14.0 Introduction
14.0.1 Pourquoi devrais-je suivre ce module?
Bienvenue à l’automatisation des réseaux !
Avez-vous configuré votre réseau domestique ? Un réseau de petit bureaux ? Imaginez faire ces tâches pour des dizaines de milliers de terminaux et des milliers de routeurs, commutateurs et points d’accès ! Saviez-vous qu’il existe un logiciel qui automatise ces tâches pour un réseau d’entreprise ? En fait, il existe des logiciels qui peuvent automatiser la conception d’un réseau d’entreprise. Il peut automatiser l’ensemble de la surveillance, des opérations et de la maintenance de votre réseau. Vous êtes intéressé ? Commencer !
14.0.2 Qu’est-ce que je vais apprendre dans ce module?
Titre du module: Automatisation des réseaux
Module objectif: Expliquer comment l’automatisation des réseaux est possible grâce aux RESTful API et les outils de gestion de configuration.
| Titre du rubrique | Objectif du rubrique |
|---|---|
| Aperçu de l’Automatisation | Décrire l’automatisation. |
| Formats de données | Comparer les formats de données JSON, YAML et XML. |
| API | Expliquer comment les API permettent les communications entre ordinateurs. |
| REST | Expliquer comment REST permet les communications entre ordinateurs. |
| Gestion de la configuration | Comparez les outils de gestion de configuration Puppet, Chef, Ansible et SaltStack. |
| IBN et Cisco DNA Center | Expliquer comment Cisco DNA Center permet de mettre en place un réseau intuitif. |
14.1 Aperçu de l’automatisation
14.1.2 L’Augmentation de l’Automatisation
L’automatisation est tout processus autonome, qui réduit et élimine potentiellement le besoin d’intervention humaine.
Auparavant, l’automatisation était réservée au secteur de la fabrication. Les tâches hautement répétitives, telles que l’assemblage d’automobiles, ont été transférées aux machines et la chaîne d’assemblage moderne est née. Les machines excellent à répéter la même tâche sans fatigue et sans les erreurs que les humains sont susceptibles de faire dans ce type de travaux.
Voici quelques avantages de l’automatisation :
- La productivité est donc supérieure, car les machines peuvent fonctionner 24 heures sur 24, sans aucune pause.
- Elles fournissent également un produit plus uniforme.
- L’automatisation permet la collecte d’immenses volumes de données qui peuvent être analysées rapidement afin de fournir des informations qui peuvent orienter un événement ou un processus.
- Les robots sont utilisés dans des conditions dangereuses comme l’exploitation minière, la lutte contre les incendies et le nettoyage des accidents industriels. Cela réduit le risque pour l’homme.
- Dans certaines circonstances, les appareils intelligents peuvent modifier leur comportement pour réduire la consommation d’énergie, poser un diagnostic médical et améliorer la sécurité de conduite automobile.
14.1.3 Appareil Intelligent
Les appareils peuvent-ils penser ? Peuvent-ils apprendre de leur environnement ? Tout dépend de ce que l’on veut dire par « penser ». Une définition possible est la possibilité de connecter une série d’informations ayant un lien entre elles, puis de les exploiter pour modifier un plan d’action.
De nombreux appareils intègrent une technologie intelligente pour aider à régir leur comportement. Cela peut être aussi simple qu’un appareil intelligent réduisant sa consommation d’énergie pendant les périodes de forte demande ou aussi complexe qu’une voiture autonome.
Chaque fois qu’un appareil prend une mesure basée sur une information extérieure, cet appareil est appelé appareil intelligent. De nombreux appareils avec lesquels nous interagissons sont aujourd’hui associés au terme « intelligent ». Cela indique qu’ils ont la faculté de modifier leur comportement en fonction de leur environnement.
Pour que les appareils «réfléchissent», ils doivent être programmés à l’aide d’outils d’automatisation de réseau.

14.2 Formats de données
14.2.2 Le Concept des Formats de Données
Lors du partage de données avec des personnes, les possibilités d’affichage de ces informations sont presque infinies. Par exemple, pensez à la façon dont un restaurant pourrait formater son menu. Il peut s’agir de texte uniquement, d’une liste à points, ou de photos avec légendes, ou simplement de photos. Ce sont toutes des façons différentes dont le restaurant peut formater les données qui composent le menu. Une forme bien conçue est dictée par ce qui rend l’information la plus facile à comprendre pour l’audience. Ce même principe s’applique aux données partagées entre ordinateurs. Un ordinateur doit mettre les données dans un format qu’un autre ordinateur peut comprendre.
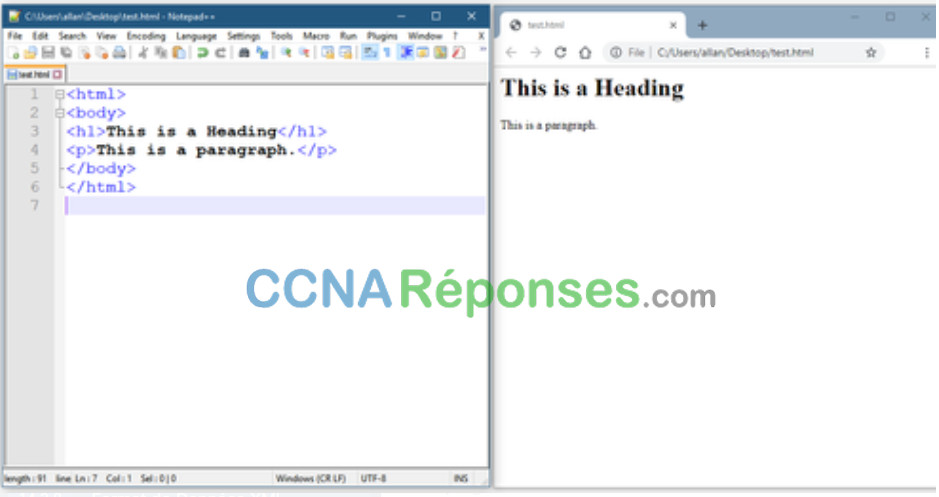
Les formats de données sont simplement un moyen de stocker et d’échanger des données dans un format structuré. Un de ces formats est appelé Hypertext Markup Language (HTML). HTML est un langage de balisage standard pour décrire la structure des pages Web, comme le montre la figure.
Voici quelques formats de données courants utilisés dans de nombreuses applications, notamment l’automatisation du réseau et la programmabilité :
- Notation d’objet JavaScript (JSON)
- Langage de balisage extensible (XML) Extensible Markup Language
- YAML n’est pas un langage de balisage (YAML) Ain’t Markup Language
Le format de données sélectionné dépend du format utilisé par l’application, l’outil ou le script que vous utilisez. De nombreux systèmes pourront prendre en charge plusieurs formats de données, ce qui permet à l’utilisateur de choisir son format préféré.
14.2.3 Règles de Format des Données
Les formats de données ont des règles et une structure similaires à celles que nous avons avec la programmation et les langages écrits. Chaque format de données aura des caractéristiques spécifiques :
- Syntaxe, qui inclut les types de parenthèses utilisés, tels que [ ], ( ), { }, l’utilisation d’espaces blancs ou l’indentation, les guillemets, les virgules, etc.
- Comment les objets sont représentés, tels que les caractères, les chaînes, les listes et les tableaux.
- Comment les paires clé / valeur sont représentées. La clé se trouve généralement sur le côté gauche et identifie ou décrit les données. La valeur à droite correspond aux données elles-mêmes et peut être un caractère, une chaîne, un nombre, une liste ou un autre type de données.
Recherchez sur Internet «open notify ISS location now» pour trouver un site Web qui suit l’emplacement actuel de la Station spatiale internationale. Sur ce site Web, vous pouvez voir comment les formats de données sont utilisés et quelques ressemblances entre eux. Ce site Web comprend un lien pour un simple appel d’API (Application Programming Interface) vers un serveur, qui renvoie la latitude et la longitude actuelles de la station spatiale avec un horodatage UNIX. L’exemple suivant montre les informations renvoyées par le serveur à l’aide de la notation d’objet JavaScript (JSON). Les informations sont affichées dans un format brut. Cela peut rendre difficile la compréhension de la structure des données.
{"message": "success", "timestamp": 1560789216, "iss_position":
{"latitude": "25.9990", "longitude": "-132.6992"}}
Effectuez une recherche sur Internet pour trouver l’extension de navigateur «JSONView» ou toute extension qui vous permettra d’afficher JSON dans un format plus lisible. Les objets de données sont affichés par paires clé / valeur. La sortie suivante montre cette même sortie à l’aide de JSONView. Les paires clé / valeur sont beaucoup plus faciles à interpréter. Dans l’exemple ci-dessous, vous pouvez voir la clé latitude et sa valeur 25.9990.
{
"message": "success",
"timestamp": 1560789260,
"iss_position": {
"latitude": "25.9990",
"longitude": "-132.6992"
}
}
Remarque: JSONView peut supprimer les guillemets de la clé. Des guillemets sont demandés lors du codage des paires clé / valeur JSON.
14.2.4 Comparer les Formats de Données
Pour voir ces mêmes données au format XML ou YAML, recherchez sur Internet un outil de conversion JSON. À ce stade, il n’est pas important de comprendre les détails de chaque format de données, mais notez comment chaque format de données utilise la syntaxe et comment les paires clé / valeur sont représentées.
Format JSON
{
"message": "success",
"timestamp": 1560789260,
"iss_position": {
"latitude": "25.9990",
"longitude": "-132.6992"
}
}
Format YAML
message: success
timestamp: 1560789260
iss_position:
latitude: '25.9990'
longitude: '-132.6992'
Format XML
<?xml version="1.0" encoding="UTF-8" ?>
<root>
<message>success</message>
<timestamp>1560789260</timestamp>
<iss_position>
<latitude>25.9990</latitude>
<longitude>-132.6992</longitude>
</iss_position>
</root>
14.2.5 Format de Données JSON
JSON est un format de données lisible par l’humain utilisé par les applications pour stocker, transférer et lire des données. JSON est un format très populaire utilisé par les services Web et les API pour fournir des données publiques. Ceci est dû au fait qu’il est facile à analyser et peut être utilisé avec la plupart des langages de programmation modernes, y compris Python.
La sortie suivante montre un exemple de sortie partielle d’IOS d’une commande de show interface GigabitEthernet0/0/0 sur un routeur.
Sortie du routeur IOS
GigabitEthernet0/0/0 is up, line protocol is up (connected) Description: Wide Area Network Internet address is 172.16.0.2/24
Ces mêmes informations peuvent être représentées au format JSON. Notez que chaque objet (chaque paire clé / valeur) est une donnée différente sur l’interface, y compris son nom, une description et si l’interface est activée.
Sortie JSON
{
"ietf-interfaces:interface": {
"name": "GigabitEthernet0/0/0",
"description": "Wide Area Network",
"enabled": true,
"ietf-ip:ipv4": {
"address": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
}
]
}
}
}
14.2.6 Règles de Syntaxe JSON
Ce sont quelques-unes des caractéristiques de JSON:
- Il utilise une structure hiérarchique et contient des valeurs imbriquées.
- Il utilise des accolades { } pour contenir des objets et des crochets \ [ ] contiennent des tableaux.
- Ses données sont écrites sous forme de paires clé / valeur.
Dans JSON, les données appelées objet sont une ou plusieurs paires clé / valeur entre accolades { }. La syntaxe d’un objet JSON comprend:
- Les clés doivent être des chaînes entre guillemets » « .
- Les valeurs doivent être un type de données JSON valide (chaîne, nombre, tableau, booléen, nul ou autre objet).
- Les clés et les valeurs sont séparées par deux points.
- Plusieurs paires clé / valeur dans un objet sont séparées par des virgules.
- L’espace blanc n’est pas significatif.
Parfois, une clé peut contenir plusieurs valeurs. C’est ce qu’on appelle un tableau. Un tableau en JSON est une liste ordonnée de valeurs. Les caractéristiques des tableaux dans JSON incluent:
- La clé suivie de deux-points et d’une liste de valeurs entre crochets \ [].
- Un tableau est une liste ordonnée de valeurs.
- Le tableau peut contenir plusieurs types de valeurs, y compris une chaîne, un nombre, un booléen, un objet ou un autre tableau à l’intérieur du tableau.
- Chaque valeur du tableau est séparée par une virgule.
Par exemple, une liste d’adresses IPv4 peut ressembler à la sortie suivante. La clé est «adresses». Chaque élément de la liste est un objet distinct, séparé par des accolades { }. Les objets sont deux paires clé / valeur: une adresse IPv4 («ip») et un masque de sous-réseau («netmask») séparés par une virgule. Le tableau d’objets dans la liste est également séparé par une virgule après l’accolade fermante pour chaque objet.
Liste JSON des Adresses IPv4
{
"addresses": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.3",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.4",
"netmask": "255.255.255.0"
}
]
}
14.2.7 Format de données YAML
YAML est un autre type de format de données lisibles par l’homme utilisé par les applications pour stocker, transférer et lire des données. Certaines des caractéristiques de YAML comprennent:
- C’est comme JSON et est considéré comme un surensemble de JSON.
- Il a un format minimaliste qui facilite la lecture et l’écriture.
- Il utilise l’indentation pour définir sa structure, sans utiliser de crochets ou de virgules.
Par exemple, regardez cette sortie JSON pour une interface Gigabit Ethernet 2.
JSON pour GigabitEthernet2
{
"ietf-interfaces:interface": {
"name": "GigabitEthernet2",
"description": "Wide Area Network",
"enabled": true,
"ietf-ip:ipv4": {
"address": [
{
"ip": "172.16.0.2",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.3",
"netmask": "255.255.255.0"
},
{
"ip": "172.16.0.4",
"netmask": "255.255.255.0"
}
]
}
}
}
Ces mêmes données au format YAML sont plus faciles à lire. Similaire à JSON, un objet YAML est une ou plusieurs paires valeur / clé. Les paires valeur / clé sont séparées par deux points sans utiliser des guillemets. En YAML, un trait d’union est utilisé pour séparer chaque élément d’une liste. Ceci est indiqué pour les trois adresses IPv4 dans la sortie suivante.
JSON pour GigabitEthernet2
ietf-interfaces:interface:
name: GigabitEthernet2
description: Wide Area Network
enabled: true
ietf-ip:ipv4:
address:
- ip: 172.16.0.2
netmask: 255.255.255.0
- ip: 172.16.0.3
netmask: 255.255.255.0
- ip: 172.16.0.4
netmask: 255.255.255.0
14.2.8 Format de Données XML
XML est un autre type de format de données lisibles par l’homme utilisé pour stocker, transférer et lire des données par des applications. Certaines des caractéristiques de XML incluent:
- C’est comme HTML, qui est le langage de balisage normalisé pour la création de pages Web et d’applications Web.
- Il est auto-descriptif. Il enferme les données dans un ensemble de balises: <tag>data</tag>
- Contrairement à HTML, XML n’utilise ni balises ni structure de document prédéfinies.
Les objets XML sont une ou plusieurs paires clé / valeur, avec la balise de début utilisée comme nom de la clé: <key>value</key>
La sortie suivante montre les mêmes données pour GigabitEthernet2 formatées en tant que structure de données XML. Remarquez comment les valeurs sont incluses dans les balises d’objet. Dans cet exemple, chaque paire clé / valeur se trouve sur une ligne distincte et certaines lignes sont en retrait.’ Ceci n’est pas obligatoire mais est fait pour la lisibilité. La liste utilise des exemples répétées de <tag></tag> pour chaque élément de la liste. Les éléments de ces exemples répétés représentent une ou plusieurs paires clé / valeur.
XML pour GigabitEthernet2
<?xml version="1.0" encoding="UTF-8" ?>
<ietf-interfaces:interface>
<name>GigabitEthernet2</name>
<description>Wide Area Network</description>
<enabled>true</enabled>
<ietf-ip:ipv4>
<address>
<ip>172.16.0.2</ip>
<netmask>255.255.255.0</netmask>
</address>
<address>
<ip>172.16.0.3</ip>
<netmask>255.255.255.0</netmask>
</address>
<address>
<ip>172.16.0.4</ip>
<netmask>255.255.255.0</netmask>
</address>
</ietf-ip:ipv4>
</ietf-interfaces:interface>
14.3 API
14.3.2 Le Concept API
Les API se trouvent presque partout. Amazon Web Services, Facebook et les appareils domotiques tels que les thermostats, les réfrigérateurs et les systèmes d’éclairage sans fil utilisent tous des API. Ils sont également utilisés pour construire une automatisation de réseau programmable.
Une API est un logiciel qui permet à d’autres applications d’accéder à ses données ou services. Il s’agit d’un ensemble de règles décrivant comment une application peut interagir avec une autre et les instructions permettant à l’interaction de se produire. L’utilisateur envoie une demande d’API à un serveur demandant des informations spécifiques et reçoit une réponse d’API en retour du serveur avec les informations demandées.
Une API est similaire à un serveur dans un restaurant, comme le montre la figure suivante. Un client dans un restaurant voudrait que des plats soient livrés à table. La nourriture est dans la cuisine où elle est cuite et préparée. Le serveur est le messager, semblable à une API. Le serveur (l’API) est la personne qui prend la commande du client (la demande) et dit à la cuisine quoi faire. Lorsque la nourriture est prête, le serveur remettra alors la nourriture (la réponse) au client.
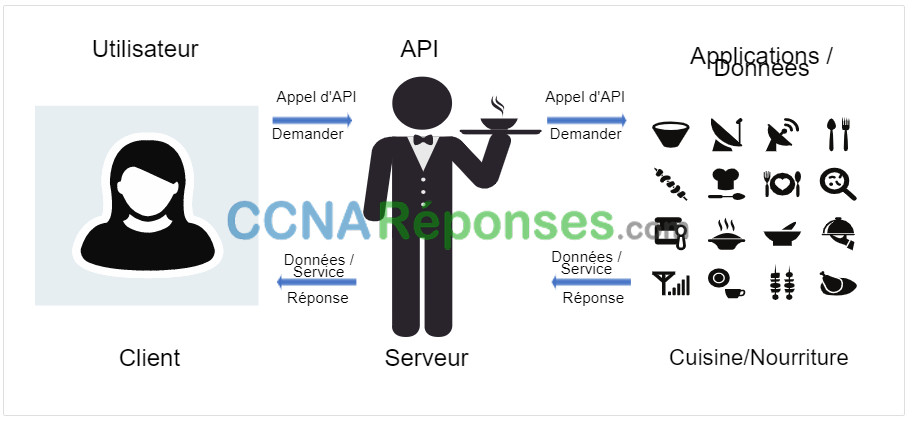
Précédemment, vous aviez vu une demande d’API à un serveur qui renvoyait la latitude et la longitude actuelles de la Station spatiale internationale. Il s’agit d’une API qu’Open Notify fournit pour accéder des données à partir d’un navigateur Web de la National Aeronautics and Space Administration (NASA).
14.3.3 Un Exemple d’API
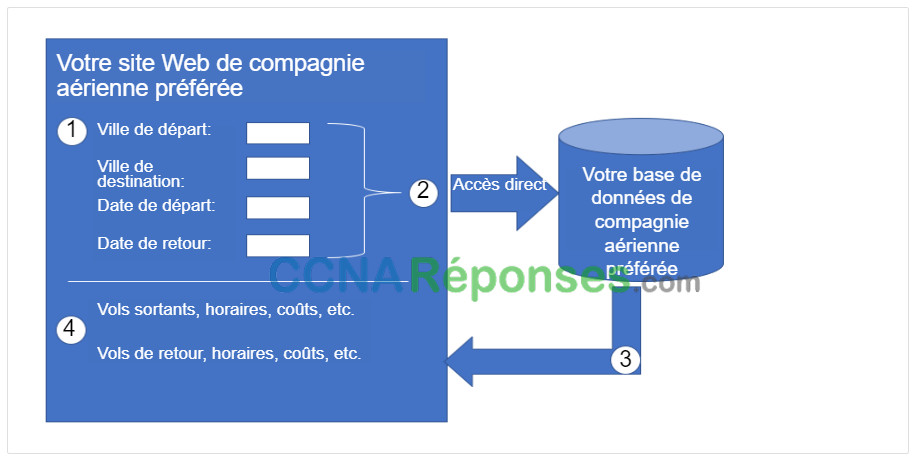
Pour vraiment comprendre comment les API peuvent être utilisées pour fournir des données et des services, nous examinerons deux options pour faire des réservations de compagnies aériennes. La première option utilise le site Web d’une compagnie aérienne spécifique, comme le montre la figure. En utilisant le site Web de la compagnie aérienne, l’utilisateur entre les informations pour effectuer une demande de réservation. Le site Web interagit directement avec la propre base de données de la compagnie aérienne et fournit à l’utilisateur des informations correspondant à sa demande.
Au lieu d’utiliser un site Web individuel de compagnie aérienne qui a un accès direct à ses propres informations, il existe une deuxième option. Les utilisateurs peuvent utiliser un site de voyage pour accéder à ces mêmes informations, non seulement d’une compagnie aérienne spécifique mais d’une variété de compagnies aériennes. Dans ce cas, l’utilisateur entre dans des informations de réservation similaires. Le site Web du service de voyage interagit avec les différentes bases de données des compagnies aériennes à l’aide des API fournies par chaque compagnie aérienne. Le service de voyage utilise chaque API de compagnie aérienne pour demander des informations à cette compagnie aérienne spécifique, puis il affiche les informations de toutes les compagnies aériennes sur sa page Web, comme indiqué dans la figure.
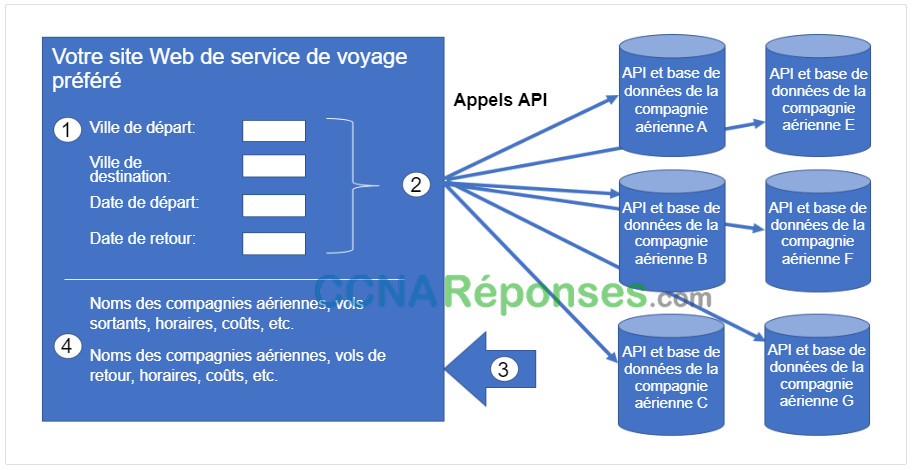
L’API agit comme une sorte de messager entre l’application de requête et l’application sur le serveur qui fournit les données ou le service. Le message de l’application de requête au serveur sur lequel résident les données est appelé appel API.
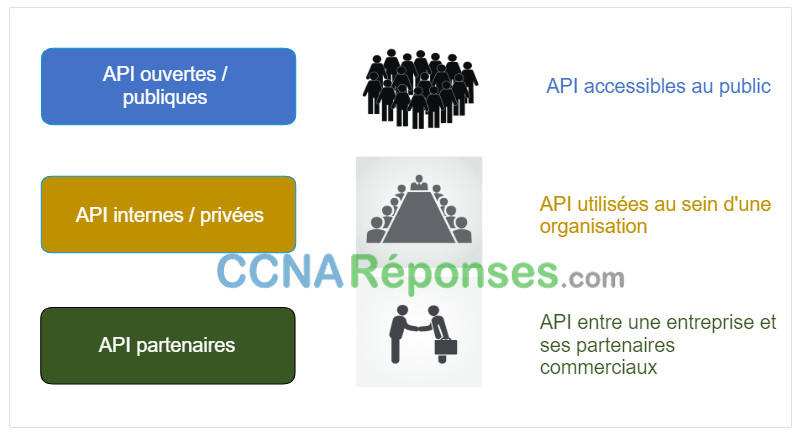
14.3.4 API Ouvertes, Internes et Partenaires
Une considération importante lors du développement d’une API est la distinction entre les API ouvertes, internes et partenaires:
- API ouvertes ou API publiques – Ces API sont accessibles au public et peuvent être utilisées sans aucune restriction. L’API de la Station spatiale internationale est un exemple d’API publique. Car ces API sont publiques, de nombreux fournisseurs d’API, tels que Google Maps, exigent que l’utilisateur obtienne une clé ou un jeton gratuit avant d’utiliser l’API. Cela permet de contrôler le nombre de demandes d’API qu’ils reçoivent et traitent. Recherchez sur internet une liste d’API publiques.
- API internes ou privées – Ce sont des API qui sont utilisées par une organisation ou une entreprise pour accéder aux données et services à usage interne uniquement. Un exemple d’API interne permet aux vendeurs autorisés d’accéder aux données de vente internes sur leurs périphériques mobiles.
- API partenaires – Il s’agit d’API utilisées entre une entreprise et ses partenaires commerciaux ou contracteurs pour faciliter les échanges entre eux. Le partenaire commercial doit disposer d’une licence ou d’une autre forme d’autorisation pour utiliser l’API. Un service de voyage utilisant l’API d’une compagnie aérienne est un exemple d’API partenaire.
14.3.5 Types d’API de Service Web
Un service Web est un service disponible sur internet via le World Wide Web. Il existe quatre types d’API de service Web:
- Protocole d’accès aux objets simples (SOAP)
- Transfert d’état représentatif (REST)
- Langage de balisage extensible-Appel de procédure à distance (XML-RPC)
- JavaScript notation d’objet-Appel de procédure à distance(JSON-RPC)
| Caractéristique | SOAP | REST | XML-RPC | JSON-RPC |
|---|---|---|---|---|
| Format de données | XML | JSON, XML, YAML et autres | XML | JSON |
| Première publication | 1998 | 2000 | 1998 | 2005 |
| Forces | Bien établi | Formatage flexible et le plus largement utilisé | Bien établi, simplicité | Simplicité |
SOAP est un protocole de messagerie pour l’échange d’informations structurées XML, le plus souvent via HTTP ou SMTP (Simple Mail Transfer Protocol). Conçues par Microsoft en 1998, les API SOAP sont considérées comme lentes à analyser, complexes et rigides.
Cela a conduit au développement d’un cadre API REST plus simple qui ne nécessite pas XML. REST utilise HTTP, est moins détaillé et c’est plus facile à utiliser que SOAP. REST fait référence au style d’architecture logicielle et est devenu populaire en raison de ses performances, de son évolutivité, de sa simplicité et de sa fiabilité.
REST est l’API de service Web la plus utilisée, représentant plus de 80% de tous les types d’API utilisés. REST sera discuter plus en détail dans ce module.
RPC est lorsqu’un système demande qu’un autre système exécute des codes et renvoie les informations. Cela se fait sans avoir à comprendre les détails du réseau. Cela fonctionne un peu comme une API REST mais il existe des différences concernant le formatage et la flexibilité. XML-RPC est un protocole développé avant SOAP, et évolué plus tard vers ce qui est devenu SOAP. JSON-RPC est un protocole très simple et similaire à XML-RPC.
14.4 REST
14.4.2 API RESTful
Les navigateurs Web utilisent HTTP ou HTTPS pour demander (GET) une page Web. S’ils sont correctement demandés (code d’état HTTP 200), les serveurs Web répondent aux demandes GET avec une page Web codée HTML, comme illustré dans la figure.
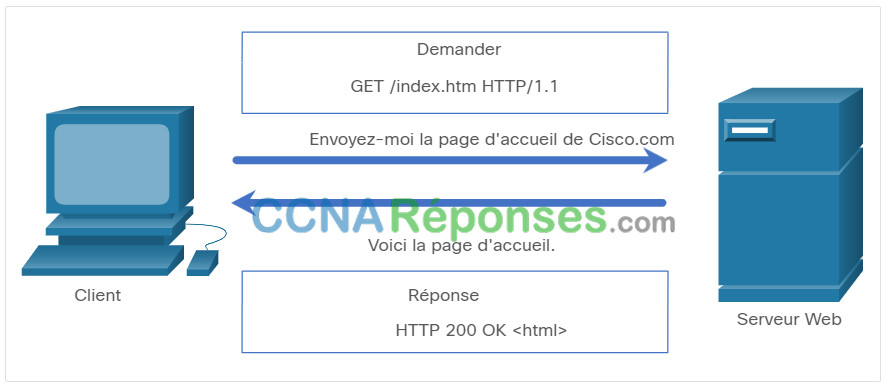
REST est un style architectural pour la conception d’applications de service Web. Il fait référence à un style d’architecture Web qui possède de nombreuses caractéristiques sous-jacentes et régit le comportement des clients et des serveurs. En termes simples, une API REST est une API qui fonctionne au-dessus du protocole HTTP. Il définit un ensemble de fonctions que les développeurs peuvent utiliser pour effectuer des requêtes et recevoir des réponses via le protocole HTTP tel que GET et POST.
La conformité aux contraintes de l’architecture REST est généralement appelée «RESTful». Une API peut être considérée comme «RESTful» si elle possède les fonctionnalités suivantes:
- Client / serveur – Le client gère l’extrémité avant et le serveur gère l’extrémité arrière. L’un ou l’autre peut être remplacé indépendamment de l’autre.
- Apatride – Aucune donnée client n’est stockée sur le serveur entre les requêtes. L’état de session est stocké sur le client.
- Antémémorisable – Les clients peuvent mettre en cache les réponses pour améliorer les performances.
14.4.3 Implémentation RESTful
Un service Web RESTful est implémenté à l’aide de HTTP. Il s’agit d’une collection de ressources avec quatre aspects définis:
- L’identificateur de ressource uniforme de base (URI) pour le service Web, tel que http://example.com/resources.
- Format de données pris en charge par le service Web. Il s’agit souvent de JSON, YAML ou XML, mais il peut s’agir de tout autre format de données qui constitue une norme hypertexte valide.
- Ensemble d’opérations prises en charge par le service Web à l’aide de méthodes HTTP.
- L’API doit être basée sur l’hypertexte.
Les API RESTful utilisent des méthodes HTTP courantes, notamment POST, GET, PUT, PATCH et DELETE. Comme indiqué dans le tableau suivant, ceux-ci correspondent aux opérations RESTful: créer, lire, mettre à jour et supprimer (ou CRUD).
| Méthode HTTP | Opération RESTful |
|---|---|
| POST | Créer |
| GET | Lire |
| PUT/PATCH | Mettre à jour |
| DELETE | Supprimer |
Dans la figure, la demande HTTP demande des données au format JSON. Si la demande est correctement construite conformément à la documentation de l’API, le serveur répondra avec des données JSON. Ces données JSON peuvent être utilisées par l’application Web d’un client pour afficher les données. Par exemple, une application de cartographie du smartphone montre l’emplacement de San Jose, en Californie.
14.4.4 URI, URN, et URL
Les ressources Web et les services Web tels que les API RESTful sont identifiés à l’aide d’un URI. Un URI est une chaîne de caractères qui identifie une ressource de réseau spécifique. Comme le montre la figure, un URI a deux spécialisations:
- Nom de ressource uniforme (URN) – identifie uniquement l’espace de noms de la ressource (page Web, document, image, etc.) sans référence au protocole.
- Localisateur de ressources uniforme (URL) – définit l’emplacement réseau d’une ressource spécifique sur le réseau. Les URL HTTP ou HTTPS sont généralement utilisées avec les navigateurs Web. D’autres protocoles tels que FTP, SFTP, SSH et autres peuvent utiliser une URL. Une URL utilisant SFTP peut ressembler à: sftp: //sftp.example.com.
Ce sont les parties d’un URI, comme le montre la figure:
- Protocole/schéma – HTTPS ou d’autres protocoles tels que FTP, SFTP, mailto et NNTP
- Nom d’hôte – www.example.com
- Chemin et nom de fichier – /author/book.html
- Fragment – #page155
Parts of a URI

14.4.5 Anatomie d’une Demande RESTful
Dans un service Web RESTful, une demande adressée à l’URI d’une ressource provoquera une réponse. La réponse sera une charge utile généralement formatée en JSON, mais pourrait être HTML, XML ou un autre format. La figure montre l’URI de l’API directions MapQuest. La demande d’API est pour les directions de San Jose, Californie, à Monterey, Californie.
Parties d’une Demande d’API

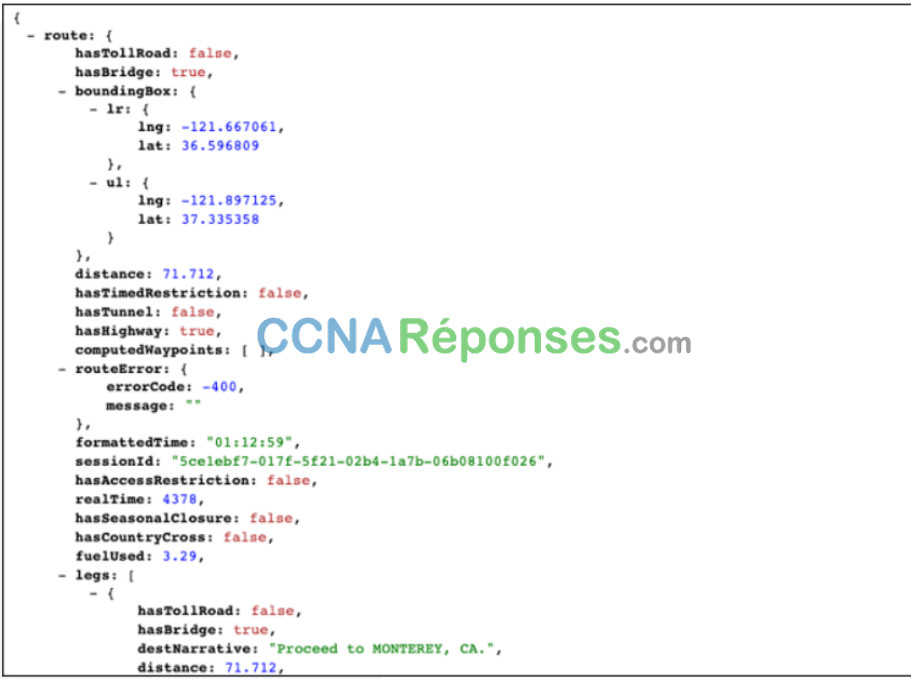
La figure montre une partie de la réponse de l’API. Dans cet exemple, il s’agit des directions MapQuest de San Jose à Monterey au format JSON.
Charge Utile JSON Partielle Reçue d’une Demande d’API

Ce sont les différentes parties de la demande d’API:
Serveur API – Il s’agit de l’URL du serveur qui répond aux demandes REST. Dans cet exemple, il s’agit du serveur API MapQuest.
Ressources – Spécifie l’API qui est demandée. Dans cet exemple, il s’agit de l’API directions MapQuest.
Requête – Spécifie le format de données et les informations que le client demande au service API. Les requêtes peuvent inclure:
- Format – Il s’agit généralement de JSON mais peut être YAML ou XML. Dans cet exemple, JSON est demandé.
- Clé – La clé est pour l’autorisation, si nécessaire. MapQuest nécessite une clé pour son API de directions. Dans l’URI ci-dessus, vous devez remplacer «KEY» par une clé valide pour soumettre une demande valide.
- Paramètres – Les paramètres sont utilisés pour envoyer des informations relatives à la demande. Dans cet exemple, les paramètres de requête incluent des informations sur les directions dont l’API a besoin pour qu’elle sache les directions pour retourner: « from = San + Jose, Ca » et « to = Monterey, Ca ».
De nombreuses API RESTful, y compris les API publiques, nécessitent une clé. La clé est utilisée pour identifier la source de la demande. Voici quelques raisons pour lesquelles un fournisseur d’API peut nécessiter une clé:
- Pour authentifier la source pour vous assurer qu’elle est autorisée à utiliser l’API.
- Pour limiter le nombre de personnes utilisant l’API.
- Pour limiter le nombre de demandes par utilisateur.
- Pour mieux capturer et suivre les données demandées par les utilisateurs.
- Pour recueillir des informations sur les personnes utilisant l’API.
Remarque: Si vous souhaitez utiliser l’API MapQuest, l’API nécessite une clé. Recherchez l’URL sur internet pour obtenir une clé MapQuest. Utilisez les paramètres de recherche: developer.mapquest. Vous pouvez également rechercher sur Internet l’URL actuelle qui décrit la politique de confidentialité de MapQuest.
14.4.6 Applications API RESTful
De nombreux sites Web et applications utilisent des API pour accéder aux informations et fournir des services à leurs clients. Par exemple, lors de l’utilisation d’un site Web de service de voyage, le service de voyage utilise l’API de diverses compagnies aériennes pour fournir à l’utilisateur des informations sur la compagnie aérienne, l’hôtel et d’autres informations.
Certaines demandes d’API RESTful peuvent être effectuées en tapant l’URI à partir d’un navigateur Web. Dans cet exemple, il s’agit de l’API directions MapQuest. Une demande d’API RESTful peut également être effectuée par d’autres moyens.
Cliquez sur chaque scénario d’application API ci-dessous pour plus d’informations.
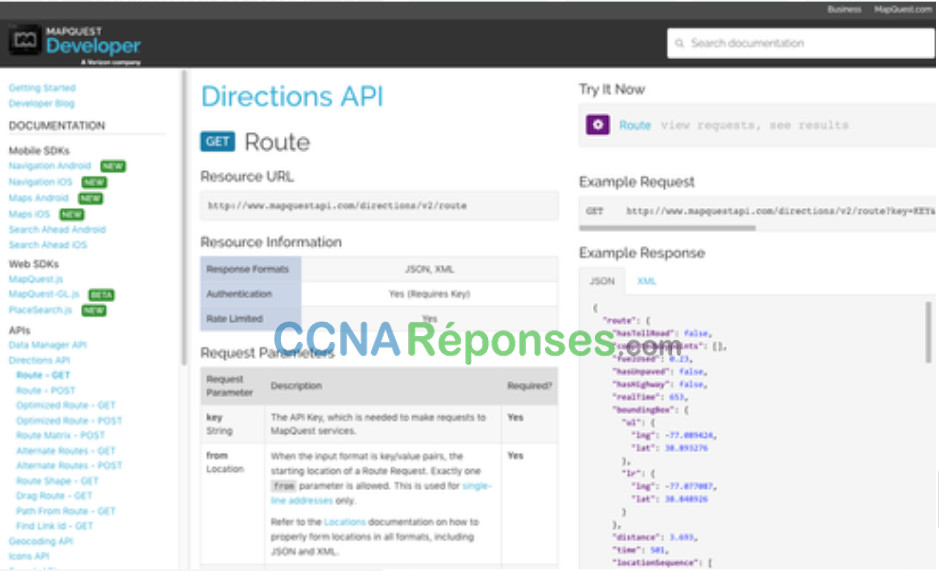
Les développeurs gèrent souvent des sites Web qui contiennent des informations sur l'API, des informations sur les paramètres et des exemples d'utilisation. Ces sites peuvent également permettre à l'utilisateur d'effectuer la demande d'API dans la page Web du développeur en entrant les paramètres et d'autres informations. La figure suivante montre un exemple de la page Web de l'API MapQuest Directions.
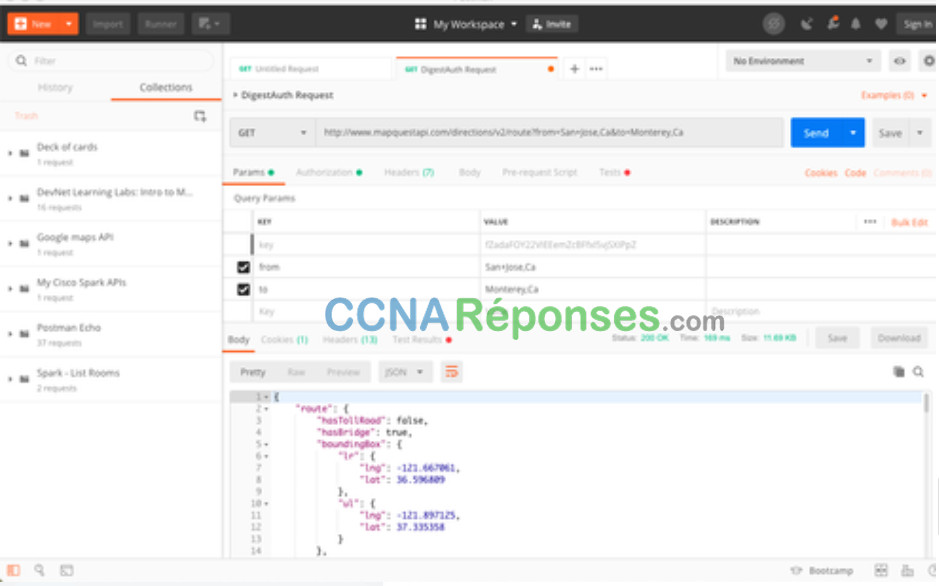
Postman est une application pour tester et utiliser les API REST. Il est disponible sous forme d'application de navigateur ou d'installation autonome. Il contient tout ce qui est nécessaire pour construire et envoyer des demandes d'API REST, y compris la saisie des paramètres de requête et des clés. Postman vous permet de collecter et d'enregistrer les appels d'API fréquemment utilisés dans l'historique ou en tant que collections. Postman est un excellent outil pour apprendre à construire des demandes d'API et pour analyser les données renvoyées par une API. La figure suivante montre un exemple d'utilisation de l'API MapQuest avec Postman.
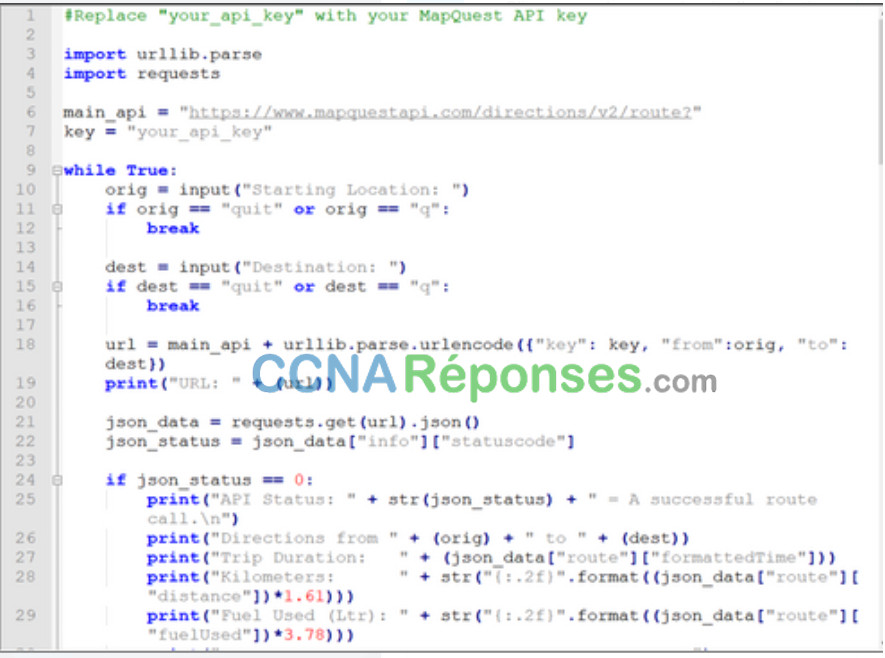
Les API peuvent également être appelées à partir d'un programme Python. Cela permet une automatisation, une personnalisation et une intégration d'applications possibles de l'API. La figure suivante montre un exemple d'une partie d'un programme Python utilisée pour soumettre des demandes à l'API MapQuest.
À l'aide de protocoles tels que NETCONF (NET CONFiguration) et RESTCONF, les systèmes d'exploitation de réseau commencent à fournir une méthode alternative pour la configuration, la surveillance et la gestion. Par exemple, la sortie suivante peut être la réponse d'ouverture d'un routeur après que l'utilisateur a établi une session NETCONF sur la ligne de commande. Cependant, travailler sur la ligne de commande n'automatise pas le réseau. À la place, un administrateur réseau peut utiliser des scripts Python ou d'autres outils d'automatisation, comme Cisco DNA Center, pour interagir par programme avec le routeur.
$ ssh [email protected] -p 830 -s netconf [email protected]'s password: <hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <capabilities> <capability>urn:ietf:params:netconf:base:1.1</capability> <capability>urn:ietf:params:netconf:capability:candidate:1.0</capability> <capability>urn:ietf:params:xml:ns:yang:ietf-netconf-monitoring</capability> <capability>urn:ietf:params:xml:ns:yang:ietf-interfaces</capability> [sortie omise et modifiée pour plus de clarté] </capabilities> <session-id>19150</session-id></hello>
14.5 Outils de Gestion de La Configuration
14.5.2 Configuration Traditionnelle des Réseaux
Les périphériques réseau tels que les routeurs, les commutateurs et les pare-feu sont traditionnellement configurés par un administrateur de réseau à l’aide de la CLI, comme illustré dans la figure. Chaque fois qu’il y a un changement ou une nouvelle fonctionnalité, les commandes de configuration nécessaires doivent être saisies manuellement sur tous les appareils appropriés. Dans de nombreux cas, cela prend non seulement du temps, mais peut également être sujet à des erreurs. Cela devient un problème majeur sur les grands réseaux ou avec des configurations plus complexes.

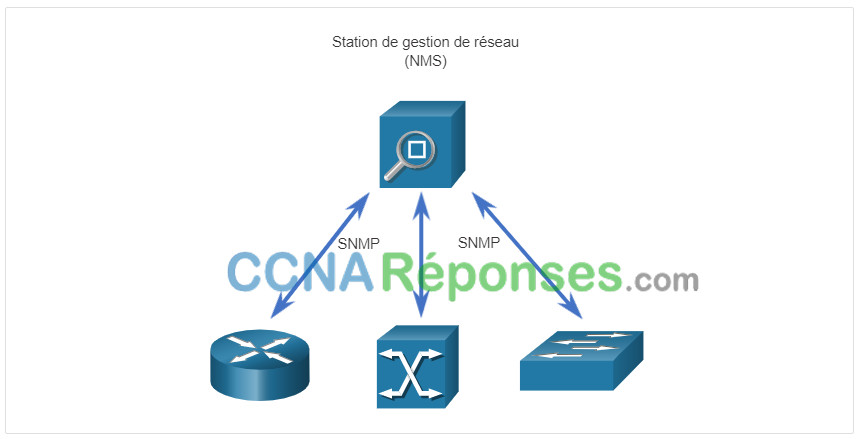
Le protocole SNMP (Simple Network Management Protocol) a été développé pour permettre aux administrateurs de gérer les nœuds, tels que les serveurs, les postes de travail, les routeurs, les commutateurs ainsi que les appliances de sécurité, sur un réseau IP. À l’aide d’une station de gestion de réseau (NMS), illustrée dans la figure suivante, SNMP permet aux administrateurs de réseau de surveiller et de gérer les performances du réseau, de rechercher et de résoudre les problèmes de réseau et d’effectuer des requêtes de statistiques. SNMP fonctionne assez bien pour la surveillance des périphériques. Cependant, il n’est généralement pas utilisé pour la configuration en raison de problèmes de sécurité et de difficultés de mise en œuvre. Bien que SNMP soit largement disponible, il ne peut pas servir d’outil d’automatisation pour les réseaux d’aujourd’hui.
Vous pouvez également utiliser des API pour automatiser le déploiement et la gestion des ressources des réseaux. Au lieu que l’administrateur de réseau configure manuellement les ports, les listes d’accès, la qualité de service (QoS) et les politiques d’équilibrage de charge, ils peuvent utiliser des outils pour automatiser les configurations. Ces outils se connectent aux API du réseau pour automatiser les tâches de provisionnement du réseau de routine, permettant à l’administrateur de sélectionner et de déployer les services du réseau dont ils ont besoin. Cela peut réduire considérablement de nombreuses tâches répétitives et banales pour libérer du temps aux administrateurs réseau pour travailler sur des choses plus importantes.
14.5.3 Automatisation des réseaux
Nous nous éloignons rapidement d’un monde où un administrateur réseau gère quelques dizaines de périphériques réseau, vers un monde où ils déploient et gèrent des centaines, des milliers, voire des dizaines de milliers de périphériques réseau complexes (physiques et virtuels) à l’aide de Logiciel. Cette transformation se propage rapidement depuis ses débuts dans le centre de données, à tous les endroits du réseau. Il existe de nouvelles méthodes différentes pour les opérateurs de réseau pour surveiller, gérer et configurer automatiquement le réseau. Comme le montre la figure, ceux-ci incluent des protocoles et des technologies telles que REST, Ansible, Puppet, Chef, Python, JSON, XML, etc.
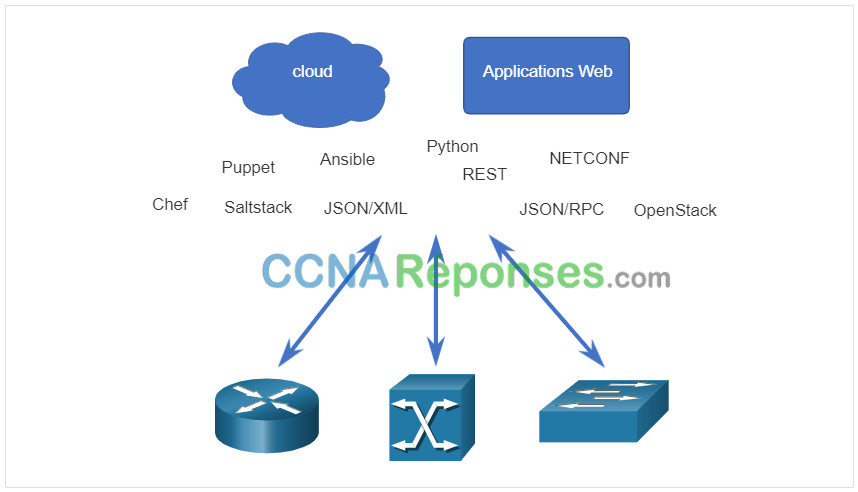
14.5.4 Outils de Gestion de La Configuration
Les outils de gestion de la configuration utilisent les demandes d’API RESTful pour automatiser les tâches et peuvent évoluer sur des milliers de périphériques. Les outils de gestion de la configuration conservent les caractéristiques d’un système ou d’un réseau pour plus de cohérence. Voici quelques caractéristiques du réseau que les administrateurs bénéficient de l’automatisation:
- Logiciel et contrôle de version
- Attributs de périphérique tels que les noms, l’adressage et la sécurité
- Configurations de protocole
- Configuration des listes de contrôle d’accès
Les outils de gestion de la configuration incluent généralement l’automatisation et l’orchestration. L’automatisation est lorsqu’un outil exécute automatiquement une tâche sur un système. Cela peut être la configuration d’une interface ou le déploiement d’un VLAN. L’orchestration est le processus de la manière dont toutes ces activités automatisées doivent se produire, telles que l’ordre dans lequel elles doivent être effectuées, ce qui doit être achevé avant qu’une autre tâche ne commence, etc. L’orchestration est l’organisation des tâches automatisées qui aboutit dans un processus de coordonnées ou flux de travail.
Plusieurs outils sont disponibles pour faciliter la gestion de la configuration:
- Ansible
- Chef
- Puppet
- SaltStack

L’objectif de tous ces outils est de réduire la complexité et le temps nécessaires à la configuration et à la maintenance d’une infrastructure de réseau à grande échelle avec des centaines, voire des milliers d’appareils. Ces mêmes outils peuvent également bénéficier à des réseaux plus petits.
14.5.5 Comparer Ansible, Chef, Puppet et SaltStack
Ansible, Chef, Puppet et SaltStack sont tous livrés avec la documentation de l’API pour configurer les demandes d’API RESTful. Tous prennent en charge JSON et YAML ainsi que d’autres formats de données. Le tableau suivant présente un résumé d’une comparaison des caractéristiques principales des outils de gestion de configuration Ansible, Puppet, Chef et SaltStack.
| Caractéristique | Ansible | Chef | Puppet | SaltStack |
|---|---|---|---|---|
| Quel langage de programmation? | Python + YAML | Ruby | Ruby | Python |
| Avec ou sans agent? | Sans agent | Approche reposant sur un agent | Prend en charge les deux | Prend en charge les deux |
| Comment les périphériques sont-ils gérés? | Tout périphérique peut être “controller” | Chef Master | Puppet Master | Salt Master |
| Qu’est-ce qui est créé par l’outil? | Playbook | Cookbook | Manifest | Pillar |
Quel langage de programmation? – Ansible et SaltStack sont tous deux construits sur Python tandis que Puppet et Chef sont construits sur Ruby. Semblable à Python, Ruby est un langage de programmation source ouverte qui est multiplateforme. Cependant, Ruby est généralement considéré comme un langage plus difficile à apprendre que Python.
Avec ou sans agent? – La gestion de la configuration est basée sur un agent ou sans agent. La gestion de la configuration basée sur l’agent est «basée sur l’extraction», ce qui signifie que l’agent sur le périphérique géré se connecte périodiquement au maître pour ses informations de configuration. Les modifications sont effectuées sur le maître puis abaissées et exécutées par l’appareil. La gestion de la configuration sans agent est basée sur la distribution de données du serveur « push-based ». Un script de configuration est exécuté sur le maître. Le maître se connecte au périphérique et exécute les tâches du script. Sur les quatre outils de configuration du tableau, Ansible est le seul sans agent.
Comment les périphériques sont-ils gérés? – Cela réside dans un périphérique appelé Master in Puppet, Chef et SaltStack. Cependant, comme Ansible est sans agent, n’importe quel ordinateur peut être le contrôleur.
Qu’est-ce qui est créé par l’outil? – Les administrateurs des réseaux utilisent des outils de gestion de configuration pour créer un ensemble d’instructions à exécuter. Chaque outil a son propre nom pour ces instructions: Playbook, Cookbook, Manifest et Pillar. Aussi que La spécification d’une politique ou d’une configuration à appliquer aux périphériques. Chaque type de périphérique peut avoir sa propre politique. Par exemple, tous les serveurs Linux peuvent bénéficier de la même configuration de base et de la même politique de sécurité.
14.6 IBN et Cisco DNA Center
14.6.2 Présentation de la mise en réseau basée sur l’intention
IBN est le modèle industriel émergent de la prochaine génération de réseaux. IBN s’appuie sur un réseau défini par logiciel (SDN), transformant une approche matérielle et manuelle de la conception et de l’exploitation des réseaux en une approche centrée sur le logiciel et entièrement automatisée.
Les objectifs commerciaux du réseau sont exprimés comme intention. IBN capture l’intention de l’entreprise et utilise l’analyse, l’apprentissage automatique et l’automatisation pour aligner le réseau de manière continue et dynamique à mesure que les besoins de l’entreprise évoluent.
IBN capture et traduit l’intention de l’entreprise en politiques de réseau qui peuvent être automatisées et appliquées de manière cohérente à travers le réseau.
Cisco considère IBN comme ayant trois fonctions essentielles: la traduction, l’activation et l’assurance. Ces fonctions interagissent avec l’infrastructure physique et virtuelle sous-jacente, comme illustré dans la figure.
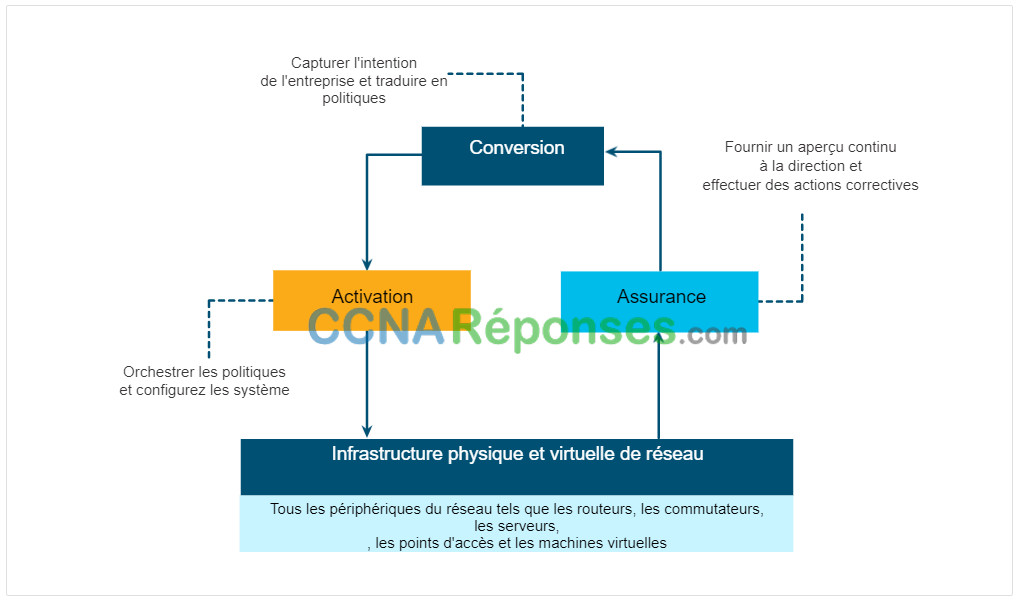
Conversion – La fonction de traduction permet à l’administrateur du réseau d’exprimer le comportement de réseau attendu qui répondra le mieux à l’intention de l’entreprise.
Activation – L’intention capturée doit ensuite être interprétée dans des politiques qui peuvent être appliquées à travers le réseau. La fonction d’activation installe ces stratégies dans l’infrastructure physique et virtuelle du réseau à l’aide d’une automatisation à l’échelle du réseau.
Assurance – Afin de vérifier en permanence que l’intention exprimée est respectée par le réseau à tout moment, la fonction d’assurance maintient une boucle de validation et de vérification continue.
14.6.3 Infrastructure de Réseau comme Tissu
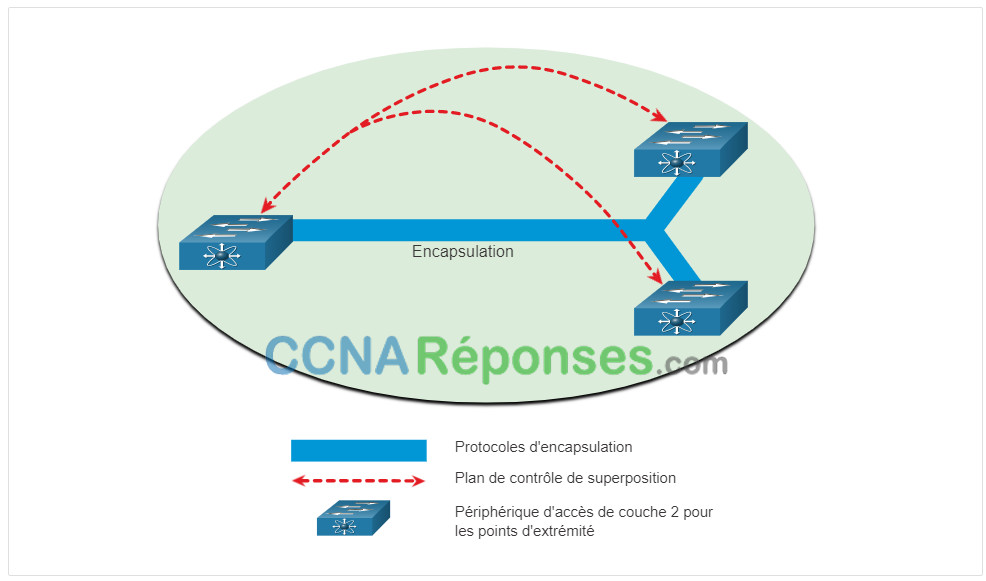
Du point de vue d’IBN, l’infrastructure de réseau physique et virtuelle est un structure. Tissu est un terme utilisé pour décrire une superposition qui représente la topologie logique utilisée pour se connecter virtuellement aux périphériques, comme illustré dans la figure. La superposition limite le nombre de périphériques que l’administrateur du réseau doit programmer. Il fournit également des services et des méthodes de transfert alternatifs non contrôlés par les périphériques physiques sous-jacents. Par exemple, la superposition est l’endroit où les protocoles d’encapsulation comme la sécurité IP (IPsec) et le contrôle et l’approvisionnement des points d’accès sans fil (CAPWAP) se produisent. À l’aide d’une solution IBN, l’administrateur réseau peut spécifier via des politiques ce qui se passe exactement dans le plan de contrôle de superposition. Notez que la façon dont les commutateurs sont physiquement connectés n’est pas une préoccupation de la superposition.
Exemple de Réseau Superposé
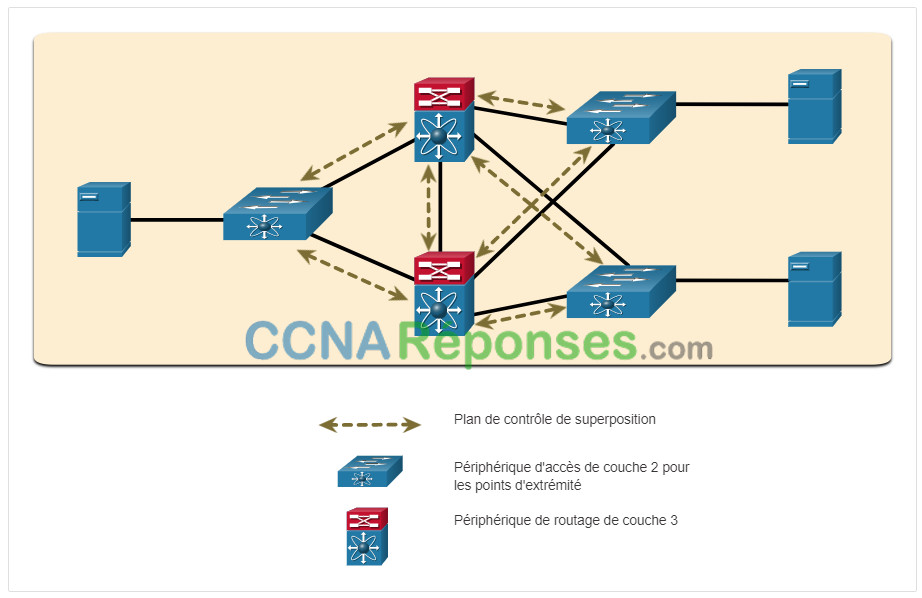
Le réseau sous-jacent est la topologie physique qui comprend tout le matériel nécessaire pour atteindre les objectifs de l’entreprise. La sous-couche révèle des dispositifs supplémentaires et précise comment ces dispositifs sont connectés, comme le montre la figure. Les points de terminaison, tels que les serveurs de la figure, accèdent au réseau via les périphériques de couche 2. Le plan de contrôle sous-jacent est responsable des tâches simples d’acheminement.
Exemple de Réseau Sous-jacent
14.6.4 Cisco Digital Network Architecture (DNA)
Cisco implémente le tissu IBN à l’aide de Cisco DNA. Comme le montre la figure, l’intention de l’entreprise est déployée en toute sécurité dans l’infrastructure de réseau (le tissu). Cisco DNA collecte ensuite continuellement les données d’une multitude de sources (périphériques et applications) pour fournir un riche contexte d’informations. Ces informations peuvent ensuite être analysées pour s’assurer que le réseau fonctionne en toute sécurité à son niveau optimal et conformément à l’intention de l’entreprise et aux politiques du réseau.
Mise en œuvre Continue de Cisco DNA de l’Intention Commerciale
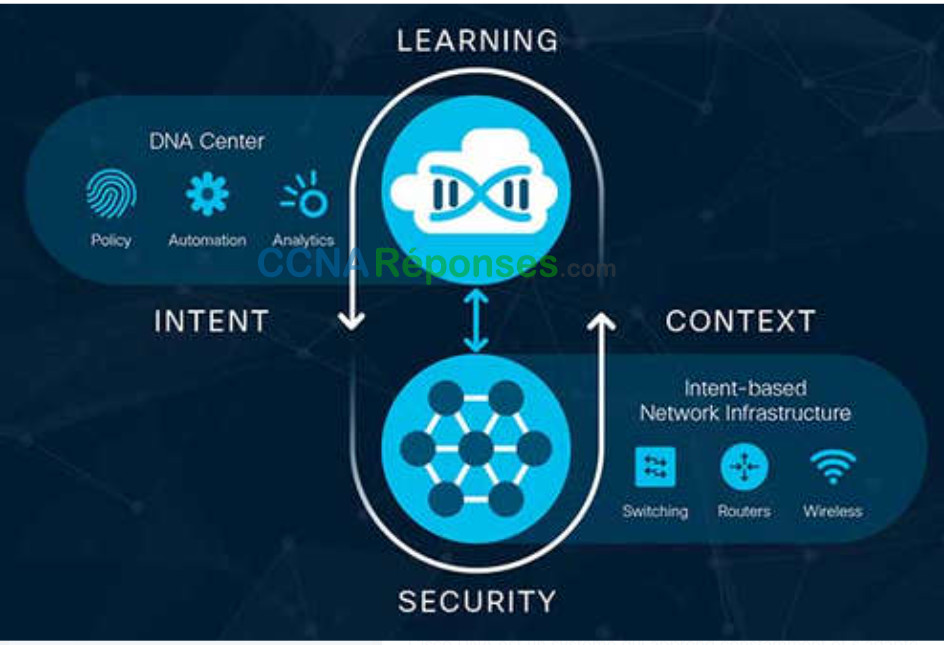
Cisco DNA est un système qui apprend constamment et s’adapte pour répondre aux besoins de l’entreprise. Le tableau nomme certains produits et solutions Cisco DNA.
| Solution de Cisco DNA | Description | Bénéfices |
|---|---|---|
| SD-Access |
|
Permet l’accès au réseau en quelques minutes pour tout utilisateur ou appareil à n’importe quelle application sans compromettre la sécurité. |
| SD-WAN |
|
|
| Cisco DNA Assurance |
|
|
| Sécurité Cisco DNA |
|
|
Ces solutions ne s’excluent pas mutuellement. Par exemple, les quatre solutions pourraient être déployées par une organisation.
Beaucoup de ces solutions sont implémentées à l’aide de Cisco DNA Center qui fournit un tableau de bord logiciel pour gérer un réseau d’entreprise.
14.6.5 Cisco DNA Center
Cisco DNA Center correspond au contrôleur de base et à la plate-forme d’analytique au cœur de Cisco DNA. Il prend en charge l’expression d’intention pour plusieurs cas d’utilisation, y compris les capacités d’automatisation de base, le provisionnement de tissu et la segmentation basée sur des politiques dans le réseau d’entreprise. Cisco DNA Center est un centre de gestion et de commande de réseau pour l’approvisionnement et la configuration des périphériques de réseau. Il s’agit d’une plate-forme matérielle et logicielle fournissant une «vitre unique» (interface unique) axée sur l’assurance, l’analytique et l’automatisation.
La page de lancement de l’interface du centre de DNA vous donne un résumé général de la santé et un instantané du réseau, comme illustré dans la figure. À partir de là, l’administrateur de réseau peut rapidement explorer les domaines d’intérêt.
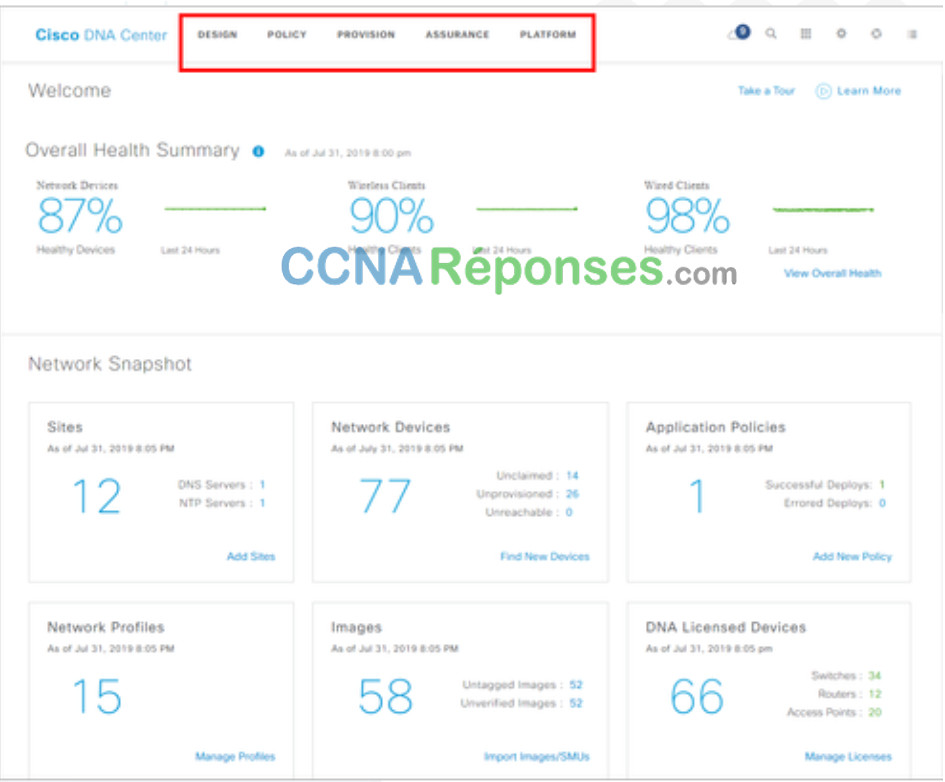
En haut, les menus vous permettent d’accéder aux cinq zones principales du centre de DNA. Comme le montre la figure, la procédure est la suivante :
- Conception – Modélisez tout votre réseau, des sites et bâtiments aux périphériques et liaisons, physiques et virtuels, sur le campus, la branche, le WAN et le cloud.
- Politique – Utilisez des politiques pour automatiser et simplifier la gestion du réseau, en réduisant les coûts et les risques tout en accélérant le déploiement de services nouveaux et améliorés.
- Provision – Fournissez de nouveaux services aux utilisateurs avec facilité, rapidité et sécurité sur votre réseau d’entreprise, indépendamment de la taille et de la complexité du réseau.
- Assurance – Utilisez une surveillance proactive et des informations provenant du réseau, des périphériques et des applications pour prévoir les problèmes plus rapidement et garantir que les changements de politique et de configuration atteignent l’objectif commercial et l’expérience de l’utilisateur que vous souhaitez.
- Plate-forme – Utilisez les API pour vous intégrer à vos systèmes informatiques préférés pour créer des solutions de bout en bout et ajouter la prise en charge des périphériques multifournisseurs.
14.7 Module pratique et questionnaire
14.7.1 Qu’est-ce que j’ai appris dans ce module?
L’automatisation est tout processus auto-piloté, réduisant et éliminant potentiellement le besoin d’intervention humaine. Chaque fois qu’une action est prise par un appareil sur la base d’une information extérieure, cet appareil est un appareil intelligent. Pour que les appareils intelligents «réfléchissent», ils doivent être programmés à l’aide d’outils d’automatisation de réseau.
Les formats de données sont simplement un moyen de stocker et d’échanger des données dans un format structuré. Un de ces formats est appelé Hypertext Markup Language (HTML). Les formats de données courants utilisés dans de nombreuses applications, y compris l’automatisation et la programmabilité du réseau, sont la notation d’objet JavaScript (JSON), le langage de balisage extensible (XML) et le langage de balisage (YAML). Les formats de données ont des règles et une structure similaires à celles que nous avons avec la programmation et les langages écrits.
Une API est un ensemble de règles décrivant comment une application peut interagir avec une autre et les instructions permettant à l’interaction de se produire. Les API ouvertes / publiques sont, comme leur nom l’indique, accessibles au public. Les API internes / privées sont utilisées uniquement au sein d’une organisation. Les API partenaires sont utilisées entre une entreprise et ses partenaires commerciaux. Il existe quatre types d’API de service Web: SOAP (Simple Object Access Protocol), REST (Representational State Transfer), eXtensible Markup Language-Remote Procedure Call (XML-RPC) et JavaScript Object Notation-Remote Procedure Call (JSON-RPC) .
Une API REST définit un ensemble de fonctions que les développeurs peuvent utiliser pour effectuer des requêtes et recevoir des réponses via le protocole HTTP tel que GET et POST. La conformité aux contraintes de l’architecture REST est généralement appelée «RESTful». Les API RESTful utilisent des méthodes HTTP courantes, notamment POST, GET, PUT, PATCH et DELETE. Ces méthodes correspondent aux opérations RESTful: créer, lire, mettre à jour et supprimer (ou CRUD). Les ressources Web et les services Web tels que les API RESTful sont identifiés à l’aide d’un URI. Un URI a deux spécialisations, Nom de ressource uniforme (URN) et Localisateur de ressources uniforme (URL). Dans un service Web RESTful, une demande adressée à l’URI d’une ressource provoquera une réponse. La réponse sera une charge utile généralement formatée en JSON. Les différentes parties de la demande d’API sont le serveur d’API, les ressources et la requête. Les requêtes peuvent inclure le format, la clé et les paramètres.
Il existe maintenant des méthodes nouvelles et différentes permettant aux opérateurs de réseau de surveiller, gérer et configurer automatiquement le réseau. Il s’agit notamment de protocoles et de technologies telles que REST, Ansible, Puppet, Chef, Python, JSON, XML, etc. Les outils de gestion de la configuration utilisent des demandes d’API RESTful pour automatiser les tâches et évoluer sur des milliers d’appareils. Les caractéristiques du réseau qui bénéficient de l’automatisation comprennent le logiciel et le contrôle de version, les attributs de périphérique tels que les noms, l’adressage et la sécurité, les configurations de protocole et les configurations ACL. Les outils de gestion de la configuration incluent généralement l’automatisation et l’orchestration. L’orchestration est l’organisation des tâches automatisées qui se traduit par un processus de coordonnées ou un flux de travail. Ansible, Chef, Puppet et SaltStack sont tous livrés avec la documentation de l’API pour configurer les demandes d’API RESTful.
IBN s’appuie sur SDN et adopte une approche entièrement automatisée et centrée sur les logiciels pour concevoir et exploiter des réseaux. Cisco considère IBN comme ayant trois fonctions essentielles: la traduction, l’activation et l’assurance. L’infrastructure physique et virtuelle du réseau est un tissu. Le terme tissu décrit une superposition qui représente la topologie logique utilisée pour se connecter virtuellement aux périphériques. Le réseau sous-jacent est la topologie physique qui comprend tout le matériel requis pour atteindre les objectifs commerciaux. Cisco implémente le tissu IBN à l’aide de Cisco DNA. L’intention commerciale est déployée en toute sécurité dans l’infrastructure du réseau (le tissu). Cisco DNA collecte ensuite continuellement les données d’une multitude de sources (périphériques et applications) pour fournir un riche contexte d’informations. Cisco DNA Center correspond au contrôleur de base et à la plate-forme d’analytique au cœur de Cisco DNA. Cisco DNA Center est un centre de gestion et de commande de réseau pour l’approvisionnement et la configuration des périphériques de réseau. Il s’agit d’une plate-forme matérielle et logicielle à interface unique qui se concentre sur l’assurance, l’analyse et l’automatisation.