13.0 Introduction
13.0.1 Pourquoi devrais-je suivre ce module?
Bienvenue à la virtualisation des réseaux !
Imaginez que vous vivez dans une maison de deux chambres. Vous utilisez la deuxième chambre pour le stockage. La deuxième chambre est remplie de boîtes, mais vous avez encore plus à placer dans le stockage ! Vous pourriez envisager de construire un ajout sur votre maison. Ce serait une opération coûteuse et vous n’aurez peut-être pas besoin d’autant d’espace pour toujours. Vous décidez de louer une unité de stockage pour le trop-plein.
Tout comme une unité de stockage, la virtualisation réseau et les services cloud peuvent fournir à une entreprise des options autres que l’ajout de serveurs dans son propre centre de données. En plus du stockage, il offre d’autres avantages. Commencez avec ce module pour en savoir plus sur ce que la virtualisation et les services cloud peuvent faire !
13.0.2 Qu’est-ce que je vais apprendre dans ce module?
Titre du module: Virtualisation du réseau
Objectif du module: Expliquer l’objectif et les caractéristiques de la virtualisation du réseau.
| Titre du rubrique | Objectif du rubrique |
|---|---|
| Cloud computing | Expliquer l’importance du cloud computing. |
| Virtualisation | Expliquer l’importance de la virtualisation. |
| Infrastructure de réseau virtuelle | Décrire la virtualisation des services et des périphériques réseau. |
| Réseaux SDN (Software-Defined Networking) | Décrire ce qu’est le SDN. |
| Contrôleurs | Décrire les contrôleurs utilisés dans la programmation du réseau. |
13.1 Cloud computing
13.1.2 Aperçu du Cloud
Dans la vidéo précédente, un aperçu du cloud computing a été expliqué. Le cloud computing implique un grand nombre d’ordinateurs connectés via un réseau qui peut être situé physiquement n’importe où. Les fournisseurs de services de Cloud computing ont massivement recours à la virtualisation pour le déploiement de leurs services. Le cloud computing permet de réduire les coûts opérationnels en optimisant l’utilisation des ressources. Le cloud computing aborde toute une série de questions relatives à la gestion des données :
- Il permet l’accès aux données organisationnelles en tout lieu et à tout moment
- Il rationalise l’organisation des opérations des services informatiques de l’entreprise en leur permettant de s’abonner uniquement aux services requis
- Il réduit, voire supprime, le besoin de disposer des équipements sur site, ainsi que la gestion et la maintenance de ceux-ci
- Il réduit le coût de possession du matériel, les dépenses énergétiques, les besoins d’espace physique ainsi que ceux concernant la formation du personnel
- Il permet aussi une réponse rapide face au besoin croissant d’espace de stockage des données
Grâce à son modèle de facturation à l’utilisation, le cloud computing permet aux entreprises de gérer leurs dépenses IT et de stockage comme un service plutôt qu’un investissement en infrastructure. Les dépenses d’investissement deviennent ainsi des dépenses d’exploitation.

13.1.3 Services cloud
Les services cloud sont disponibles sous diverses options, selon les besoins des clients. Dans son rapport spécial 800-145, le NIST (l’institut américain des normes et de la technologie) a identifié les trois principaux services de cloud computing :
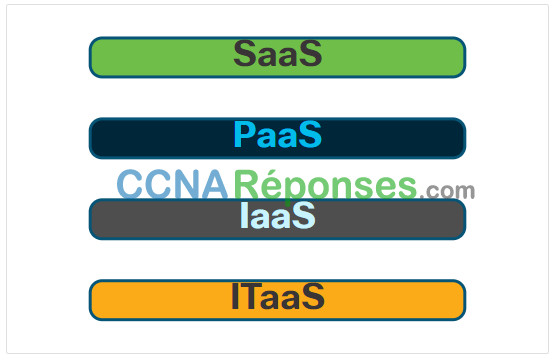
- SaaS (Software as a Service) – Le fournisseur de cloud computing est responsable de l’accès aux applications et aux services, tels que le courrier électronique, la communication et Office 365, qui sont fournis sur Internet. L’utilisateur ne gère aucun aspect des services cloud, sauf pour les paramètres d’application spécifiques à l’utilisateur limités. L’utilisateur doit simplement fournir ses données.
- PaaS (Platform as a Service) – Le fournisseur de cloud computing est chargé de fournir aux utilisateurs l’accès aux outils et services de développement utilisés pour fournir les applications. Ces utilisateurs sont généralement des programmeurs et peuvent contrôler les paramètres de configuration de l’environnement d’hébergement d’applications du fournisseur de cloud.
- IaaS (Infrastructure as a Service) – Le fournisseur de cloud computing est chargé de donner aux responsables informatiques l’accès à l’équipement réseau, aux services réseau virtualisés et à l’infrastructure réseau de support. L’utilisation de ce service cloud permet aux responsables informatiques de déployer et d’exécuter du code logiciel, qui peut inclure des systèmes d’exploitation et des applications.
Les fournisseurs de services dans le Cloud ont étendu ce modèle pour fournir également un support informatique pour chacun des services de cloud computing (ITaaS), comme le montre la figure. Pour les entreprises, ITaaS peut étendre la capacité du réseau sans nécessiter d’investissement dans de nouvelles infrastructures, de formation de nouveau personnel ou de licence pour de nouveaux logiciels. Disponibles à la demande, ces services sont fournis à moindre coût pour tout type de périphérique, partout dans le monde, sans compromettre sa sécurité ni ses fonctionnalités.
13.1.4 Modèles de cloud
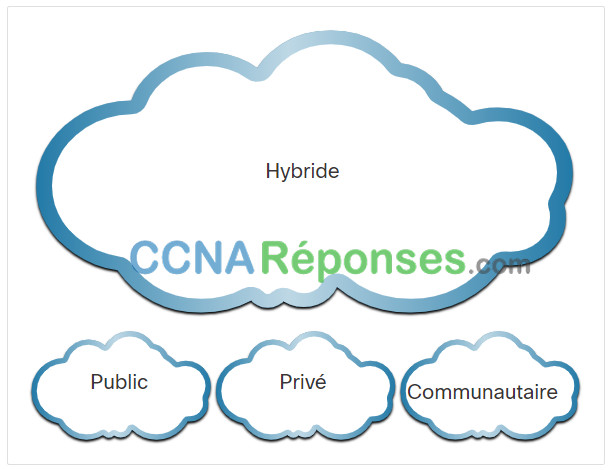
On distingue quatre modèles de cloud principaux, comme illustré sur la figure.
- Clouds publics – Les applications et les services offerts dans un cloud public sont mis à la disposition du grand public. Les services peuvent être gratuits ou sont proposés selon un modèle de paiement à l’utilisation (pay-per-use), comme par exemple le paiement du stockage en ligne. Le cloud public utilise Internet pour fournir des services.
- Clouds privés – Les applications et les services offerts dans un cloud privé sont destinés à une organisation ou une entité spécifique, comme le gouvernement. Un cloud privé peut être configuré via le réseau privé d’une entreprise, mais sa mise en œuvre et sa maintenance peuvent être coûteuses. Il peut également être géré par une entreprise externe en instaurant une politique de sécurisation d’accès très stricte.
- Clouds hybrides – Un cloud hybride est constitué de deux ou plusieurs nuages (exemple : partie privée, partie publique), où chaque partie reste un objet distinct, mais où les deux sont reliées par une architecture unique. Les utilisateurs d’un cloud hybride disposent de différentes autorisations d’accès aux divers services, en fonction de leurs droits d’accès utilisateur.
- Clouds communautaires – Un cloud communautaire est créé pour l’usage exclusif d’une communauté spécifique. Les différences entre clouds publics et clouds communautaires se réfèrent aux besoins fonctionnels qui ont été personnalisés pour la communauté. Par exemple, les organisations de soins de santé doivent se conformer à certaines stratégies et réglementations (par exemple, HIPAA) qui nécessitent une authentification et une confidentialité particulières.
13.1.5 Cloud computing et data center
Les termes « centre de données »(data center) et « informatique en nuage »(cloud computing) sont souvent utilisés de manière incorrecte. Voici leur définition exacte :
- Data center: Généralement, une installation de stockage et de traitement des données gérée par un service informatique interne ou louée hors site.
- Cloud computing: Généralement, un service hors site qui offre un accès à la demande à un pool partagé de ressources informatiques configurables. Ces ressources peuvent être rapidement mises en service et distribuées avec un minimum d’efforts de gestion.
Les centres de données sont les installations physiques qui répondent aux besoins de calcul, de réseau et de stockage des services de cloud computing. Les fournisseurs de services cloud utilisent les centres de données pour héberger leurs services et leurs ressources basés dans le cloud.
Un centre de données peut occuper une pièce, un ou plusieurs étages, voire un bâtiment entier. La construction et l’entretien des centres de données sont en général très coûteux. C’est pour cela que les grandes entreprises utilisent des centres de données privés pour stocker leurs données et fournir des services aux utilisateurs. Les petites organisations qui ne peuvent pas se permettre de maintenir leur propre centre de données privé peuvent réduire le coût global de propriété en louant des services de serveur et de stockage d’une plus grande organisation de centre de données dans le cloud.
13.2 Virtualisation
13.2.1 Cloud computing et virtualisation
Dans la rubrique précédente, vous avez appris à propos des services cloud et des modèles de cloud. Cette rubrique explique la virtualisation. Bien qu’on les confonde souvent, les termes « cloud computing » et « virtualisation » font référence à des concepts bien différents. La virtualisation est le fondement du cloud computing. Sans elle, le cloud computing, tel qu’on le connaît, n’existerait pas.
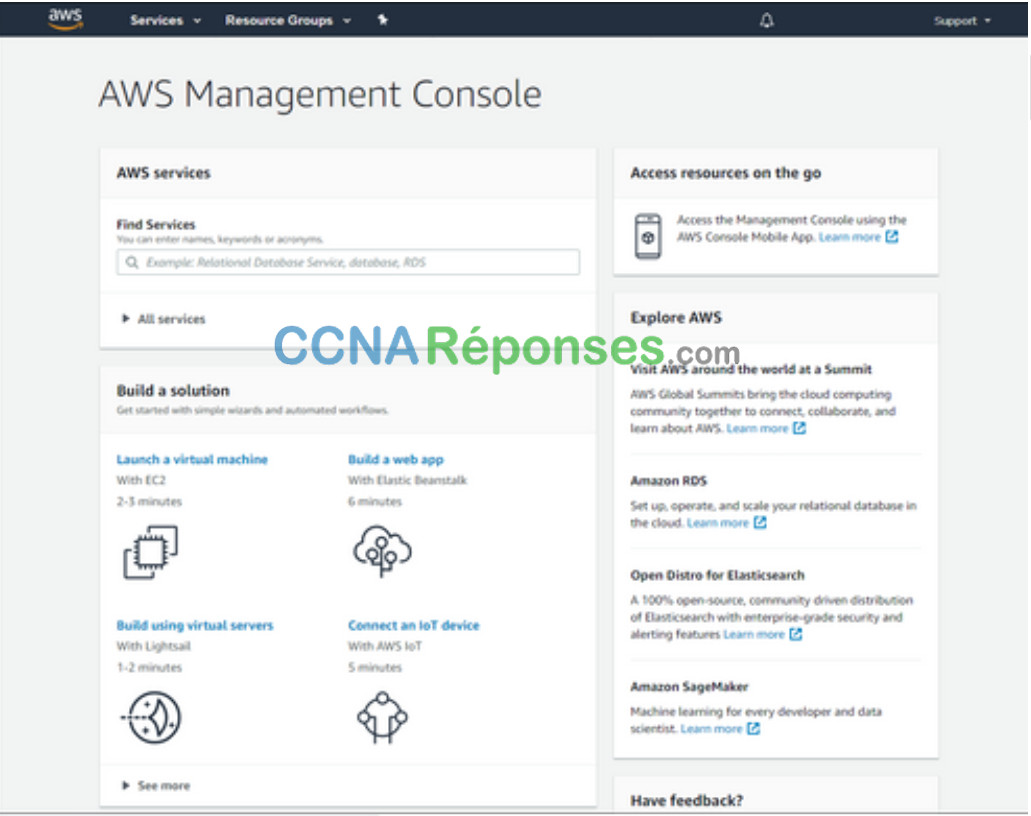
La virtualisation sépare le système d’exploitation (OS) du matériel. Plusieurs fournisseurs proposent des services cloud virtuels capables de provisionner les serveurs de manière dynamique en fonction des besoins. Par exemple, Amazon Web Services (AWS) offre aux clients un moyen simple de fournir dynamiquement les ressources informatiques dont ils ont besoin. Ces instances virtualisées de serveurs sont créées à la demande. Comme le montre la figure, l’administrateur réseau peut déployer divers services à partir d’AWS Management Console, notamment des machines virtuelles, des applications Web, des serveurs virtuels et des connexions aux périphériques IoT.
13.2.2 Serveurs dédiés
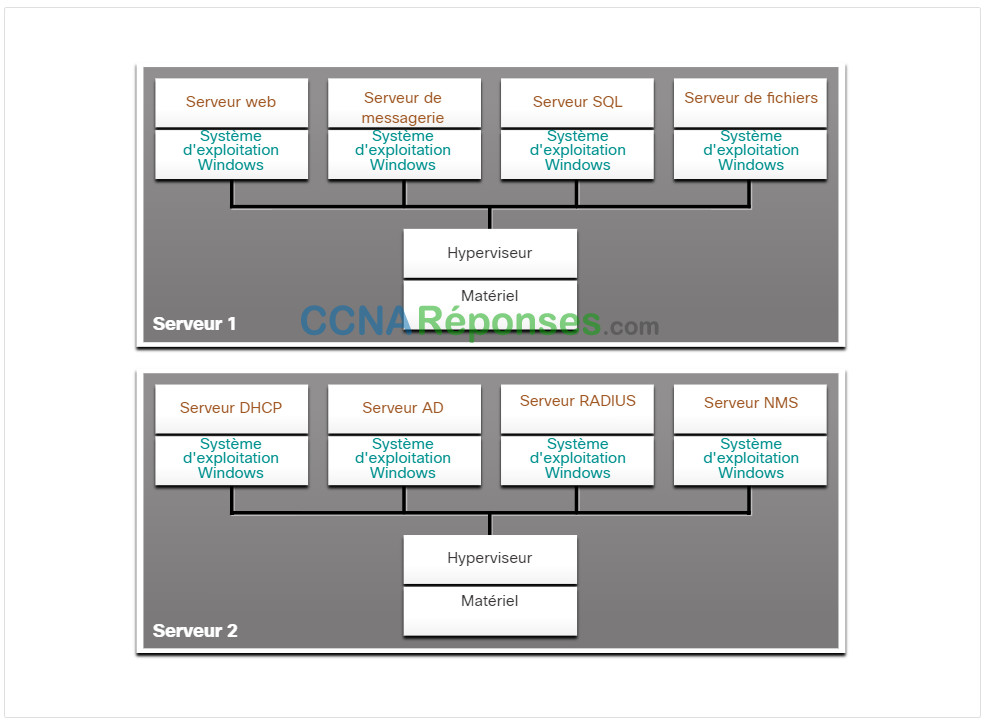
Quelques connaissances historiques sur la technologie de serveur sont nécessaires pour tirer pleinement parti de la virtualisation. Historiquement, les serveurs d’entreprise consistaient en un système d’exploitation serveur, tel que Windows Server ou Linux Server, installé sur un matériel spécifique, comme le montre la figure. La mémoire vive (RAM), la puissance de traitement et l’espace disque d’un serveur étaient consacrés au service fourni (par ex. Internet, services de messagerie électronique, etc.).
Serveurs dédiés

Une telle configuration présentait un problème majeur : la panne d’un composant entraînait l’indisponibilité du service correspondant. C’est ce qu’on appelle un « point de défaillance unique ». La sous-utilisation des serveurs dédiés constituait un autre problème. Ceux-ci restaient souvent inactifs pendant de longues périodes jusqu’à ce que le service spécifique fourni soit sollicité. Ces serveurs ont gaspillé de l’énergie et pris plus d’espace que ne le justifiait la quantité de services fournis. C’est ce qu’on appelle la prolifération des serveurs.
13.2.3 Virtualisation de serveur
La virtualisation des serveurs permet de tirer parti des ressources inutilisées et de consolider le nombre de serveurs nécessaires. Ainsi, plusieurs systèmes d’exploitation peuvent coexister sur une plate-forme matérielle unique.
Sur la figure par exemple, les huit serveurs dédiés utilisés auparavant ont été consolidés en deux serveurs en déployant des hyperviseurs pour prendre en charge plusieurs instances virtuelles de chaque système d’exploitation.
Hypervisor OS Installation
Pour résoudre le problème de point de défaillance unique, la virtualisation implique généralement une fonction de redondance qui peut être mise en œuvre de différentes manières. En cas de panne de l’hyperviseur, la machine virtuelle peut être redémarrée sur un autre hyperviseur. De plus, la même VM peut fonctionner sur deux hyperviseurs simultanément, en copiant les instructions de la RAM et du CPU entre eux. Ainsi, si un hyperviseur tombe en panne, la machine virtuelle continue de fonctionner sur l’autre hyperviseur. Les services fonctionnant sur les VM sont également virtuels et peuvent être installés ou désinstallés dynamiquement, selon les besoins.
L’hyperviseur est un programme, un firmware ou un équipement matériel qui ajoute une couche d’abstraction au-dessus du matériel physique. La couche d’abstraction permet de créer des machines virtuelles qui ont accès à tous les composants matériels de la machine physique, notamment les processeurs, la mémoire, les contrôleurs de disque et les cartes réseau. Chaque machine virtuelle exécute un système d’exploitation complet et distinct. Grâce à la virtualisation, les entreprises peuvent désormais réduire le nombre de serveurs nécessaires. Par exemple, il est tout à fait possible, et courant, de consolider 100 serveurs physiques sous forme de machines virtuelles avec 10 serveurs physiques qui utilisent des hyperviseurs.
13.2.4 Avantages de la virtualisation
L’un des principaux avantages de la virtualisation est qu’elle permet de réduire le coût global :
- Moins de matériel est nécessaire – La virtualisation permet de consolider les serveurs, ce qui nécessite moins de serveurs physiques, moins de dispositifs de réseau et moins d’infrastructures de support. Cela signifie également une réduction des coûts de maintenance.
- Moins d’énergie est consommée – La consolidation des serveurs permet de réduire les coûts mensuels d’alimentation et de refroidissement. La baisse de consommation électrique aide les entreprises à réduire leur empreinte carbone.
- Moins d’espace est nécessaire – La consolidation des serveurs avec la virtualisation réduit l’empreinte globale du centre de données. La diminution du nombre de serveurs, de périphériques réseau et de racks permet de réduire l’espace au sol requis.
La virtualisation présente également d’autres avantages :
- Un prototypage plus facile – Des laboratoires autonomes, fonctionnant sur des réseaux isolés, peuvent être rapidement créés pour tester et prototyper des déploiements de réseaux. En cas d’erreur, l’administrateur peut simplement revenir à une version précédente. Ces environnements de test peuvent être en ligne, mais ils sont isolés des utilisateurs finaux. Une fois les tests terminés, les serveurs et les systèmes peuvent être déployés auprès des utilisateurs.
- Provisionnement plus rapide des serveurs – La création d’un serveur virtuel est bien plus rapide que le provisionnement d’un serveur physique.
- Augmentation du temps de fonctionnement des serveurs – La plupart des plateformes de virtualisation de serveurs offrent désormais des fonctions avancées de tolérance aux pannes redondantes, telles que la migration en direct, la migration du stockage, la haute disponibilité et la planification des ressources distribuées.
- Amélioration de la reprise après désastre – La virtualisation offre des solutions avancées de continuité des activités. Ainsi, grâce à l’abstraction matérielle, le site de reprise d’activité ne doit plus disposer d’équipements matériels identiques à ceux de l’environnement de production. La plupart des plates-formes de virtualisation de serveurs d’entreprise disposent également d’un logiciel qui permet de tester et d’automatiser le basculement avant qu’un désastre ne se produise.
- Support des héritages – La virtualisation peut prolonger la durée de vie des systèmes d’exploitation et des applications, ce qui laisse plus de temps aux entreprises pour migrer vers des solutions plus récentes.
13.2.5 Couches d’abstraction
Pour expliquer le fonctionnement de la virtualisation, il est utile d’utiliser des couches d’abstraction dans les architectures informatiques. Un système informatique se compose des couches d’abstraction suivantes, comme l’illustre la figure :
- Services
- Système d’exploitation
- Firmware
- Matériel
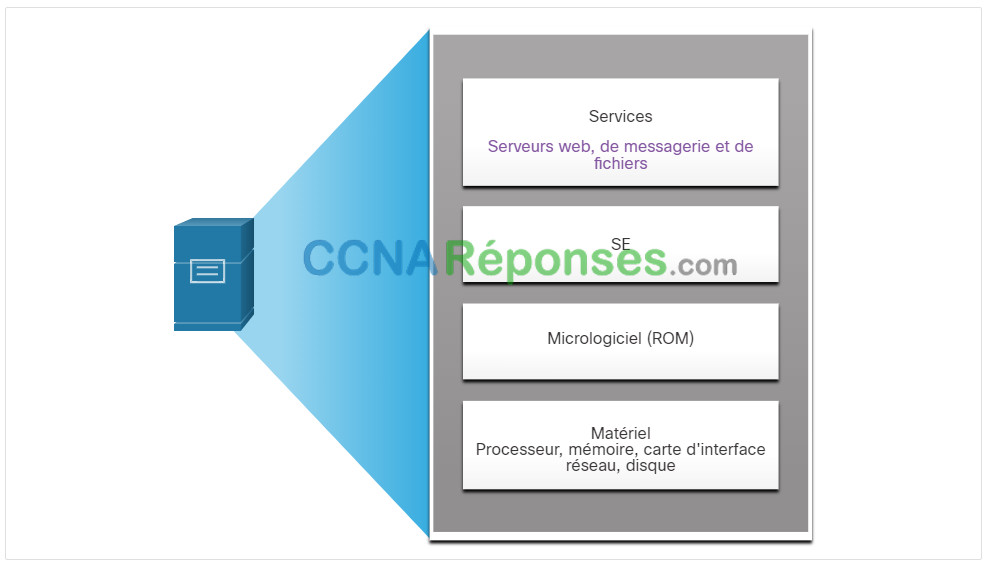
À chaque couche d’abstraction, un code de programmation sert d’interface entre les couches inférieures et supérieures. Par exemple, le langage de programmation C est souvent utilisé pour programmer le micrologiciel qui accède au matériel.
Un exemple de virtualisation est présenté dans la figure. Un hyperviseur est installé entre le firmware et le système d’exploitation. L’hyperviseur peut prendre en charge plusieurs instances de système d’exploitation.
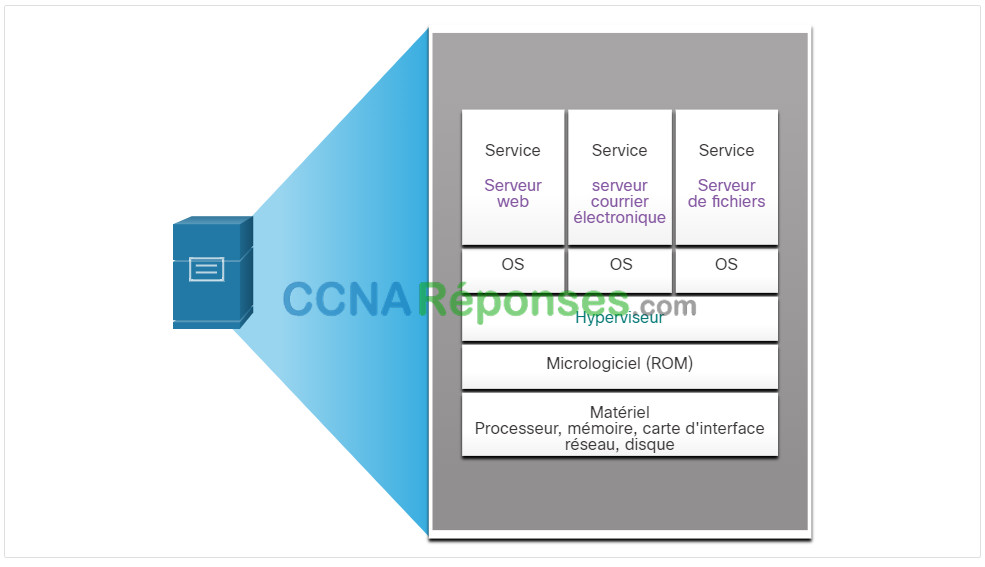
13.2.6 Hyperviseurs de type 2
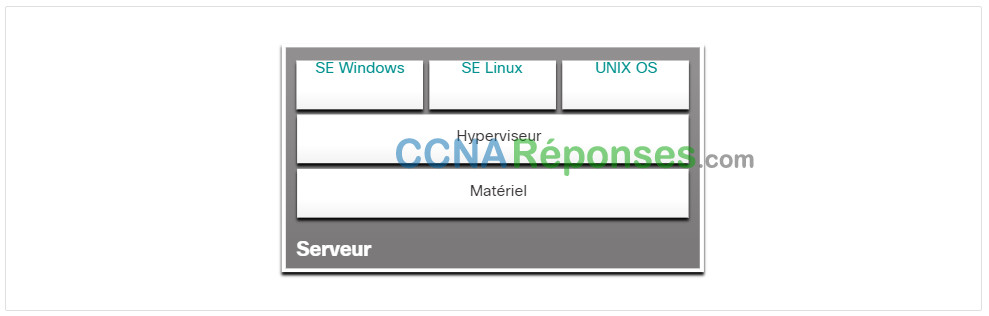
Un hyperviseur de type 2 est un logiciel qui crée et exécute des instances de VM. L’ordinateur sur lequel un hyperviseur prend en charge une ou plusieurs machines virtuelles est appelé « machine hôte ». Les hyperviseurs de type 2 sont également appelés « hyperviseurs hébergés ». Cela est dû au fait que l’hyperviseur est installé sur le système d’exploitation existant, tel que macOS, Windows ou Linux. Une ou plusieurs instances du système d’exploitation sont ensuite installées au-dessus de l’hyperviseur, comme le montre la figure.

Un avantage considérable des hyperviseurs de type 2 est qu’ils ne requièrent aucune console de gestion logicielle.
Les hyperviseurs de type 2 sont très populaires auprès des particuliers et des entreprises qui découvrent la virtualisation. Hyperviseurs de type 2 les plus courants :
- Virtual PC
- VMware Workstation
- Oracle VM VirtualBox
- VMware Fusion
- Mac OS X Parallels
La plupart de ces hyperviseurs sont gratuits. Toutefois, certains hyperviseurs offrent des fonctionnalités plus avancées moyennant des frais.
Remarque: Il est important de s’assurer que la machine hôte est suffisamment robuste pour installer et faire fonctionner les machines virtuelles, afin qu’elle ne soit pas à court de ressources.
13.3 Infrastructure de réseau virtuelle
13.3.1 Hyperviseurs de type 1
Dans la rubrique précédente, vous avez appris la virtualisation. Cette rubrique couvrira l’infrastructure de réseau virtuel.
Les hyperviseurs de type 1 sont également dits « sans système d’exploitation », car ils sont installés directement sur le matériel. Généralement, ils sont utilisés sur des serveurs d’entreprise et des périphériques de mise en réseau de centres de données.
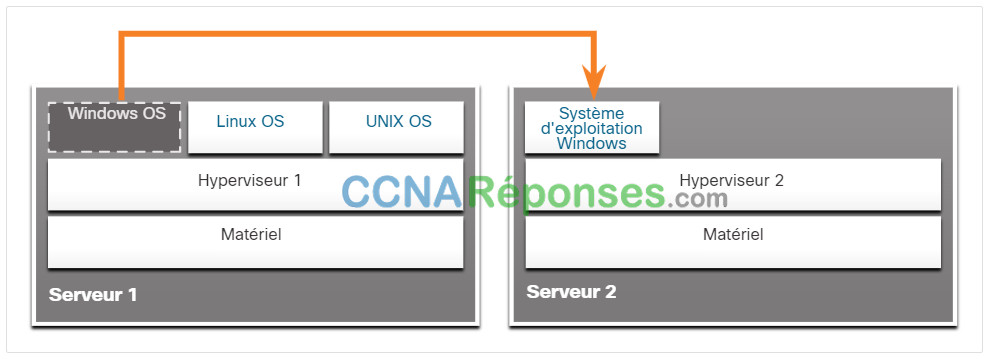
Un hyperviseur de type 1 est installé directement sur le serveur ou le matériel de mise en réseau, Plusieurs instances d’un système d’exploitation sont ensuite installées au-dessus de l’hyperviseur, comme le montre la figure. Les hyperviseurs de type 1 bénéficient d’un accès direct aux ressources matérielles. Par conséquent, ils sont plus efficaces que les architectures hébergées. Ils améliorent l’évolutivité, les performances et la robustesse.
13.3.2 Installation d’une machine virtuelle sur un hyperviseur
Après l’installation d’un hyperviseur de type 1 et le redémarrage du serveur, seules des informations de base apparaissent, notamment la version du système d’exploitation, la quantité de mémoire vive et l’adresse IP. Il est impossible de créer une instance de système d’exploitation à partir de cet écran. La gestion des hyperviseurs de type 1 nécessite en effet une « console de gestion ». Le logiciel de gestion permet de gérer plusieurs serveurs utilisant le même hyperviseur. La console de gestion peut consolider automatiquement les serveurs et allumer ou éteindre les serveurs selon les besoins.
Par exemple, supposons que le serveur 1 dans la figure devienne peu gourmand en ressources. Pour mettre plus de ressources à disposition, l’administrateur réseau utilise la console de gestion pour déplacer l’instance Windows vers l’hyperviseur sur Serveur2. La console de gestion peut également être programmée avec des seuils qui déclencheront automatiquement le déplacement.
La console de gestion permet une reprise en cas de panne matérielle. Si un composant du serveur tombe en panne, la console de gestion déplace automatiquement la VM vers un autre serveur. La console de gestion pour Cisco UCS (Unified Computing System) est illustrée sur la figure. Cisco UCS Manager contrôle de multiples serveurs et gère les ressources pour des milliers de machines virtuelles.
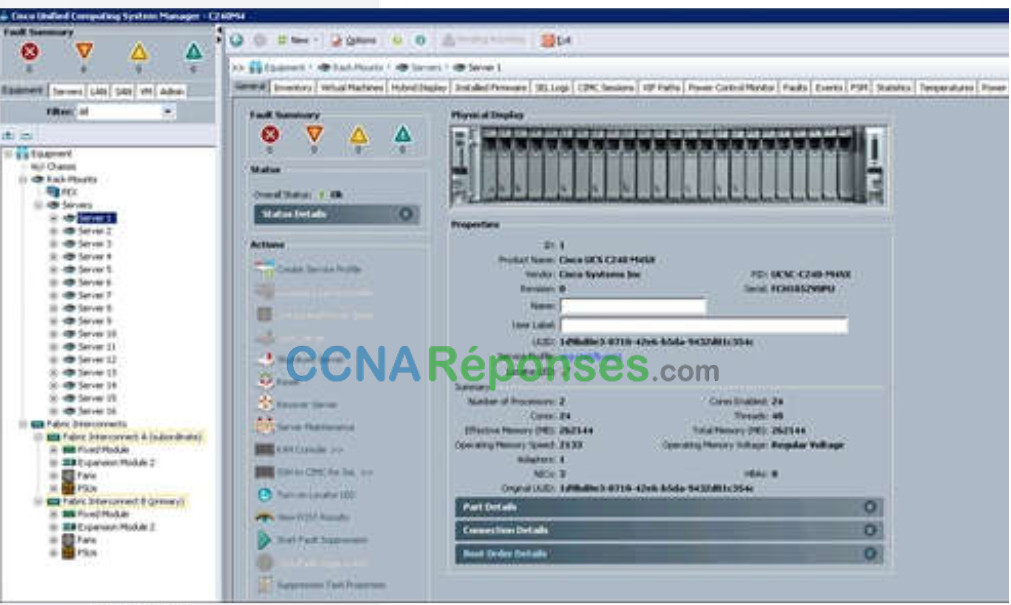
Certaines consoles de gestion permettent également la sur-allocation de serveurs. c.-à-d. l’installation de plusieurs instances de système d’exploitation dont l’allocation de mémoire dépasse la quantité totale de mémoire disponible sur un serveur. Par exemple, sur un serveur disposant de 16 Go de mémoire vive (RAM), un administrateur peut créer quatre instances de système d’exploitation et allouer à chacune 10 Go de RAM. Ce type de surallocation est utilisé couramment, dans la mesure où il est rare que les quatre instances fassent toutes appel simultanément aux 10 GB de RAM.
13.3.3 La complexité de la virtualisation des réseaux
La virtualisation des serveurs dissimule aux utilisateurs les ressources des serveurs, telles que le nombre et l’identité des serveurs physiques, des processeurs et des systèmes d’exploitation. Cette situation peut soulever des problèmes lorsque le data center repose sur des architectures réseau traditionnelles.
Par exemple, les réseaux locaux virtuels (VLAN) utilisés par les machines virtuelles doivent être affectés au même port de commutation que le serveur physique exécutant l’hyperviseur. Toutefois, les machines virtuelles peuvent être déplacées, et l’administrateur réseau doit être en mesure d’ajouter, supprimer et modifier des ressources et des profils réseau. Ce processus serait manuel et prendrait beaucoup de temps avec les commutateurs de réseau traditionnels.
La virtualisation pose un autre problème : les flux de trafic diffèrent sensiblement du modèle client-serveur traditionnel. En règle générale, un centre de données a une quantité considérable de trafic échangé entre des serveurs virtuels, tels que les serveurs UCS indiqués dans la figure. Ces flux sont appelés trafic est-ouest et peuvent changer de lieu et d’intensité au fil du temps. Le trafic Nord-Sud se produit entre les couches de distribution et de base et est généralement destiné à des emplacements hors site tels qu’un autre centre de données, d’autres fournisseurs de cloud ou Internet.
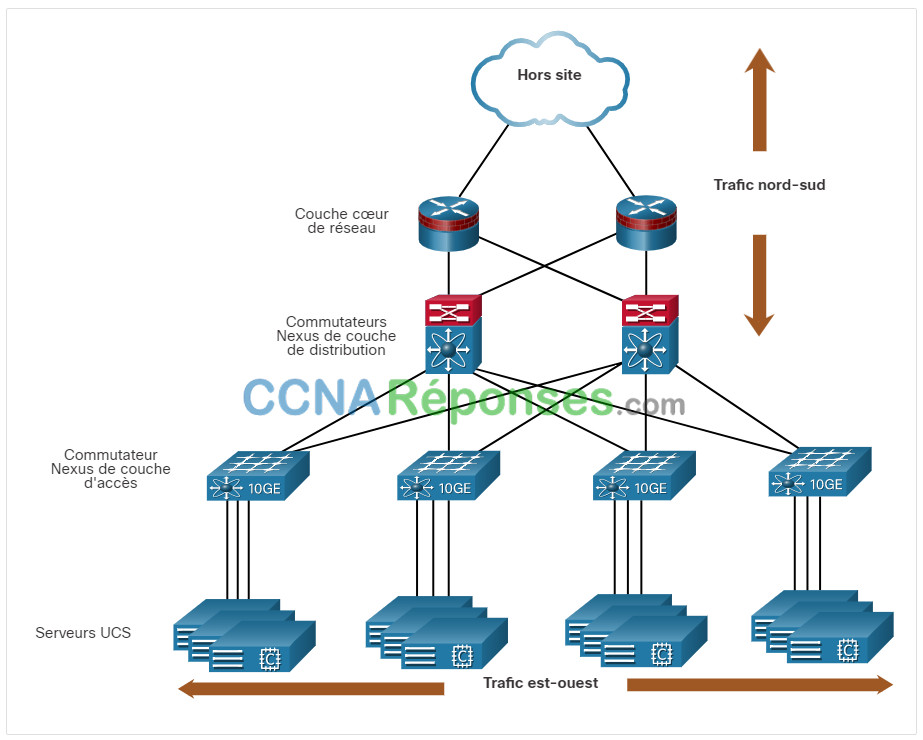
Le trafic dynamique en constante évolution nécessite une approche flexible de la gestion des ressources réseau. Pour faire face à ces fluctuations, les infrastructures réseau existantes peuvent s’appuyer sur des configurations de QoS et de niveau de sécurité propres à chaque flux. Néanmoins, dans les grandes entreprises qui utilisent des équipements multifournisseurs, la reconfiguration nécessaire après l’activation d’une nouvelle machine virtuelle risque de prendre beaucoup de temps.
L’infrastructure du réseau peut également bénéficier de la virtualisation. Les fonctions de réseau peuvent être virtualisées. Chaque périphérique réseau peut être segmenté en plusieurs périphériques virtuels fonctionnant en tant que périphériques indépendants. Les exemples incluent les sous-interfaces, les interfaces virtuelles, les VLANs et les tables de routage. Le routage virtualisé est appelé routage et transfert virtuels (VRF).
Comment le réseau est-il virtualisé ? La réponse se trouve dans le mode de fonctionnement d’un dispositif de réseau utilisant un plan de données et un plan de contrôle, comme nous le verrons dans la rubrique suivante.
13.4 Réseaux SDN
13.4.2 Plans de contrôle et de données
La rubrique précédente expliquait l’infrastructure de réseau virtuel. Ce thème portera sur les réseaux définis par logiciel SDN (Software- Defined Networking). SDN a été expliqué dans la vidéo précédente. Nous allons couvrir plus de détails ici.
Un appareil réseau contient les plans suivants :
- Plan de contrôle – Il est généralement considéré comme le cerveau d’un appareil. le plan de contrôle permet de prendre les décisions de transmission. Il comprend des mécanismes de transmission d’itinéraire de couche 2 et 3, notamment la table de voisinage et la table topologique (protocole de routage), la table de routage pour IPv4 et IPv6, le protocole STP et la table ARP. Les informations envoyées au plan de contrôle sont traitées par le processeur.
- Plan de données – Également appelé plan d’acheminement, ce plan est généralement la matrice de commutation qui relie les différents ports du réseau sur un appareil. Le plan de données de chaque périphérique permet de transmettre les flux de trafic. Les routeurs et les commutateurs utilisent les informations du plan de contrôle pour transmettre le trafic entrant vers l’interface de sortie appropriée. Les informations dans le plan de données sont généralement traitées par un processeur spécial du plan de données sans que l’unité centrale n’intervienne.
Cliquez sur chaque bouton pour une illustration et une explication de la différence entre le fonctionnement du contrôle localisé sur un commutateur de couche 3 et un contrôleur centralisé dans SDN
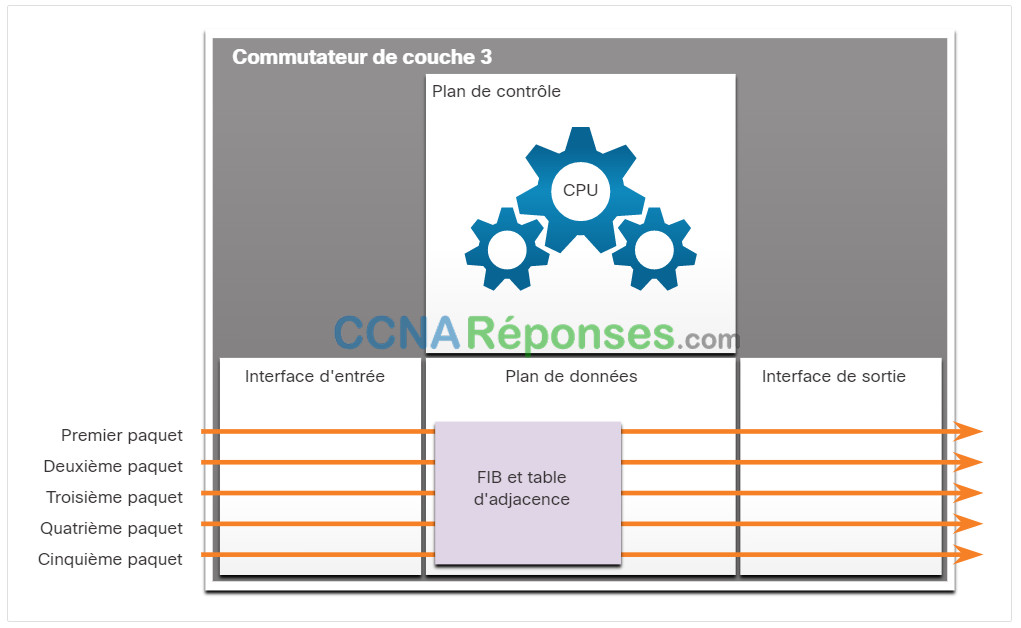
La figure illustre la manière dont Cisco Express Forwarding (CEF) utilise le plan de contrôle et le plan de données pour traiter les paquets.
Cisco Express Forwarding est une technologie avancée de commutation IP au niveau de la couche 3 qui permet de transmettre des paquets à partir du plan de données sans consulter le plan de contrôle. Avec le protocole CEF, la table de routage et la table ARP du plan de contrôle alimentent au préalable respectivement le FIB et la table ARP du plan de contrôle alimente en amont la table de contiguïté. Les paquets sont ensuite transmis directement par le plan de données en fonction des informations contenues dans le FIB et la table de contiguïté, sans avoir à faire appel au plan de contrôle.
Commutateur de couche 3 et CEF
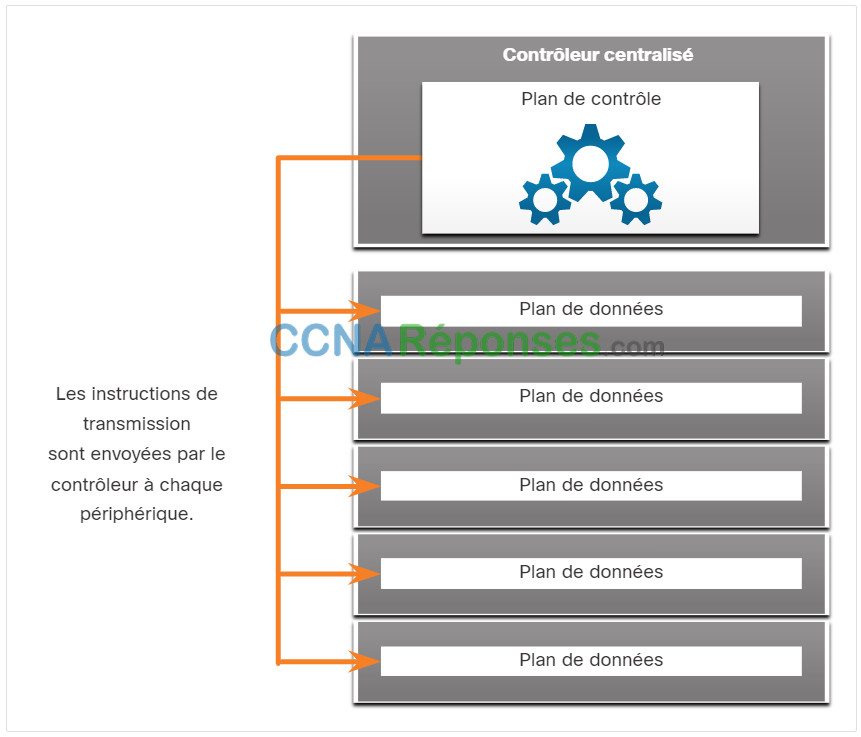
SDN est essentiellement la séparation du plan de contrôle et du plan de données. La fonction de plan de contrôle est retirée de chaque appareil et est assurée par un contrôleur centralisé, comme le montre la figure. Le contrôleur centralisé communique les fonctions de plan de contrôle à chaque périphérique. Ainsi le contrôleur centralisé gère le flux des données, renforce la sécurité et fournit d'autres services, et chaque périphérique peut se concentrer sur la transmission des données.
SDN et contrôleur central
Plan de gestion
Non représenté dans les figures est le plan de gestion, qui est responsable de la gestion d’un périphérique via sa connexion au réseau. Les administrateurs réseau utilisent des applications telles que Secure Shell (SSH), Trivial File Transfer Protocol (TFTP), Secure FTP et Secure Hypertext Transfer Protocol (HTTPS) pour accéder au plan de gestion et configurer un périphérique. Le plan de gestion correspond à la façon dont vous avez accédé aux périphériques et configuré dans vos études de mise en réseau. En outre, des protocoles comme le protocole SNMP (Simple Network Management Protocol) utilisent le plan de gestion.
13.4.3 Technologies de virtualisation des réseaux
Il y a un peu plus de dix ans, VMware a développé une technologie de virtualisation qui permettait à un système d’exploitation hôte de prendre en charge plusieurs systèmes d’exploitation clients. La plupart des outils de virtualisation s’appuient de nos jours sur cette technologie. Les serveurs dédiés cèdent désormais la place aux serveurs virtualisés, et la virtualisation gagne rapidement les réseaux de data center et d’entreprise.
Deux architectures réseau majeures ont été développées pour prendre en charge la virtualisation :
- SDN (Software-Defined Networking) – Une architecture de réseau qui virtualise le réseau, offrant une nouvelle approche de l’administration et de la gestion du réseau qui vise à simplifier et à rationaliser le processus d’administration.
- ACI (Cisco Application Centric Infrastructure) – Une solution matérielle spécialement conçue pour intégrer le cloud computing et la gestion des centres de données.
Les composantes du SDN peuvent comprendre les éléments suivants :
- OpenFlow – Cette approche a été développée à l’université de Stanford pour gérer le trafic entre les routeurs, les commutateurs, les points d’accès sans fil et un contrôleur. Le protocole OpenFlow constitue un élément fondamental dans la mise en œuvre des solutions SDN. Recherchez OpenFlow et Open Networking Foundation pour plus d’informations.
- OpenStack – cette approche repose sur une plate-forme d’orchestration et de virtualisation pour créer des environnements cloud évolutifs et mettre en œuvre une solution IaaS (infrastructure en tant que service). OpenStack est souvent utilisé avec Cisco ACI. L’orchestration en réseau est le processus d’automatisation de l’approvisionnement des composants du réseau tels que les serveurs, le stockage, les commutateurs, les routeurs et les applications. Recherchez OpenStack pour plus d’informations.
- Autres composants – Parmi les autres composants figurent l’interface avec le système de routage (I2RS), l’interconnexion transparente de lots de liens (TRILL), le Cisco FabricPath (FP) et le Shortest Path Bridging (SPB) de la norme IEEE 802.1aq.

13.4.4 Architectures traditionnelles et SDN
Dans une architecture traditionnelle de routeurs ou de commutateurs, les fonctions de plans de contrôle et de données sont assurées sur un même périphérique. Les décisions relatives à l’acheminement et à la transmission des paquets relèvent de la responsabilité du système d’exploitation de l’appareil. Dans SDN, la gestion du plan de contrôle est déplacée vers un contrôleur SDN centralisé. La figure compare les architectures traditionnelles et SDN.
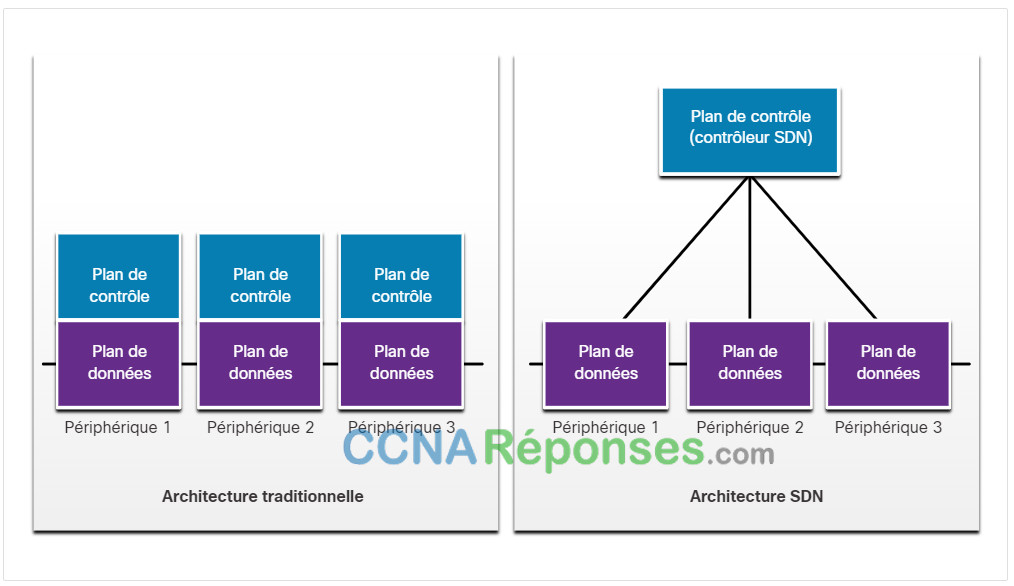
Le contrôleur SDN est une entité logique qui permet aux administrateurs réseau de gérer et de définir la manière dont le plan de données des routeurs et des commutateurs virtuels doit gérer le trafic réseau. En d’autres termes, il orchestre, arbitre et simplifie la communication entre les applications et les composants réseau.
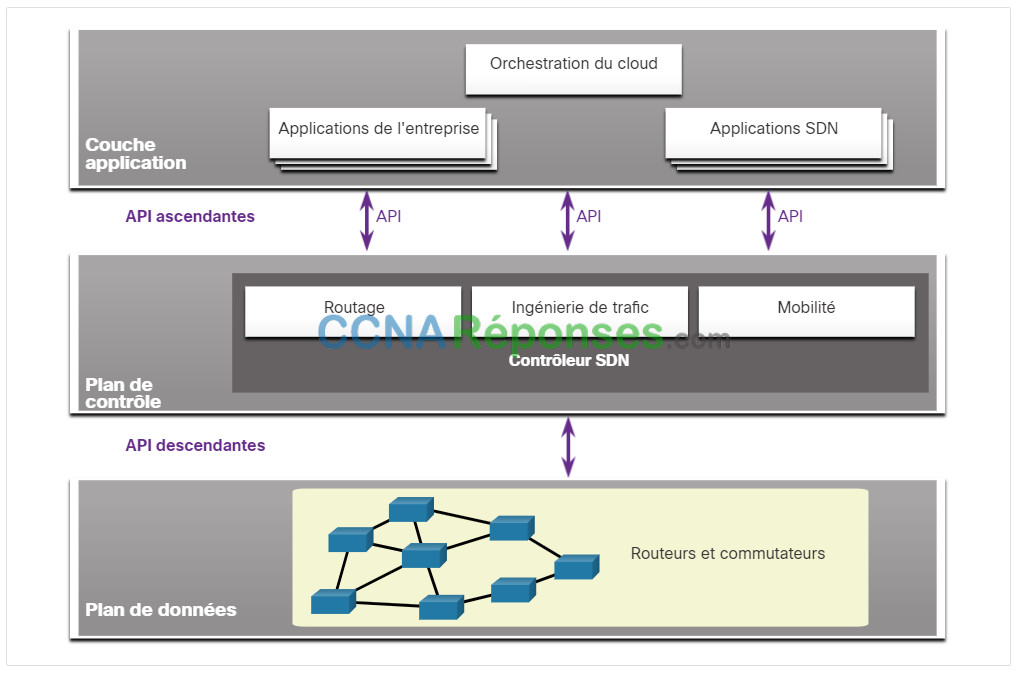
Le cadre complet du SDN est illustré dans la figure. Notez que l’infrastructure SDN fait appel à des interfaces de programmation (API). Une API est un ensemble de requêtes normalisées qui définissent la façon dont une application soumet une requête de services à une autre application. Le contrôleur SDN utilise des API Northbound pour communiquer avec les applications en amont. Ces API aident les administrateurs réseau à mettre en forme le trafic et à déployer les services. Le contrôleur SDN utilise également des API en direction du sud pour définir le comportement des plans de données sur les commutateurs et routeurs en aval (downstream). OpenFlow est l’API originale et largement mise en œuvre vers le sud.
13.5 Contrôleurs
13.5.1 Fonctionnement du contrôleur SDN
La rubrique précédente portait sur le SDN. Cette rubrique explique les contrôleurs.
Le contrôleur SDN définit les flux de données entre le plan de contrôle centralisé et les plans de données sur des routeurs et des commutateurs individuels.
Pour pouvoir traverser le réseau, chaque flux doit être approuvé par le contrôleur SDN qui vérifie que la communication est autorisée dans le cadre de la politique réseau de l’entreprise. Si le contrôleur autorise le flux, il calcule l’itinéraire que ce dernier doit suivre et ajoute une entrée correspondante au flux dans tous les commutateurs situés sur le trajet.
Toutes les fonctions complexes sont prises en charge par le contrôleur. Le contrôleur alimente les tables de flux. Les commutateurs gèrent les tables de flux. Dans la figure, un contrôleur SDN communique avec les commutateurs prenant en charge OpenFlow à l’aide de ce protocole. Ce protocole s’appuie sur le protocole TLS (Transport Layer Security) pour sécuriser les communications issues du plan de contrôle à l’échelle du réseau. Chaque commutateur OpenFlow se connecte à d’autres commutateurs OpenFlow. Ils peuvent également se connecter aux périphériques utilisateur qui font partie d’un flux de paquets.
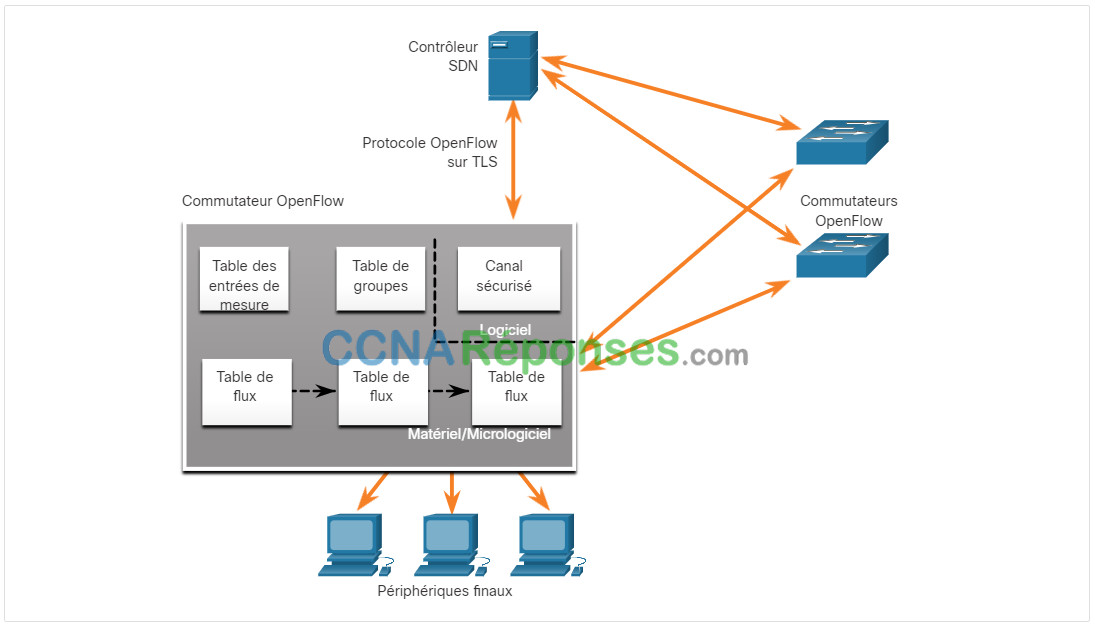
Sur chaque commutateur, la gestion des flux de paquets est assurée par une série de tables mises en œuvre au niveau du matériel ou du firmware. À l’échelle du commutateur, un flux est une séquence de paquets qui correspond à une entrée spécifique dans une table de flux.
Les trois types de tableaux présentés dans la figure précédente sont les suivants :
- Table des flux – Ce tableau fait correspondre les paquets entrants à un flux particulier et spécifie les fonctions qui doivent être exécutées sur les paquets. Il peut y avoir plusieurs tables de flux qui fonctionnent à la manière d’un pipeline.
- Table de groupe – Un tableau de flux peut diriger un flux vers un tableau de groupe, ce qui peut déclencher diverses actions qui affectent un ou plusieurs flux
- Table de comptage – Cette table déclenche une série d’actions liées aux performances sur un débit, y compris la capacité de limiter le trafic.
13.5.3 Principaux composants ACI
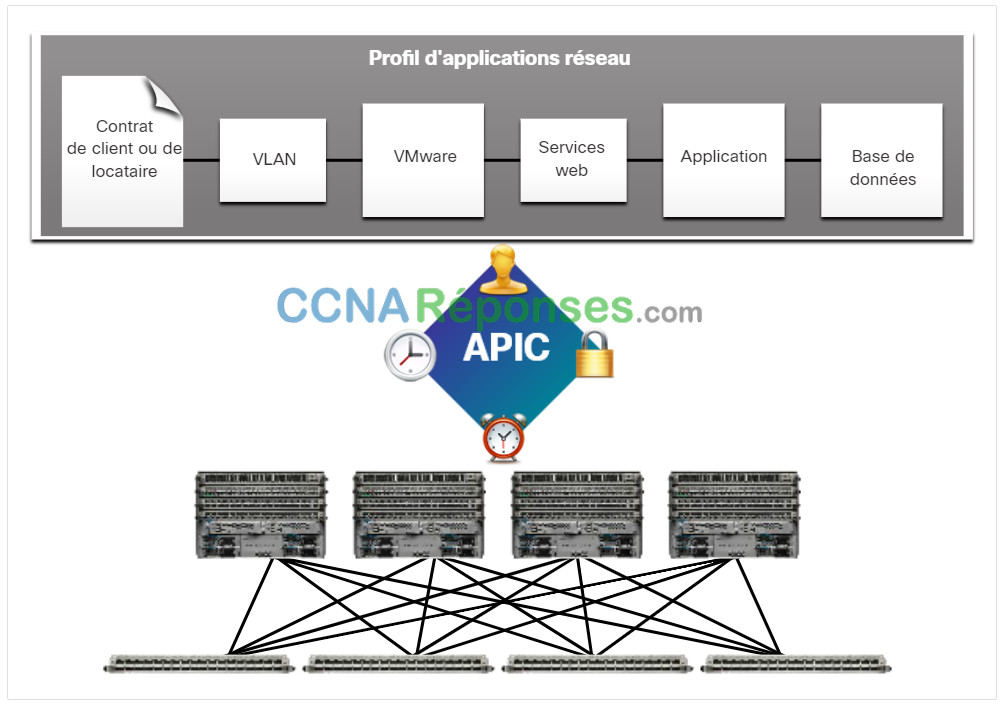
Voici les trois composants centraux de l’infrastructure ACI :
- Profil de réseau d’application (ANP) – Un ANP est un ensemble de groupes de points terminaux (EPG), leurs connexions et les politiques qui définissent ces connexions. La figure ne présente que quelques exemples de groupe de terminaux, tels que les VLANs, les services web et les applications. Un ANP est souvent beaucoup plus complexe.
- APIC (Application Policy Infrastructure Controller) – L’APIC est considéré comme le cerveau de l’architecture ACI. Il s’agit d’un contrôleur logiciel centralisé qui gère et exploite une « fabric » de clusters ACI évolutive. Il est conçu pour être programmable et assurer une gestion centralisée. Il traduit les politiques applicatives en codes de programmation réseau.
- Commutateurs Cisco Nexus série 9000 – Ces commutateurs fournissent une structure de commutation adaptée aux applications et fonctionnent avec un APIC pour gérer l’infrastructure réseau virtuelle et physique.
L’APIC est positionné entre l’APN et l’infrastructure de réseau activée par l’ACI. L’APIC traduit les exigences de l’application en une configuration de réseau pour répondre à ces besoins, comme le montre la figure
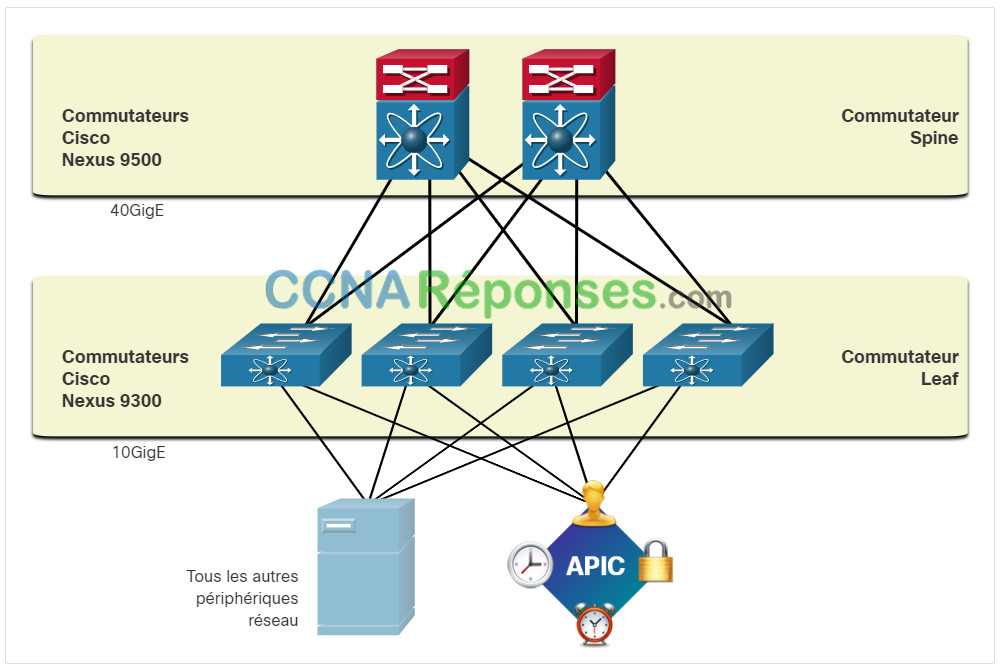
13.5.4 Topologie Spine-Leaf
Comme le montre la figure, le fabric Cisco ACI se compose du contrôleur APIC et des commutateurs Cisco Nexus 9000 dans une topologie Spine-Leaf à deux niveaux. Les commutateurs Leaf sont toujours associés à des commutateurs Spine, mais ne le sont jamais entre eux. De même, les commutateurs Spine sont uniquement associés à des commutateurs Leaf et centraux (non représentés). Dans cette topologie à deux niveaux, tous les éléments ne sont qu’à un « saut » les uns des autres.
Les contrôleurs Cisco APIC et tous les autres périphériques présents sur le réseau sont connectés physiquement aux commutateurs Leaf.
Contrairement à ce qui se passe dans une infrastructure SDN, le contrôleur APIC ne manipule pas directement le chemin des données. Au lieu de cela, il centralise la définition des stratégies et programme les commutateurs Leaf de manière à ce qu’ils transfèrent le trafic en fonction des politiques définies.
13.5.5 Types d’architecture SDN
Le module Cisco APIC-EM (Application Policy Infrastructure Controller – Enterprise Module) permet d’étendre l’infrastructure ACI aux campus et réseaux d’entreprise. Pour mieux comprendre en quoi consiste APIC-EM, prenons le temps d’examiner les trois types d’architecture SDN.
Cliquez sur chaque type de SDN pour obtenir plus d’informations.
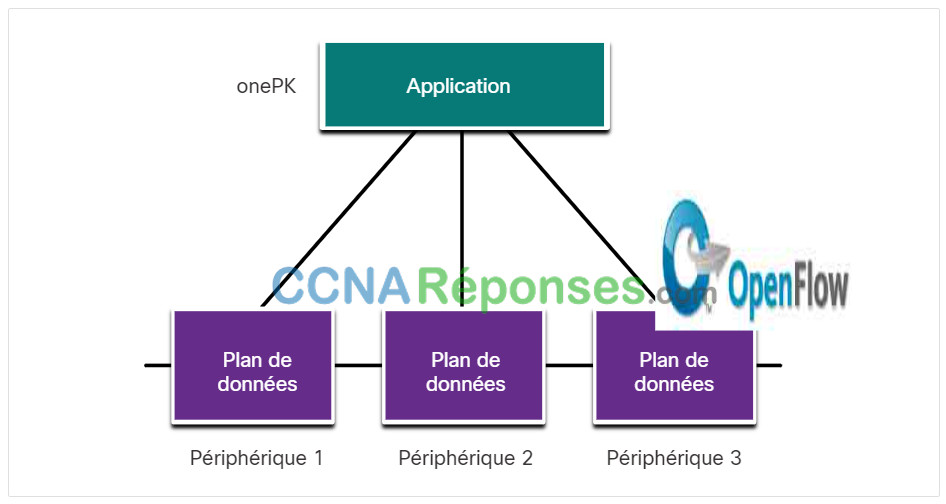
Dans ce type de SDN, les appareils sont programmables par des applications s'exécutant sur l'appareil lui-même ou sur un serveur du réseau, comme le montre la figure. Cisco OnePK est un exemple de SDN basé sur les périphériques. Il permet aux programmeurs de développer des applications en C et Java avec Python pour qu'elles s'intègrent et interagissent avec les périphériques Cisco.
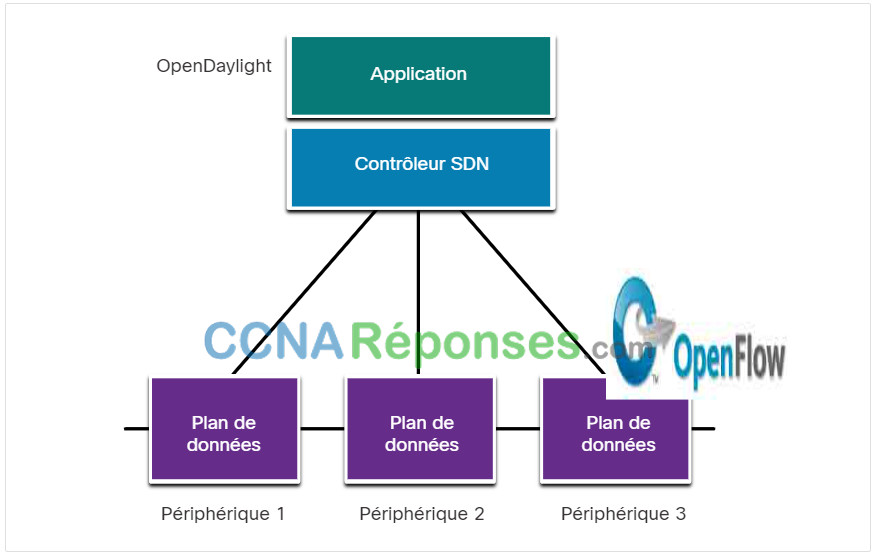
Ce type de SDN utilise un contrôleur centralisé qui connaît tous les appareils du réseau, comme le montre la figure. Les applications peuvent interagir avec le contrôleur, chargé de gérer les périphériques et de manipuler les flux de trafic sur le réseau. Le contrôleur Cisco Open SDN est une distribution commerciale d'OpenDaylight.
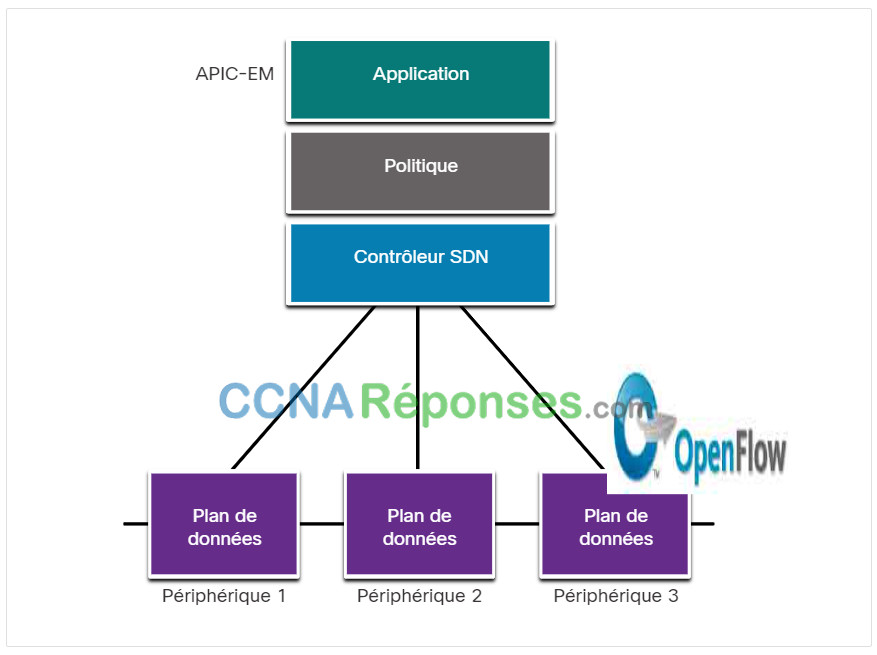
Ce type de SDN est similaire au SDN basé sur un contrôleur où un contrôleur centralisé a une vue sur tous les appareils du réseau, comme le montre la figure. Le SDN basé sur des politiques comprend une couche stratégique supplémentaire qui fonctionne à un niveau d'abstraction supérieur. Il utilise des applications intégrées qui automatisent les tâches de configuration avancée grâce à un workflow guidé et à une interface graphique utilisateur conviviale. Aucune compétence de programmation n'est nécessaire. Le contrôleur Cisco APIC-EM est un exemple de ce type de SDN.
13.5.6 Caractéristiques d’APIC-EM
Chaque type de SDN a ses propres fonctionnalités et avantages. Le SDN basé sur des politiques constitue l’approche la plus robuste, dans la mesure où il offre une méthode simple pour le contrôle et la gestion des politiques à l’échelle du réseau.
Cisco APIC-EM est un exemple de SDN basé sur des politiques. Cisco APIC-EM fournit une interface unique pour la gestion du réseau, notamment :
- la découverte et l’accès aux inventaires de périphériques et d’hôtes,
- affichage de la topologie (comme illustré sur la figure),
- le suivi d’un tracé entre les points d’extrémité et
- définition de stratégies.
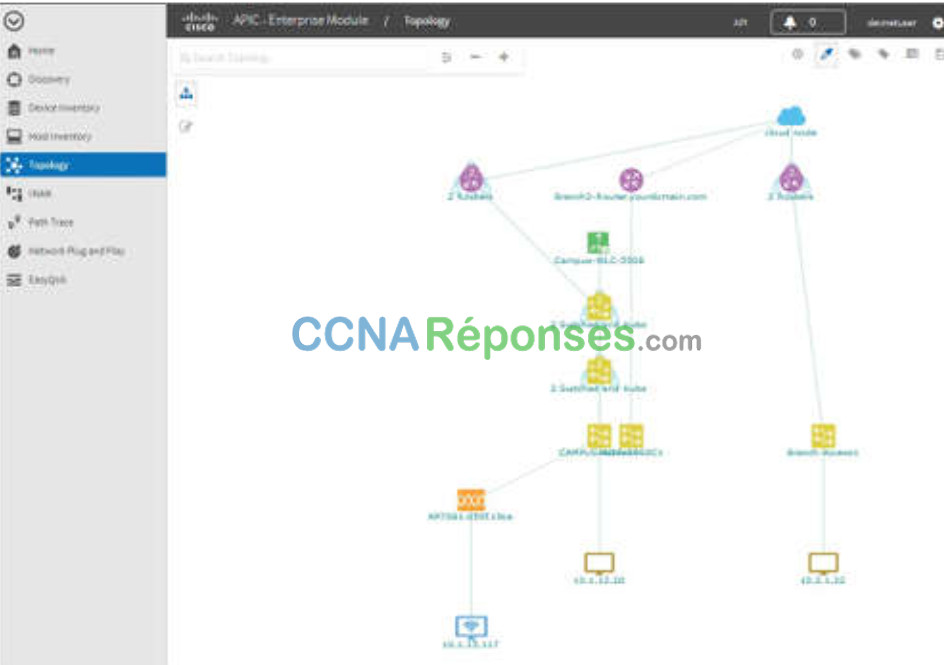
13.5.7 Tracé du chemin APIC-EM
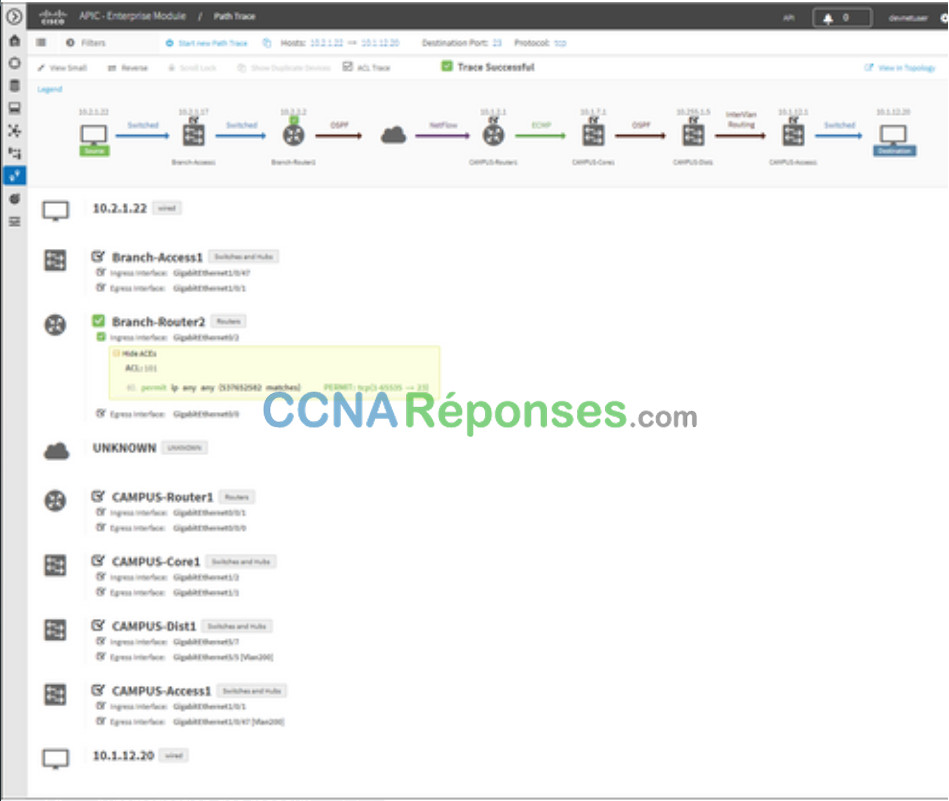
L’outil APIC-EM Path Trace permet à l’administrateur de visualiser facilement les flux de trafic et de découvrir toute entrée de ACL conflictuelle, dupliquée ou occultée. Cet outil examine des ACL spécifiques sur le chemin entre deux nœuds finaux et répertorie les problèmes éventuels. Vous pouvez voir où toutes les ACL le long du chemin d’accès autorisaient ou refusaient votre trafic, comme indiqué sur la figure. Notez comment Branch-Router2 est permis tout le trafic. L’administrateur réseau peut désormais effectuer des ajustements, si nécessaire, pour mieux filtrer le trafic.
13.6 Module pratique et questionnaire
13.6.1 Travaux pratiques – Installation de Linux sur un ordinateur virtuel et exploration de l’interface
Au cours de ces travaux pratiques, vous installerez le système d’exploitation Linux sur un ordinateur virtuel à l’aide d’une application de virtualisation du poste de travail, comme VirtualBox. Une fois l’installation terminée, vous explorerez l’interface utilisateur.
13.6.2 Qu’est-ce que j’ai appris dans ce module?
Cloud Computing
Le cloud computing implique un grand nombre d’ordinateurs connectés via un réseau qui peut être situé physiquement n’importe où. Le cloud computing permet de réduire les coûts opérationnels en optimisant l’utilisation des ressources. Le cloud computing aborde toute une série de questions relatives à la gestion des données :
- Il permet d’accéder aux données de l’entreprise partout, à tout moment.
- Il rationalise les opérations IT de l’entreprise en permettant de s’abonner uniquement aux services requis.
- Il élimine ou réduit le besoin d’équipements IT, de maintenance et de gestion sur site.
- Il réduit les coûts d’équipement, d’énergie, les besoins en installations physiques et les besoins en formation du personnel.
- Il permet de répondre rapidement aux exigences liées au volume croissant des données.
Les trois principaux services de cloud computing définis par le National Institute of Standards and Technology (NIST) sont Software as a Service (SaaS), Platform as a Service (PaaS) et Infrastructure as a Service (IaaS). Avec le SaaS, le fournisseur de cloud computing est responsable de l’accès aux applications et aux services, tels que le courrier électronique, la communication et Office 365, qui sont fournis sur Internet. Avec le PaaS, le fournisseur de cloud computing est chargé de fournir aux utilisateurs un accès aux outils et services de développement utilisés pour fournir les applications. Avec IaaS, le fournisseur de cloud computing est chargé de donner aux responsables informatiques l’accès à l’équipement réseau, aux services réseau virtualisés et au soutien de l’infrastructure réseau. Les quatre types de clouds sont les suivants : public, privé, hybride et communautaire. Les applications et les services proposés par un cloud public sont accessibles par tous. Les applications et les services proposés par un cloud privé sont destinés à une entreprise ou une entité spécifique, comme un gouvernement. Un cloud hybride est constitué de deux ou plusieurs nuages (exemple : partie privée, partie publique), où chaque partie reste un objet distinct, mais où les deux sont reliés par une architecture unique. Un cloud communautaire est créé pour l’usage exclusif d’une communauté spécifique.
Virtualisation
Bien qu’on les confonde souvent, les termes « cloud computing » et « virtualisation » font référence à des concepts bien différents. La virtualisation forme le socle du cloud computing. La virtualisation sépare le système d’exploitation (OS) du matériel. Historiquement, les serveurs d’entreprise consistaient en un système d’exploitation de serveur, tel que Windows Server ou Linux Server, installé sur un matériel spécifique. Toute la mémoire vive, la puissance de traitement et l’espace disque dur d’un serveur étaient dédiés à ce service. Lorsqu’un composant tombe en panne, le service fourni par ce serveur devient indisponible. C’est ce qu’on appelle un « point de défaillance unique ». Un autre problème des serveurs dédiés est qu’ils restent souvent inactifs pendant de longues périodes, attendant qu’il soit nécessaire de fournir le service spécifique qu’ils fournissent. Cela gaspille l’énergie et les ressources (étalement des serveurs). Les entreprises ont besoin de moins d’espace et d’équipements, et consomment moins d’énergie. Il permet un prototypage plus facile, un approvisionnement plus rapide des serveurs, une augmentation du temps de fonctionnement des serveurs, une meilleure reprise après sinistre et une prise en charge des anciens systèmes. Un système informatique se compose des couches d’abstraction suivantes : services, système d’exploitation, micrologiciels et matériel. Un hyperviseur de type 1 est installé directement sur le serveur ou le matériel de mise en réseau, Un hyperviseur de type 2 est un logiciel qui crée et exécute des instances de VM. Il peut être installé sur le dessus du système d’exploitation ou entre le microprogramme et le système d’exploitation. Un hyperviseur de type 2 est un logiciel qui crée et exécute des instances de VM.
Infrastructure de réseau virtuel
Les hyperviseurs de type 1 sont également dits « sans système d’exploitation », car ils sont installés directement sur le matériel. Les hyperviseurs de type 1 ont un accès direct aux ressources matérielles et sont plus efficaces que les architectures hébergées. Ils améliorent les performances, l’évolutivité et la robustesse. La gestion des hyperviseurs de type 1 nécessite en effet une « console de gestion ». Le logiciel de gestion permet de gérer plusieurs serveurs utilisant le même hyperviseur. La console de gestion peut automatiquement consolider les serveurs et les mettre hors/sous tension, le cas échéant. La console de gestion permet une reprise en cas de panne matérielle. Certaines consoles de gestion permettent également la surallocation du serveur. La virtualisation des serveurs dissimule aux utilisateurs les ressources des serveurs, telles que le nombre et l’identité des serveurs physiques, des processeurs et des systèmes d’exploitation. Cette situation peut soulever des problèmes lorsque le data center repose sur des architectures réseau traditionnelles. La virtualisation pose un autre problème : les flux de trafic diffèrent sensiblement du modèle client-serveur traditionnel. En règle générale, un centre de données a une quantité considérable de trafic échangé entre des serveurs virtuels. Ces flux sont appelés trafic est-ouest et peuvent changer de lieu et d’intensité au fil du temps. Le trafic nord-sud se produit entre les couches de distribution et de base et est généralement destiné à des emplacements hors site tels qu’un autre centre de données, d’autres fournisseurs de services en nuage ou l’internet.
Mise en réseau définie par logiciel
Deux architectures réseau majeures ont été développées pour prendre en charge la virtualisation réseau : Software-Defined Networking (SDN) et Cisco Application Centric Infrastructure (ACI). Le SDN (Software-Defined Networking) est une approche où le réseau est programmable à distance par logiciel. Les composants de SDN peuvent inclure OpenFlow, OpenStack et d’autres composants. Le contrôleur SDN est une entité logique qui permet aux administrateurs réseau de gérer et de définir la manière dont le plan de données des routeurs et des commutateurs virtuels doit gérer le trafic réseau. Un périphérique réseau contient un plan de contrôle et un plan de données. Plan de contrôle : considéré comme le cerveau d’un périphérique, le plan de contrôle permet de prendre les décisions de transmission. Il comprend des mécanismes de transmission d’itinéraire de couche 2 et 3, notamment la table de voisinage et la table topologique (protocole de routage), la table de routage pour IPv4 et IPv6, le protocole STP et la table ARP. Les informations envoyées à l’avion de contrôle, sont traitées par l’unité centrale. Le plan de données, également appelé plan d’acheminement, est généralement la structure de commutation qui relie les différents ports du réseau sur un appareil. Le plan de données de chaque périphérique permet de transmettre les flux de trafic. Les routeurs et les commutateurs utilisent les informations du plan de contrôle pour transmettre le trafic entrant vers l’interface de sortie appropriée. Les informations dans le plan de données sont généralement traitées par un processeur spécial du plan de données sans que l’unité centrale n’intervienne. Cisco Express Forwarding (CEF) utilise le plan de contrôle et le plan de données pour traiter les paquets. Cisco Express Forwarding est une technologie avancée de commutation IP au niveau de la couche 3 qui permet de transmettre des paquets à partir du plan de données sans consulter le plan de contrôle. Le SDN est essentiellement la séparation du plan de contrôle et du plan de données. Pour virtualiser le réseau, la fonction de plan de contrôle est supprimée sur chaque périphérique et centralisée sur un contrôleur unique. Le contrôleur centralisé communique les fonctions de plan de contrôle à chaque périphérique. Le plan de gestion est responsable de la gestion d’un périphérique via sa connexion au réseau. Les administrateurs réseau utilisent des applications telles que Secure Shell (SSH), Trivial File Transfer Protocol (TFTP), Secure FTP et Secure Hypertext Transfer Protocol (HTTPS) pour accéder au plan de gestion et configurer un appareil. Des protocoles comme SNMP (Simple Network Management Protocol) utilisent le plan de gestion.
Contrôleurs
Le contrôleur SDN est une entité logique qui permet aux administrateurs réseau de gérer et de définir la manière dont le plan de données des routeurs et des commutateurs virtuels doit gérer le trafic réseau. Le contrôleur SDN définit les flux de données entre le plan de contrôle centralisé et les plans de données sur les routeurs et les commutateurs individuels. Pour pouvoir traverser le réseau, chaque flux doit être approuvé par le contrôleur SDN qui vérifie que la communication est autorisée dans le cadre de la politique réseau de l’entreprise. Si le contrôleur autorise le flux, il calcule l’itinéraire que ce dernier doit suivre et ajoute une entrée correspondante au flux dans tous les commutateurs situés sur le trajet. Le contrôleur alimente les tables de flux. Les commutateurs gèrent les tables de flux. Un tableau de flux fait correspondre les paquets entrants à un flux particulier et spécifie les fonctions qui doivent être exécutées sur les paquets. Il peut y avoir plusieurs tables de flux qui fonctionnent à la manière d’un pipeline. Un tableau de flux peut diriger un flux vers un tableau de groupe, ce qui peut déclencher une série d’actions qui affectent un ou plusieurs flux. Une table de compteur déclenche une variété d’actions liées aux performances sur un flux, y compris la possibilité de limiter le trafic. Cisco a développé l’infrastructure axée sur les applications (ACI) pour leur permettre d’atteindre ces objectifs à l’aide d’une méthode plus avancée et innovante que les approches SDN antérieures. Cisco ACI est une solution matérielle spécialisée offrant une gestion intégrée du cloud computing et du centre de données. Au niveau global, tout élément relatif à la politique du réseau est retiré du plan de données. Cela permet de créer beaucoup plus facilement les réseaux de data center. Les trois principaux composants de l’architecture ACI sont l’Application Network Profile (ANP), l’Application Policy Infrastructure Controller (APIC) et les commutateurs Cisco Nexus de la série 9000. La structure Cisco ACI est composée de l’APIC et des commutateurs de la série Cisco Nexus 9000 utilisant une topologie à deux niveaux. Contrairement à ce qui se passe dans une infrastructure SDN, le contrôleur APIC ne manipule pas directement le chemin des données. Au lieu de cela, il centralise la définition des stratégies et programme les commutateurs Leaf de manière à ce qu’ils transfèrent le trafic en fonction des politiques définies. Il existe trois types de SDN. SDN basé sur les appareils : les appareils peuvent être programmés par les applications qui s’exécutent sur les appareils eux-mêmes ou sur un serveur du réseau. SDN basé sur les contrôleurs : cette architecture repose sur un contrôleur centralisé qui connaît tous les appareils du réseau. SDN basé sur des politiques : type de SDN similaire à un SDN basé sur un contrôleur dans lequel un contrôleur central reconnaît tous les périphériques présents sur le réseau. Le SDN basé sur des politiques comprend une couche stratégique supplémentaire qui fonctionne à un niveau d’abstraction supérieur. Le SDN basé sur des politiques constitue l’approche la plus robuste, dans la mesure où il offre une méthode simple pour le contrôle et la gestion des politiques à l’échelle du réseau. Cisco APIC-EM est un exemple de SDN basé sur des politiques. Cisco APIC-EM fournit une interface unique pour la gestion du réseau, y compris la découverte et l’accès aux inventaires de périphériques et d’hôtes, la visualisation de la topologie, le traçage d’un chemin entre les points d’extrémité et la définition de politiques. L’outil APIC-EM Path Trace permet à l’administrateur de visualiser facilement les flux de trafic et de découvrir toute entrée de ACL conflictuelle, dupliquée ou occultée. Cet outil examine des ACL spécifiques sur le chemin entre deux nœuds finaux et répertorie les problèmes éventuels.