire, même s’il existe un deuxième chemin pour transporter les paquets hors du segment local.
Dans cette figure, R1 est responsable du routage des paquets en provenance de PC1. Si R1 n’est plus disponible, les protocoles de routage peuvent converger dynamiquement. R2 achemine désormais les paquets en provenance des réseaux extérieurs, qui auraient normalement été destinés à R1. Cependant, le trafic en provenance du réseau interne associé à R1, y compris le trafic en provenance des stations de travail, des serveurs et des imprimantes configurés avec R1 comme passerelle par défaut, est encore renvoyé vers R1 puis abandonné.
Remarque: Aux fins de discussion sur la redondance des routeurs, nous partirons du principe qu’il n’existe pas de différences fonctionnelles entre un commutateur de couche 3 et un routeur de la couche de distribution. Dans la pratique, il est courant qu’un commutateur de couche 3 joue le rôle de passerelle par défaut pour chaque VLAN d’un réseau commuté. Cette discussion se concentre sur la fonctionnalité de routage, quel que soit le périphérique physique utilisé.
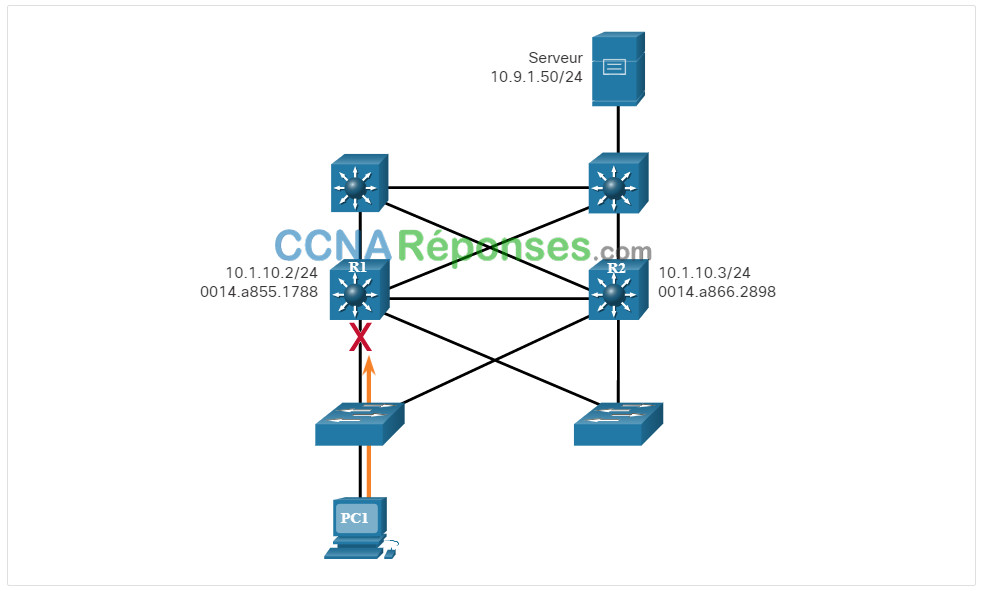
Les périphériques finaux sont généralement configurés avec une adresse IPv4 unique pour une passerelle par défaut. Cette adresse ne change pas lorsque la topologie de réseau est modifiée. Si cette adresse IPv4 de passerelle par défaut n’est pas accessible, le périphérique local ne pourra pas envoyer des paquets à partir du segment de réseau local, ce qui le déconnectera des autres réseaux. Même si un routeur redondant pourrait servir de passerelle par défaut sur ce segment, ces périphériques ne peuvent pas déterminer dynamiquement l’adresse d’une nouvelle passerelle par défaut.
Remarque: les périphériques IPv6 reçoivent leur adresse de passerelle par défaut dynamiquement à partir de l’annonce de routeur ICMPv6. Toutefois, les périphériques IPv6 bénéficient d’un basculement plus rapide vers la nouvelle passerelle par défaut lors de l’utilisation de protocoles FHRP.
9.1.2 La redondance de routeur
Pour éviter tout risque de point de défaillance unique au niveau de la passerelle par défaut, il est possible d’implémenter un routeur virtuel. Pour implémenter ce type de redondance de routeur, plusieurs routeurs sont configurés pour un fonctionnement conjoint, de manière à présenter l’illusion d’un routeur unique au regard des hôtes du LAN, comme illustré dans la figure. En partageant une adresse IP et une adresse MAC, plusieurs routeurs peuvent jouer le rôle d’un routeur virtuel unique.
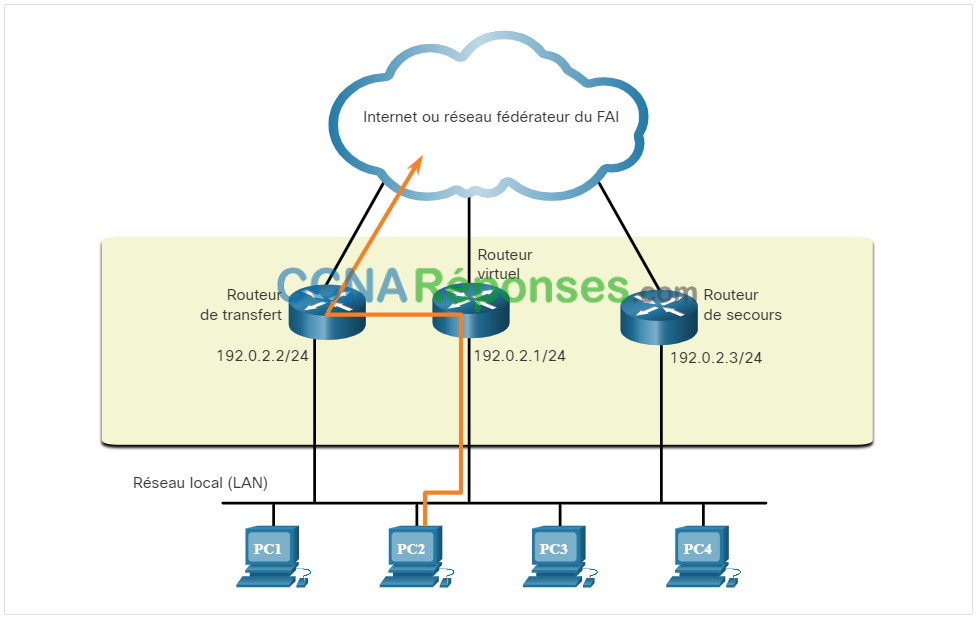
L’adresse IPv4 du routeur virtuel est configurée en tant que passerelle par défaut pour les postes de travail sur un segment IPv4 donné. Lorsque des trames sont envoyées à la passerelle par défaut par des périphériques hôtes, les hôtes utilisent le processus ARP pour résoudre l’adresse MAC associée à l’adresse IPv4 de la passerelle par défaut. La résolution ARP renvoie l’adresse MAC du routeur virtuel. Les trames envoyées à l’adresse MAC du routeur virtuel peuvent alors être traitées physiquement par le routeur actif, au sein du groupe de routeurs virtuel. Un protocole est utilisé pour identifier au moins deux routeurs comme périphériques chargés de traiter les trames envoyées à l’adresse MAC ou à l’adresse IP d’un routeur virtuel unique. Les périphériques hôtes transmettent le trafic à l’adresse du routeur virtuel. Le routeur physique qui réachemine ce trafic est transparent pour les périphériques hôtes.
Un protocole de redondance offre le mécanisme nécessaire pour déterminer quel routeur doit être actif dans le réacheminement du trafic. Il détermine également quand le rôle de réacheminement doit être repris par un routeur en veille. La transition d’un routeur de transfert à un autre est transparente pour les périphériques finaux.
La capacité d’un réseau à effectuer une reprise dynamique après la défaillance d’un périphérique jouant le rôle de passerelle par défaut est appelée « redondance au premier saut ».
9.1.3 Étapes relatives au basculement du routeur
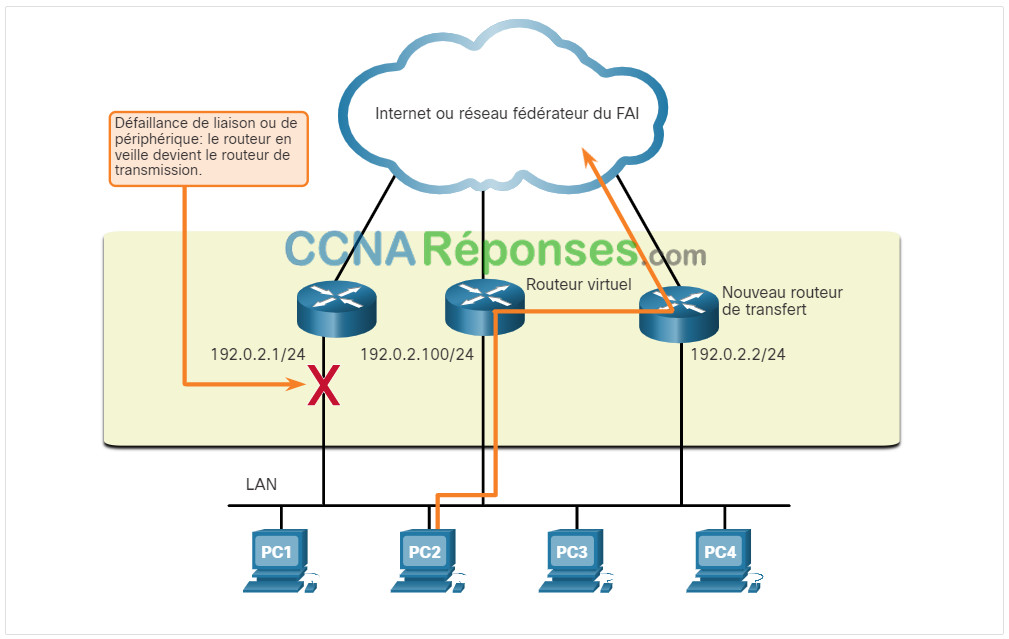
Lorsque le routeur actif est défaillant, le protocole de redondance définit le rôle de routeur actif pour le routeur en veille, comme illustré dans la figure. Voici la procédure en cas de défaillance du routeur actif:
1. Le routeur en veille cesse de voir les messages Hello du routeur de transfert.
2. Le routeur en veille assume le rôle du routeur de transfert.
3. Étant donné que le nouveau routeur de transfert assume à la fois le rôle de l’adresse IPv4 et celui de l’adresse MAC du routeur virtuel, aucune interruption de service n’est constatée au niveau des périphériques hôtes.
9.1.4 Options FHRP
Le protocole FHRP utilisé dans un environnement de production dépend largement de l’équipement et des besoins du réseau. Le tableau répertorie toutes les options disponibles pour les protocoles FHRP.
| Options FHRP | Description |
|---|---|
| Protocole HSRP (Hot Standby Router Protocol) | Le protocole HRSP est un FHRP propriétaire de CISCO qui est conçu pour permettre le basculement transparent d’un périphérique IPv4 au premier saut. Le protocole HSRP offre une disponibilité de réseau élevée, par le biais d’une redondance de routage au premier saut pour les hôtes IPv4 des réseaux configurés avec une adresse de passerelle par défaut IPv4. HSRP est utilisé dans un groupe de routeurs pour sélectionner un périphérique actif et un périphérique en veille. Dans un groupe d’interfaces de périphérique, le périphérique actif est celui qui est utilisé pour le routage des paquets ; le périphérique en veille est celui qui prend le relais en cas de défaillance du périphérique actif ou lorsque certaines conditions prédéfinies sont réunies. La fonction du routeur en veille HSRP est de surveiller l’état de fonctionnement du groupe HSRP et de prendre rapidement la responsabilité du réacheminement des paquets lorsque le routeur actif est défaillant. |
| HSRP pour IPv6 | Il s’agit d’un protocole FHRP propriétaire de Cisco offrant la même fonctionnalité que le protocole HSRP, mais dans un environnement IPv6. Un groupe HSRP IPv6 possède une adresse MAC virtuelle dérivée du numéro de groupe HSRP et une adresse link-local IPv6 dérivée de l’adresse MAC virtuelle HSRP. Des annonces de routeur périodiques (RA, Router Advertisement) sont renvoyées pour l’adresse virtuelle link-local HSRP IPv6 lorsque le groupe HSRP est actif. Lorsque le groupe devient inactif, ces RA cessent après l’envoi d’une dernière RA. |
| Protocole VRRPv2 (Virtual Router Redundancy Protocol version 2) | Il s’agit d’un protocole de sélection non propriétaire qui affecte dynamiquement la responsabilité d’un ou de plusieurs routeurs virtuels aux routeurs VRRP d’un réseau local IPv4. Cela permet à plusieurs routeurs de bénéficier d’un lien à accès multiple pour utiliser la même adresse IPv4 virtuelle. Un routeur VRRP est configuré pour exécuter le protocole VRRP conjointement à un ou plusieurs autres routeurs associés à un réseau local. Dans une configuration VRRP, un routeur est choisi comme routeur virtuel principal, les autres servant de routeurs de secours en cas de défaillance de celui-ci. |
| VRRPv3 | Il s’agit d’un protocole qui offre la capacité de prendre en charge les adresses IPv4 et IPv6. Le protocole VRRPv3 fonctionne dans les environnements multifournisseurs ; il est plus évolutif que VRRPv2. |
| Protocole GLBP (Gateway Load Balancing Protocol) | Il s’agit d’un protocole FHRP propriétaire de Cisco qui protège le trafic de données en provenance d’un routeur ou d’un circuit défaillant, tel que HSRP et VRRP, tout en permettant un équilibrage (également appelé partage de charge) de la charge au sein d’un groupe de routeurs redondants. |
| GLBP pour IPv6 | Il s’agit d’un protocole FHRP propriétaire de Cisco qui offre la même fonctionnalité que le protocole GLBP, mais dans un environnement IPv6. Le protocole GLBP pour IPv6 offre un routeur de secours automatique pour les hôtes IPv6 configurés avec une passerelle par défaut unique, sur un un réseau local. Plusieurs routeurs de premier saut se combinent dans le réseau local pour offrir un routeur de premier saut IPv6 virtuel unique, tout en partageant la charge de réacheminement des paquets IPv6. |
| Protocole IRDP (ICMP Router Discovery Protocol) | Il s’agit d’une solution FHRP héritée spécifiée dans RFC 1256. Le protocole IRDP permet aux hôtes IPv4 de localiser les routeurs en offrant une connectivité IPv4 à d’autres réseaux IP (non locaux). |
9.2 HSRP
9.2.1 Présentation du protocole HSRP
Le protocole HSRP (Hot Standby Router Protocol) a été conçu par Cisco pour assurer la redondance des passerelles sans configuration supplémentaire des périphériques finaux.
Le Protocole HSRP (Hot Standby Router Protocol) est un protocole FHRP propriétaire de Cisco, conçu pour permettre le basculement transparent d’un périphérique IPv4 au premier saut.
Le protocole HSRP offre une disponibilité de réseau élevée, par le biais d’une redondance de routage au premier saut pour les hôtes IP des réseaux configurés avec une adresse de passerelle par défaut IP. Il est utilisé dans un groupe de routeurs pour sélectionner un périphérique actif et un périphérique en veille. Dans un groupe d’interfaces de périphérique, le périphérique actif est celui qui est utilisé pour le routage des paquets; le périphérique en veille est celui qui prend le relais en cas de défaillance du périphérique actif ou lorsque certaines conditions prédéfinies sont réunies. La fonction du routeur en veille HSRP est de surveiller l’état de fonctionnement du groupe HSRP et de prendre rapidement la responsabilité du réacheminement des paquets lorsque le routeur actif est défaillant.
9.2.2 Priorité et Préemption HSRP
Le rôle des routeurs actifs et de secours est déterminé lors du processus de sélection de HSRP. Par défaut, le routeur avec l’adresse IPv4 la plus élevée devient le routeur actif. Cependant, il est toujours plus judicieux de contrôler la manière dont votre réseau fonctionne en conditions normales plutôt que de laisser le hasard faire les choses.
Priorité HSRP
Il est possible d’utiliser la priorité HSRP pour déterminer le routeur actif. Le routeur associé à la priorité HSRP la plus élevée devient le routeur actif. La valeur par défaut de la priorité HSRP est 100. Si les priorités sont identiques, le routeur avec l’adresse IPv4 la plus élevée devient le routeur actif.
Pour configurer un routeur en tant que routeur actif, utilisez la commande d’interface standby priority . La plage de priorité HSRP va de 0 à 255.
Préemption HSRP
Par défaut, après être devenu le routeur actif, ce routeur reste le même si un autre routeur associé à une priorité plus élevée est connecté.
Pour imposer un nouveau processus de sélection de routeur HSRP, activez la préemption à l’aide de la commande d’interface standby preempt . La préemption est la capacité d’un routeur HSRP à déclencher un nouveau processus de sélection. Lorsque la préemption est activée, un routeur mis en ligne avec une priorité HSRP plus élevée assume le rôle de routeur actif.
La préemption permet de définir un routeur comme routeur actif uniquement si celui-ci affiche une priorité plus élevée. Un routeur pour lequel la préemption a été activée et qui a une adresse IPv4 plus élevée, mais une priorité identique ne prendra pas la main sur un routeur actif. Consultez la topologie dans la figure.
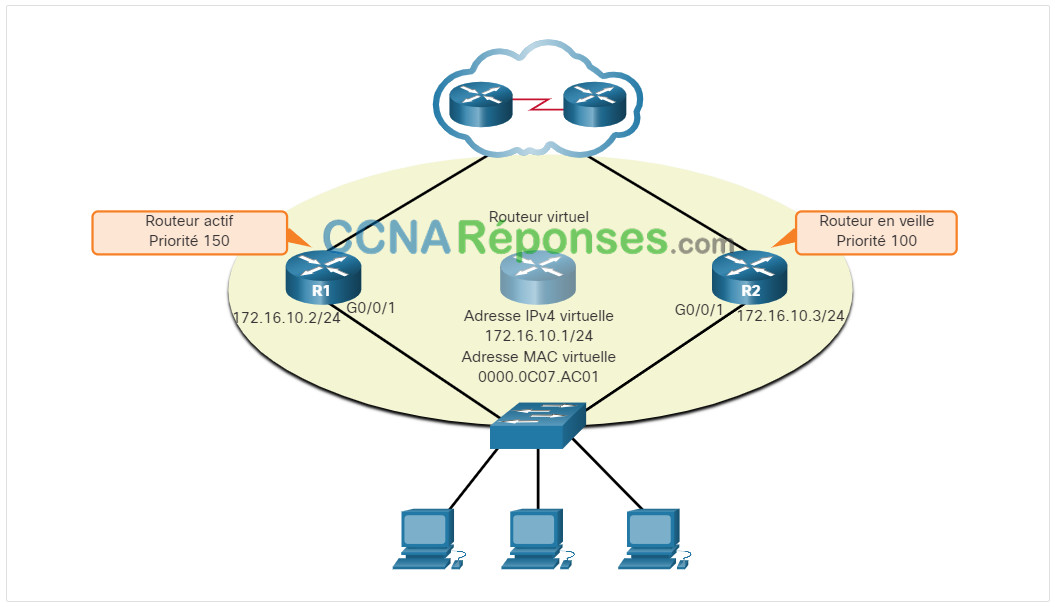
R1 a été configuré avec la priorité HSRP 150 et R2 avec la priorité HSRP par défaut, soit 100. La préemption est activée sur R1. Comme sa priorité est plus élevée, R1 est le routeur actif et R2 le routeur de secours (standby). En raison d’une panne de courant affectant seulement R1, le routeur actif n’est plus disponible et le routeur de secours R2 prend le relais. Une fois l’alimentation rétablie, R1 est de nouveau disponible. Comme la priorité de R1 est plus élevée et que la préemption est activée, il déclenche un nouveau processus de sélection. R1 reprend son rôle de routeur actif et R2 celui du routeur de secours.
Remarque: Lorsque la préemption est désactivée, le premier routeur qui démarre devient le routeur actif si aucun autre routeur n’est disponible pendant le processus de sélection.
9.2.3 Les états et les minuteurs HSRP
Un routeur peut avoir le rôle de routeur HSRP actif, chargé de transférer le trafic du segment ou celui de routeur HSRP passif, en standby et prêt à prendre la main en cas de défaillance du routeur actif. Lorsqu’une interface est configurée avec HSRP ou activée pour la première fois avec une configuration HSRP existante, le routeur envoie et reçoit des paquets « hello » HSRP pour commencer à déterminer son état au sein du groupe HSRP.
Le tableau récapitule les états HSRP :
| États HSRP | Description |
|---|---|
| Initial | cet état initial lorsqu’un changement de configuration a lieu ou une interface devient disponible pour la première fois. |
| Apprendre | Le routeur n’a pas encore appris son adresse IP virtuelle ni reçu de messages Hello du routeur actif. Dans cet état, le routeur est en attente d’un message du routeur actif. |
| Écouter | Le routeur connait son adresse IP virtuelle, mais n’est ni le routeur actif, ni le routeur de secours. Il attend un message de ceux-ci. |
| Parler | Le routeur envoie régulièrement des messages Hello et participe activement à la sélection du routeur actif et/ou du routeur de secours. |
| En veille | Le routeur est candidat pour devenir le prochain routeur actif et envoie régulièrement des messages Hello. |
Par défaut, les routeurs actif et de secours envoient des paquets Hello à l’adresse de multidiffusion du groupe HSRP toutes les 3 secondes. Le routeur de secours (standby) prend la main s’il ne reçoit pas un message Hello du routeur actif après 10 secondes. Vous pouvez diminuer ces délais pour accélérer le basculement ou la préemption. Toutefois, pour éviter une utilisation accrue du processeur et des changements d’état «standby» inutiles, ne définissez pas une valeur inférieure à une seconde pour le minuteur «hello» et à 4 secondes pour le minuteur «hold» (attente).
9.3 Module pratique et questionnaire
9.3.1 Qu’est-ce que j’ai appris dans ce module?
Protocole de redondance au premier saut (FHRP)
En cas de défaillance d’un routeur ou d’une interface de routeur servant de passerelle par défaut, les hôtes configurés avec cette passerelle par défaut sont isolés des réseaux extérieurs. Les protocoles FHRP offrent des passerelles par défaut alternatives dans les réseaux commutés où deux routeurs ou plus sont connectés aux mêmes VLAN. Pour éviter tout risque de point de défaillance unique au niveau de la passerelle par défaut, il est possible d’implémenter un routeur virtuel. Avec un routeur virtuel, plusieurs routeurs sont configurés pour un fonctionnement conjoint, de manière à présenter l’illusion d’un routeur unique au regard des hôtes du LAN. Lorsque le routeur actif est défaillant, le protocole de redondance définit le rôle de routeur actif pour le routeur en veille. Voici la procédure en cas de défaillance du routeur actif:
- Le routeur en veille cesse de voir les messages Hello du routeur de transfert.
- Le routeur en veille assume le rôle du routeur de transfert.
- Étant donné que le nouveau routeur de transfert assume à la fois le rôle de l’adresse IPv4 et celui de l’adresse MAC du routeur virtuel, aucune interruption de service n’est constatée au niveau des périphériques hôtes.
Le PFHRP utilisé dans un environnement de production dépend largement de l’équipement et des besoins du réseau. Voici les options disponibles pour les protocoles FHRP:
- HSRP et HSRP pour IPv6
- VRRPV2 et VRRPV3
- GLBP et GLBP pour IPv6
- IRDP
HSRP
Le Protocole HSRP (Hot Standby Router Protocol) est un protocole FHRP propriétaire de Cisco, conçu pour permettre le basculement transparent d’un périphérique IPv4 au premier saut. Il est utilisé dans un groupe de routeurs pour sélectionner un périphérique actif et un périphérique en veille. Dans un groupe d’interfaces de périphérique, le périphérique actif est celui qui est utilisé pour le routage des paquets; le périphérique en veille est celui qui prend le relais en cas de défaillance du périphérique actif ou lorsque certaines conditions prédéfinies sont réunies. La fonction du routeur en veille HSRP est de surveiller l’état de fonctionnement du groupe HSRP et de prendre rapidement la responsabilité du réacheminement des paquets lorsque le routeur actif est défaillant. Le routeur associé à la priorité HSRP la plus élevée devient le routeur actif. La préemption est la capacité d’un routeur HSRP à déclencher un nouveau processus de sélection. Lorsque la préemption est activée, un routeur mis en ligne avec une priorité HSRP plus élevée assume le rôle de routeur actif. Les états HSRP comprennent initial, apprendre, écouter, parler et en veille.
9.3.3 Packet Tracer – Guide de configuration du HSRP
Remarque: La configuration HSRP n’est pas une compétence requise pour ce module, ce cours ou pour la certification CCNA. Cependant, nous avons pensé que vous pourriez aimer implémenter HSRP dans Packet Tracer. La réalisation de cette activité vous aidera à mieux comprendre le fonctionnement des protocoles FHRP, et plus particulièrement du protocole HSRP.
Dans cette activité Packet Tracer, vous apprendrez comment configurer le protocole HSRP pour fournir des périphériques de passerelle par défaut redondants aux hôtes des réseaux locaux. Après avoir configuré HSRP, vous testez la configuration pour vérifier que les hôtes peuvent utiliser la passerelle par défaut redondante si le périphérique de passerelle actuel devient indisponible.
- Configurer un routeur actif HSRP.
- Configurer un routeur de secours HSRP.
- Vérifier le fonctionnement du protocole HSRP.
9.3.4 Traceur de paquets – Exploration du Data Center
Les Data Centers sont souvent appelés le cerveau d’une organisation qui stocke et analyse des données, assure la communication interne et avec les clients, et fournit les outils nécessaires aux activités de recherche et de développement. Le Data Center doit être construit de manière à pouvoir fournir en toute sécurité et efficacement tout son potentiel, quelle que soit la catastrophe qui se produit. De nombreux systèmes différents entrent dans la construction d’un data center, mais pour cette activité, nous nous intéresserons uniquement aux composants réseau.
La taille des data centers peut aller de quelques serveurs seulement à des centaines, voire des milliers, de serveurs. Quelle que soit la taille, le data center doit être construit de manière extrêmement organisée afin de simplifier la gestion et le dépannage d’un environnement complexe. Une autre caractéristique de conception consiste à rendre le data center plus robuste en utilisant la redondance pour éliminer tout point de défaillance unique. Cela peut impliquer l’ajout de périphériques supplémentaires pour assurer une redondance physique et/ou l’utilisation de technologies telles que les protocoles de redondance de premier saut (FHRP) et l’agrégation de liens pour assurer une redondance logique.
Dans cette activité PTPM (Packet Tracer Physical Mode), la plupart des périphériques des data centers de Toronto et de Seattle sont déjà déployés et configurés. Vous venez d’être embauché pour examiner le déploiement actuel et augmenter la capacité du data center 1 à Toronto.
Remarque: Veuillez patienter. Le chargement de cette activité PTPM peut prendre plusieurs minutes.