12.0 Introduction
12.0.1 Pourquoi devrais-je suivre ce module?
Bienvenue au dépannage du réseau !
Qui est le meilleur administrateur réseau que vous ayez jamais vu ? Pourquoi pensez-vous que cette personne est si douée ? Probablement, c’est parce que cette personne est vraiment bonne pour résoudre les problèmes réseau. Ce sont probablement des administrateurs expérimentés, mais ce n’est pas toute l’histoire. Les bons dépanneurs réseau le font généralement de manière méthodique, et ils utilisent tous les outils à leur disposition.
La vérité est que la seule façon de devenir un bon dépanneur de réseau est de toujours être dépanneur. Il faut du temps pour être doué à ça. Mais heureusement pour vous, il y a beaucoup, beaucoup de conseils et d’outils que vous pouvez utiliser. Ce module couvre les différentes méthodes de dépannage réseau et tous les conseils et outils dont vous avez besoin pour démarrer. Ce module dispose également de deux très bonnes activités Packet Tracer pour tester vos nouvelles compétences et connaissances. Peut-être que votre objectif devrait être de devenir le meilleur administrateur réseau que quelqu’un d’autre ait jamais vu !
12.0.2 Qu’est-ce que je vais apprendre dans ce module?
Titre du module: Dépannage réseau
Objectif du module: Dépanner les réseaux d’entreprise.
| Titre du rubrique | Objectif du rubrique |
|---|---|
| Documentation du réseau | Expliquer comment la documentation réseau est établie et utilisée pour résoudre les problèmes de réseau. |
| Procédure de dépannage | Comparer les méthodes de dépannage qui utilisent une approche systématique et en couches. |
| Outils de dépannage | Décrire les différents outils de dépannage du réseau. |
| Symptômes et causes des problèmes de réseau | Déterminer les symptômes et les causes des problèmes réseau à l’aide d’un modèle en couches. |
| Dépannage de la connectivité IP | Dépanner un réseau à l’aide du modèle en couches. |
12.1 Documentation du réseau
12.1.1 Aperçu de la documentation
Comme pour toute activité complexe comme le dépannage réseau, vous devrez commencer par une bonne documentation. Une documentation réseau précise et complète est nécessaire pour surveiller et dépanner efficacement les réseaux.
La documentation réseau commune comprend les éléments suivants :
- Diagrammes de topologie du réseau physique et du réseau logique
- Documentation sur les périphériques réseau qui enregistre toutes les informations pertinentes sur les périphériques
- Documentation de référence sur les performances réseau
Toute la documentation du réseau doit être conservée en un seul endroit, soit sous forme de copie papier, soit sur le réseau, sur un serveur protégé. La documentation de sauvegarde doit quant à elle être conservée à un autre endroit.
12.1.2 Diagrammes de topologie réseau
Les schémas de topologie réseau indiquent l’emplacement, la fonction et l’état des périphériques présents sur le réseau. Il existe deux types de schémas de topologie réseau, à savoir les schémas de topologie physique et les schémas de topologie logique.
Cliquez sur chaque bouton pour obtenir un exemple et une explication des topologies physiques et logiques.
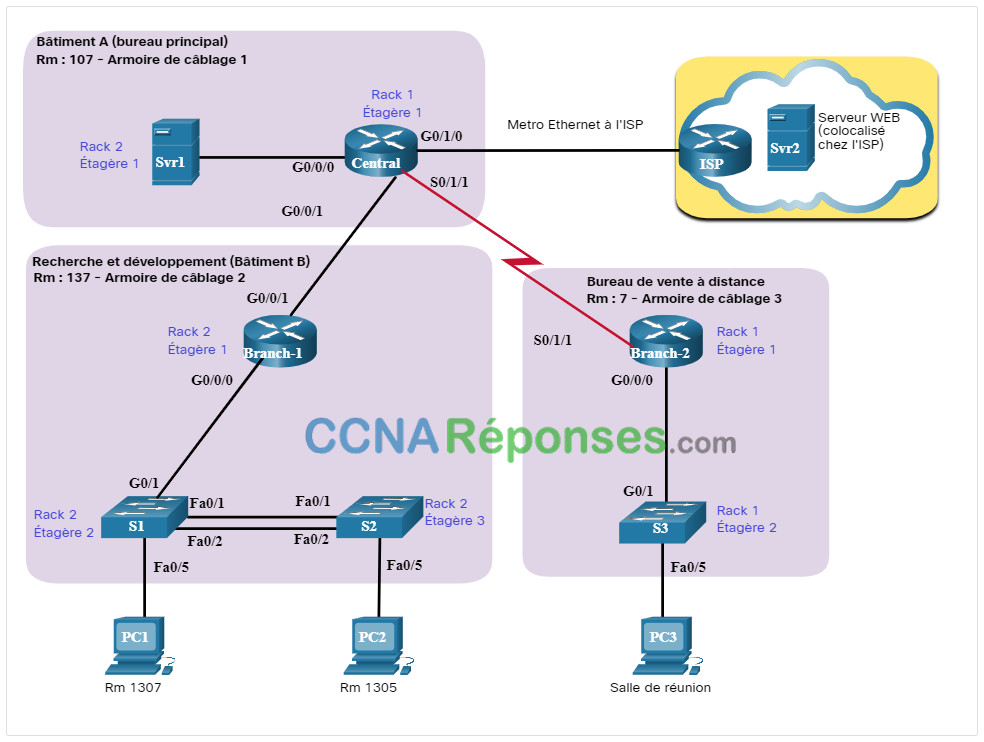
Un diagramme physique du réseau indique la disposition physique des périphériques connectés au réseau. Vous devez savoir comment les appareils sont physiquement connectés pour dépanner les problèmes de la couche physique. Les informations enregistrées sur la topologie physique comprennent généralement les suivantes :
- Nom du périphérique
- Emplacement de l'appareil (adresse, numéro de pièce, emplacement du rack)
- Interface et ports utilisés
- Type de câble
La figure montre un exemple de diagramme de topologie de réseau physique.
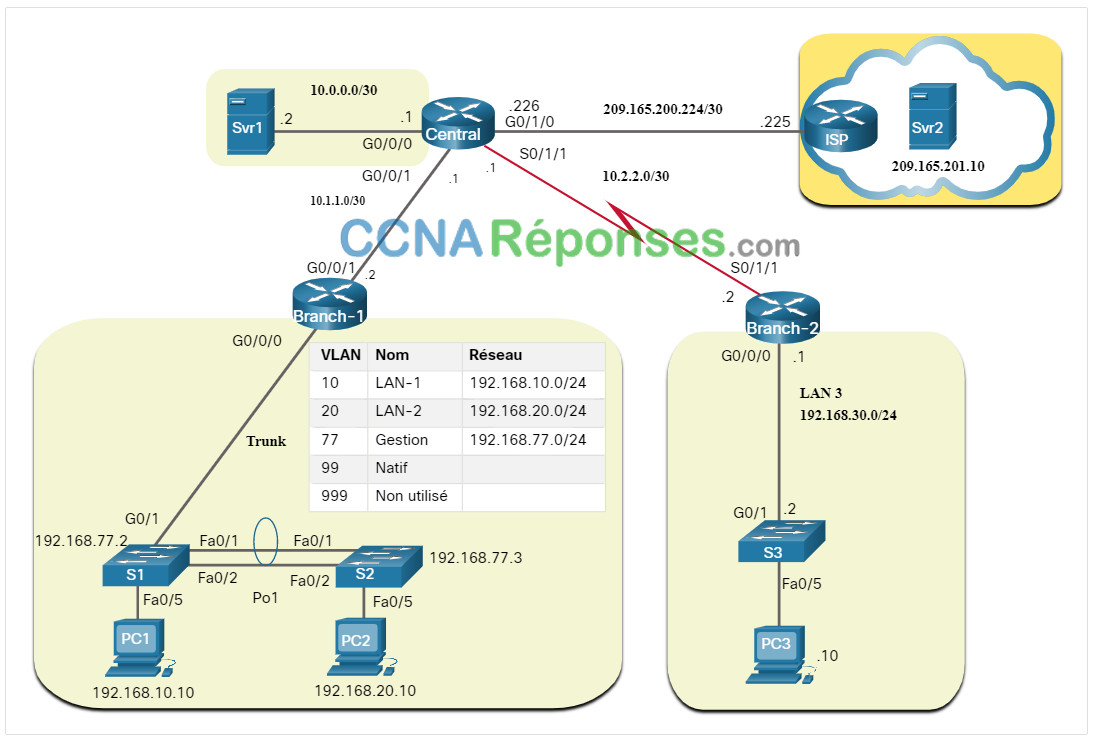
Une topologie de réseau logique illustre la façon dont les appareils sont logiquement connectés au réseau. Il s'agit de la manière dont les appareils transfèrent des données sur le réseau lorsqu'ils communiquent avec d'autres appareils. Les symboles sont utilisés pour représenter les composants du réseau, tels que les routeurs, les commutateurs, les serveurs et les hôtes. De plus, les connexions entre divers sites peuvent être affichées, mais sans toutefois indiquer les emplacements physiques réels.
Les informations enregistrées sur une topologie de réseau logique peuvent comprendre les éléments suivants :
- Identificateurs de périphériques
- Adresses IP et longueur des préfixes
- Identificateurs d’interfaces
- Protocoles de routage / routes statiques
- Informations sur la couche 2 (VLAN, circuits, EtherChannels)
La figure présente un exemple de topologie logique de réseau IPv4.
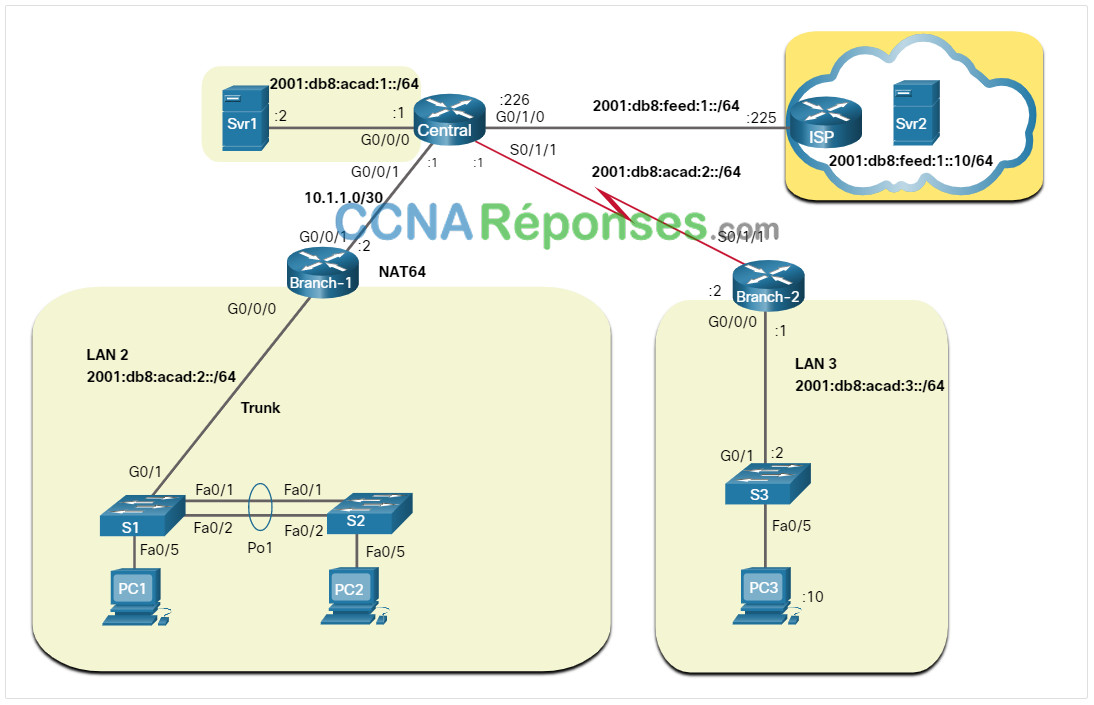
Bien que les adresses IPv6 puissent également être affichées dans la même topologie logique IPv4, par souci de clarté, nous avons créé une topologie de réseau IPv6 logique distincte.
La figure présente un exemple de topologie logique IPv6.
12.1.3 Documentation sur les périphériques réseau
La documentation relative aux dispositifs de réseau doit contenir des enregistrements précis et actualisés du matériel et des logiciels de réseau. La documentation doit inclure toutes les informations pertinentes sur les périphériques réseau.
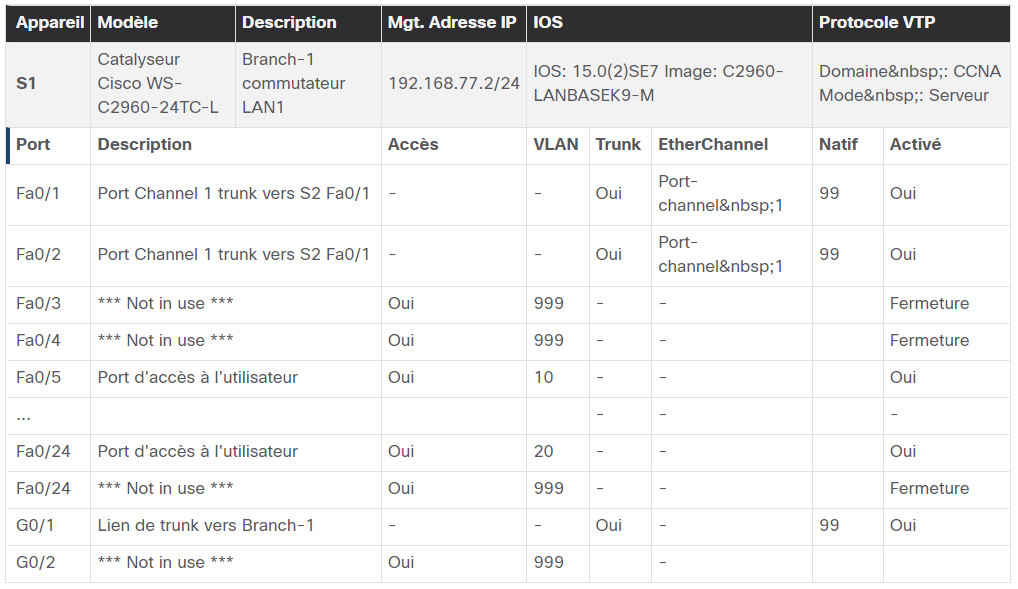
De nombreuses organisations créent des documents avec des tableaux ou des feuilles de calcul pour capturer les informations pertinentes sur les appareils.
Cliquez sur chaque bouton pour obtenir des exemples de documentation sur le routeur, le commutateur et le périphérique final.
- Documentation sur les périphériques de routage
- Documentation sur les périphériques des commutateurs LAN
- Documentation du système terminal
Le tableau présente un exemple de documentation sur les périphériques réseau pour deux routeurs d'interconnexion.

Ce tableau présente un exemple de documentation sur les périphériques d'un commutateur LAN.
Les fichiers de configuration du système terminal concernent principalement le matériel et les logiciels utilisés au niveau des périphériques du système terminal, tels que les serveurs, les consoles de gestion du réseau et les stations de travail utilisateur. Un système terminal incorrectement configuré peut nuire aux performances globales d'un réseau. Pour cette raison, avoir accès à la documentation des périphériques du système final peut être très utile lors du dépannage.
Ce tableau présente un exemple d'informations pouvant être enregistrées dans un document de périphérique du système final.

12.1.4 Établir une base de référence pour le réseau
Le but de la surveillance d’un réseau est de comparer ses performances à une planification initiale prédéfinie. Une ligne de base est utilisée pour établir les performances normales d’un réseau ou d’un système afin de déterminer la « personnalité » d’un réseau dans des conditions normales.
L’établissement d’une planification initiale des performances réseau nécessite la collecte de données de performances à partir des ports et des périphériques essentiels au fonctionnement du réseau.
Une base de référence de réseau devrait répondre aux questions suivantes :
- Quelles sont les performances du réseau pendant une journée normale ou moyenne ?
- Où survient le plus grand nombre d’erreurs ?
- Quelle partie du réseau est la plus utilisée ?
- Quelle partie du réseau est la moins utilisée ?
- Quels appareils doivent être surveillés et quels seuils d’alerte doivent être définis ?
- Le réseau peut-il satisfaire les politiques identifiées ?
La mesure des performances initiales et de la disponibilité des appareils et des liens critiques du réseau permet à un administrateur de réseau de déterminer la différence entre un comportement anormal et les performances correctes du réseau, à mesure que le réseau se développe ou que les schémas de trafic changent. La base de référence permet également de déterminer si la conception actuelle du réseau peut répondre aux besoins des entreprises. Sans base de référence, il n’existe aucune norme pour mesurer la nature optimale du trafic sur le réseau et les niveaux de congestion.
L’analyse après une première base de référence tend également à révéler des problèmes cachés. Les données collectées permettent d’identifier la nature de l’encombrement réel ou potentiel d’un réseau. Elle peut également révéler des domaines du réseau qui sont sous-utilisés, et peut très souvent conduire à des efforts de reconception du réseau, sur la base d’observations de la qualité et des capacités.
L’établissement du point de référence initial des performances réseau est l’étape qui permet de mesurer les effets des modifications du réseau et les efforts de dépannage ultérieurs. Il est donc important de la planifier avec soin.
12.1.5 Étape 1 – Déterminer les types de données à collecter
Lors de la réalisation de la planification initiale, commencez par sélectionner quelques variables représentant les stratégies définies. Si vous sélectionnez trop de points de données, la quantité de données peut être trop importante, rendant difficile l’analyse des données recueillies. Commencez par quelques données seulement et affinez votre choix au fur et à mesure. Quelques bonnes variables de départ sont l’utilisation de l’interface et l’utilisation du CPU.
12.1.6 Étape 2 – Identifier les dispositifs et les ports d’intérêt
Utilisez la topologie du réseau pour identifier les périphériques et les ports pour lesquels il est nécessaire de mesurer des données de performances. Les dispositifs et les ports d’intérêt sont notamment les suivants :
- Ports des périphériques réseau qui se connectent à d’autres périphériques réseau
- Serveurs
- les utilisateurs principaux
- Tout autre élément considéré comme étant critique pour le fonctionnement du système
Une topologie de réseau logique peut être utile pour identifier les principaux appareils et ports à surveiller. Dans la figure, l’administrateur réseau a mis en évidence les appareils et les ports d’intérêt à surveiller pendant le test de base.
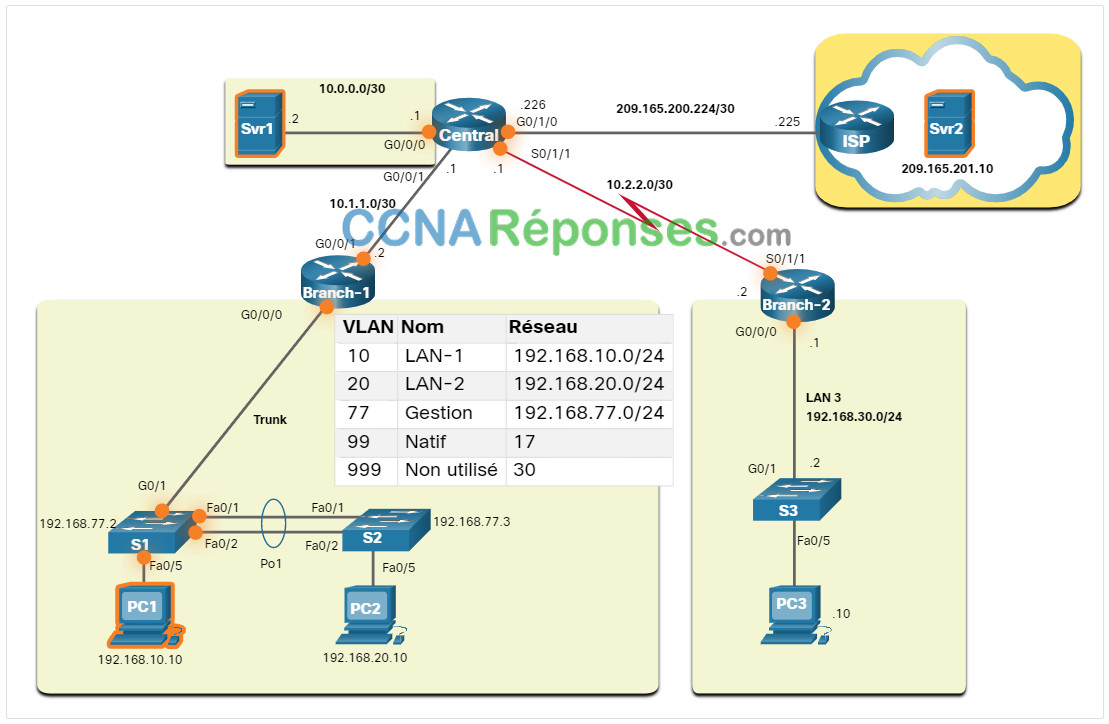
Les périphériques d’intérêt comprennent le PC1 (le terminal Admin), et les deux serveurs (c’est-à-dire Srv1 et Svr2). Les ports d’intérêt incluent généralement des interfaces de routeur et des ports clés sur les commutateurs.
En diminuant le nombre de ports à interroger, on peut obtenir des résultats plus concis et minimiser ainsi la charge de gestion du réseau. Rappelez-vous que l’interface d’un routeur ou d’un commutateur peut être une interface virtuelle, comme un périphérique SVI (interface virtuelle de commutateur).
12.1.7 Étape 3 – Déterminer la durée de base
La durée et les informations de base recueillies doivent être suffisamment longues pour déterminer une image « normale » du réseau. Il est important de surveiller les tendances quotidiennes du trafic réseau. Il est également important de surveiller les tendances qui s’établissent sur une plus longue période, par exemple à l’échelle de la semaine ou du mois. Pour cette raison, lors de la capture de données à des fins d’analyse, il faut que la période spécifiée soit au minimum de sept jours.
La figure présente des exemples de plusieurs captures d’écran des tendances d’utilisation de l’unité centrale saisies sur une période quotidienne, hebdomadaire, mensuelle et annuelle.
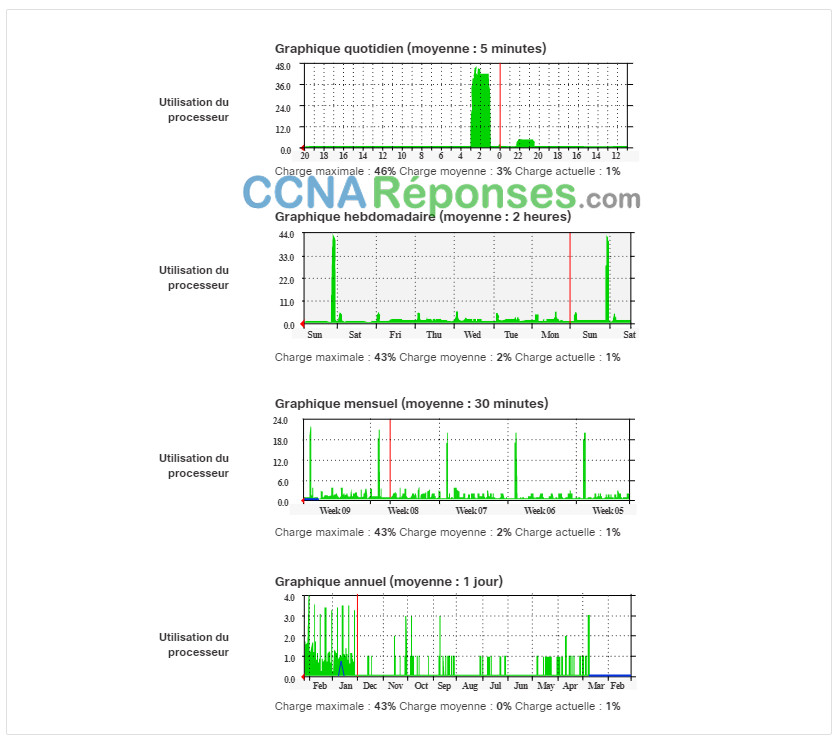
Dans cet exemple, notez que les tendances de la semaine de travail sont trop courtes pour révéler le pic d’utilisation récurrent qui se produit chaque week-end le samedi soir, lorsqu’une opération de sauvegarde des bases de données consomme une grande partie de la bande passante du réseau. Ce modèle récurrent est visible avec la tendance mensuelle. Une tendance annuelle, telle qu’affichée dans l’exemple, peut s’avérer insuffisante pour fournir des détails significatifs sur les performances de référence. Elle peut toutefois aider à identifier des tendances à long terme, pouvant être analysées ultérieurement.
D’une manière générale, une planification initiale ne doit pas s’étendre sur une période supérieure à six semaines, sauf si des tendances spécifiques à long terme doivent être mesurées. Une planification initiale de deux à quatre semaines est généralement tout à fait adéquate.
Les mesures de planification initiale ne doivent pas être réalisées durant les périodes de modèles de trafic uniques, car les données mesurées donneraient alors une image imprécise des conditions de fonctionnement normales du réseau. Analysez tous les ans l’ensemble du réseau ou déterminez la ligne de base de différentes sections du réseau les unes après les autres. L’analyse doit être effectuée régulièrement afin de pouvoir comprendre dans quelle mesure le réseau est affecté par sa croissance ainsi que par les autres modifications qui lui sont apportées.
12.1.8 Mesure des données
Lors de la documentation du réseau, il est souvent nécessaire de collecter des informations directement à partir des routeurs et des commutateurs. Les commandes utiles évidentes de la documentation du réseau comprennent ,ping, traceroute, et telnet, et ainsi que les commandes show.
La figure répertorie certaines des commandes Cisco IOS les plus fréquemment utilisées pour la collecte des données.
| Commande | Description |
|---|---|
show version |
Affiche le temps de fonctionnement, les informations sur la version des logiciels et du matériel |
show ip interface [brief] show ipv6 interface [brief] |
|
show interfaces |
|
show ip route show ipv6 route |
|
show cdp neighbors detail |
Affiche des informations détaillées sur le voisin Cisco directement connecté Cisco. |
show arp show ipv6 neighbors |
Affiche le contenu de la table ARP (IPv4) et de la table voisine (IPv6). |
show running-config |
Affichez la configuration en cours. |
show vlan |
Affiche l’état des VLAN sur un commutateur. |
show port |
Affiche l’état des ports sur un commutateur. |
show tech-support |
|
La collecte manuelle de données à l’aide de commandes show sur des dispositifs de réseau individuels est extrêmement longue et n’est pas une solution évolutive. La collecte manuelle de données doit être réservée aux petits réseaux ou limitée aux appareils réseau stratégiques. Dans le cas des réseaux de conception plus simple, les tâches de planification initiale impliquent généralement la combinaison d’une collecte manuelle de données et d’une inspection de base du protocole réseau.
Des logiciels de gestion de réseau évolués sont généralement utilisés pour établir la référence de grands réseaux complexes. Ces modules de logiciel permettent aux administrateurs de créer automatiquement et de consulter des rapports, de comparer les niveaux de performance actuels aux observations historiques, d’identifier automatiquement les problèmes de performance et de créer des alertes pour les applications qui ne fournissent pas les niveaux de service prévus.
Des heures ou des jours de travail peuvent être nécessaires pour établir une ligne de base initiale ou pour analyser le suivi des performances si l’on souhaite refléter avec précision les performances réseau. Des logiciels de gestion du réseau, des systèmes d’inspection de protocoles ou des analyseurs de paquets s’exécutent souvent en continu pendant le processus de collecte de données.
12.2 Procédure de dépannage
12.2.1 Procédures générales de dépannage
Le dépannage peut prendre du temps car les réseaux diffèrent, les problèmes diffèrent et l’expérience de dépannage varie. Cependant, les administrateurs expérimentés savent que l’utilisation d’une méthode de dépannage structurée réduira le temps global de dépannage.
Par conséquent, le processus de dépannage doit être guidé par des méthodes structurées. Cela nécessite des procédures de dépannage bien définies et documentées pour minimiser le temps perdu associé à un dépannage erratique (hit-and-miss). Cependant, ces méthodes ne sont pas statiques. Les étapes de dépannage prises pour résoudre un problème ne sont pas toujours identiques ou exécutées dans le même ordre.
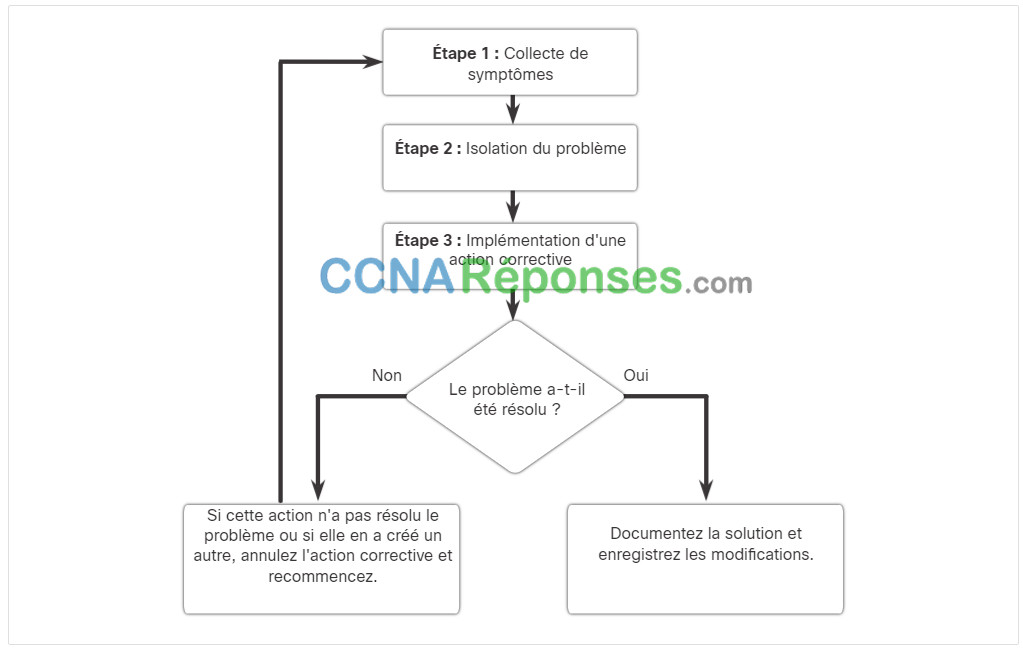
Plusieurs processus de dépannage peuvent être utilisés pour résoudre un problème. La figure montre l’organigramme logique d’un processus simplifié de dépannage en trois étapes. Cependant, un processus plus détaillé peut être plus utile pour résoudre un problème de réseau.
12.2.2 Processus de dépannage en sept étapes
La figure présente un processus de dépannage plus détaillé en sept étapes. Notez comment certaines étapes s’interconnectent. En effet, certains techniciens peuvent être en mesure de sauter d’une étape à l’autre en fonction de leur niveau d’expérience.
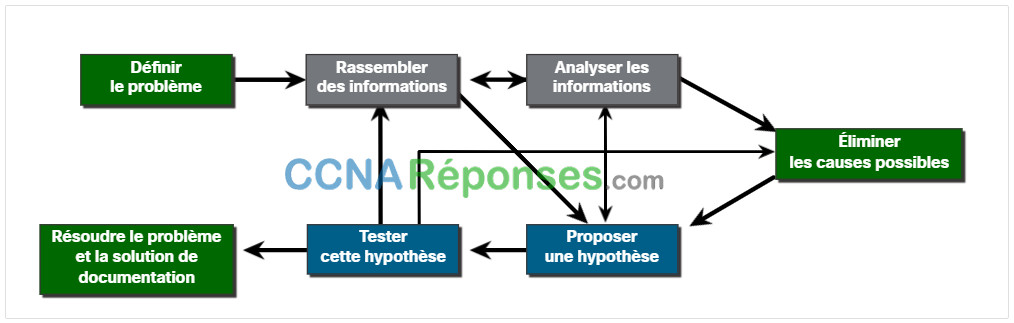
Cliquez sur chaque bouton pour obtenir une description détaillée des étapes à suivre pour résoudre un problème réseau.
12.2.3 Questionner les utilisateurs
De nombreux problèmes de réseau sont initialement signalés par un utilisateur final. Toutefois, les informations fournies sont souvent vagues ou trompeuses. Par exemple, les utilisateurs signalent souvent des problèmes tels que « le réseau est en panne », « Je ne peux pas accéder à mon courriel » ou « mon ordinateur est lent ».
Dans la plupart des cas, des informations supplémentaires sont nécessaires pour bien comprendre un problème. Cela implique généralement d’interagir avec l’utilisateur affecté pour découvrir le « qui », « quoi » et « quand » du problème.
Les recommandations suivantes doivent être utilisées lors de la communication avec l’utilisateur :
- Parler à un niveau technique qu’ils peuvent comprendre et éviter d’utiliser une terminologie complexe.
- Toujours écouter ou lire attentivement ce que l’utilisateur dit. Prendre des notes peut être utile pour documenter un problème complexe.
- Soyez toujours attentif et compatis avec les utilisateurs tout en leur faisant savoir que vous les aiderez à résoudre leur problème. Les utilisateurs qui signalent un problème peuvent être stressés et désireux de le résoudre le plus rapidement possible.
Lors de l’entretien avec l’utilisateur, guidez la conversation et utilisez des techniques d’interrogation efficaces pour déterminer rapidement le problème. Par exemple, utilisez les questions ouvertes (c.-à-d. nécessitant une réponse détaillée) et les questions fermées (c.-à-d. oui, non ou réponses à un seul mot) pour découvrir des faits importants sur le problème du réseau.
Le tableau fournit des directives de questionnement et des exemples de questions ouvertes aux utilisateurs finaux.
Lorsque vous avez interrogé l’utilisateur, répétez votre compréhension du problème à l’utilisateur afin de vous assurer que vous êtes tous les deux d’accord sur le problème signalé.
| Directives | Exemple de questions ouvertes aux utilisateurs finaux |
|---|---|
| Posez des questions pertinentes. |
|
| Déterminez l’étendue du problème. |
|
| Déterminez à quel moment le problème s’est produit/se produit. |
|
| Déterminez si le problème est constant ou intermittent. |
|
| Déterminez si quelque chose a changé. | Qu’est-ce qui a changé depuis la dernière fois que cela fonctionnait ? |
| Utilisez les questions pour éliminer ou découvrir d’éventuels problèmes. |
|
12.2.4 Informations utiles
Pour recueillir les symptômes d’un périphérique réseau suspect, utilisez les commandes IOS de Cisco et d’autres outils tels que les captures de paquets et les journaux de périphériques.
Le tableau de la Figure 2 décrit les commandes Cisco IOS courantes utilisées pour collecter les symptômes d’un problème réseau.
| Commande | Description |
|---|---|
ping {host | ip-address}
|
|
traceroute destination |
|
telnet {host | ip-address}
|
|
ssh -l user-id ip-address |
|
show ip interface brief show ipv6 interface brief |
|
show ip route show ipv6 route |
Affiche les tables de routage IPv4 et IPv6 actuelles, qui contiennent les routes vers toutes les destinations réseau connues |
show protocols |
Affiche les protocoles configurés et indique l’état global et spécifique à l’interface de tout protocole de couche 3 configuré |
debug |
Affiche une liste d’options pour activer ou désactiver les événements de débogage |
Remarque: Bien que la commande debug soit un outil important pour la collecte de symptômes, elle génère une grande quantité de trafic de messages de console et les performances d’un appareil réseau peuvent être sensiblement affectées. Si le debug doit être effectué pendant les heures de travail, avertissez les utilisateurs du réseau qu’une activité de dépannage est en cours et qu’elle risque d’affecter les performances du réseau. N’oubliez pas de désactiver le débogage lorsque vous avez terminé.
12.2.5 Dépannage avec les modèles en couches
Les modèles OSI et TCP/IP peuvent être appliqués pour isoler les problèmes de réseau lors du dépannage. Par exemple, si les symptômes font penser à un problème de connexion physique, le technicien réseau peut concentrer ses efforts sur le dépannage du circuit qui fonctionne au niveau de la couche physique.
La figure montre quelques dispositifs courants et les couches OSI qui doivent être examinées au cours du processus de dépannage pour ce dispositif.
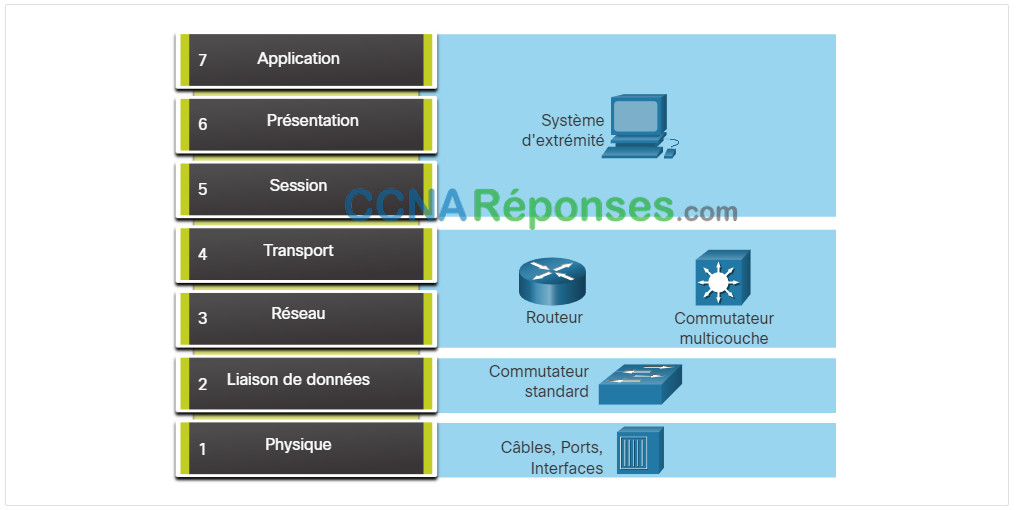
Notez que les routeurs et les commutateurs multicouches sont indiqués au niveau de la couche 4, à savoir la couche transport. Bien que les routeurs et les commutateurs multicouches prennent généralement leurs décisions de transmission au niveau de la couche 3, les listes de contrôle d’accès de ces périphériques peuvent être utilisées pour prendre des décisions de filtrage à l’aide des informations de couche 4.
12.2.6 Méthodes structurées de dépannage
Il existe plusieurs approches structurées de dépannage qui peuvent être utilisées. Le choix de l’un ou l’autre dépend de la situation. Chacune de ces approches présente ses avantages et ses inconvénients. Cette rubrique décrit les méthodes et fournit des lignes directrices pour choisir la meilleure méthode pour une situation spécifique.
Cliquez sur chaque bouton pour obtenir une description des différentes approches de dépannage qui peuvent être utilisées.
- Méthode ascendante
- Méthode descendante
- Diviser et conquérir
- Suivre le chemin
- Substitution
- Comparaison
- Devine instruite
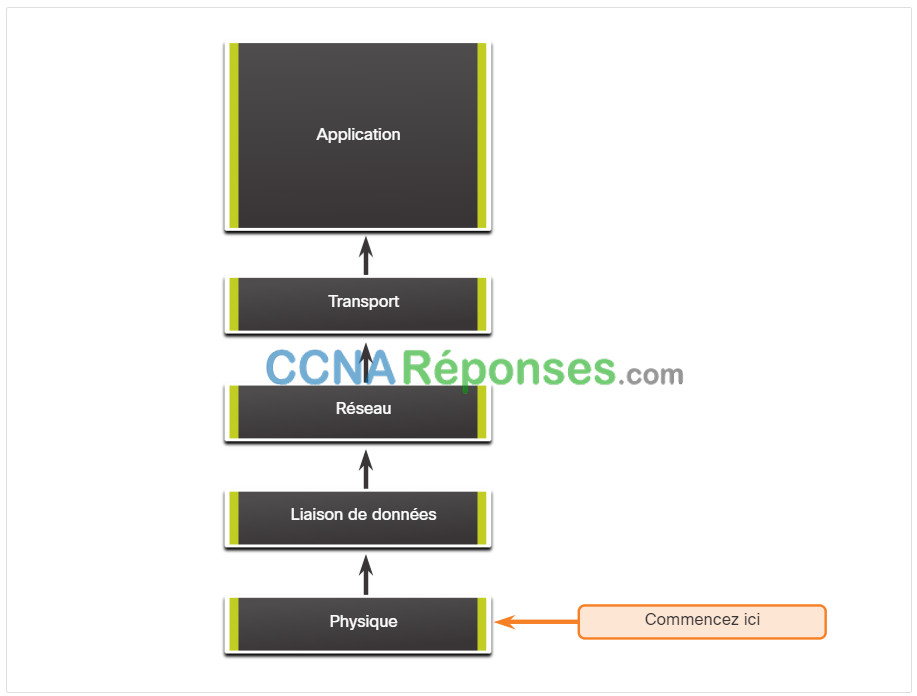
Dans le dépannage ascendant, vous commencez par les composants physiques du réseau et vous progressez à travers les couches du modèle OSI jusqu'à ce que la cause du problème soit identifiée, comme le montre la figure.
Cette approche est conseillée lorsque vous pensez que le problème est physique. La plupart des problèmes réseau se situent au niveau des couches inférieures, ce qui signifie que la mise en œuvre de l'approche ascendante est souvent efficace.
L'inconvénient de l'approche de dépannage ascendante est qu'elle nécessite la vérification de chacun des périphériques et de chacune des interfaces du réseau jusqu'à ce que la cause possible du problème ait été trouvée. N’oubliez pas que chaque conclusion et possibilité doit être documentée ; cela peut donc représenter un travail administratif important. Un autre défi consiste à déterminer quels périphériques examiner en premier lieu.
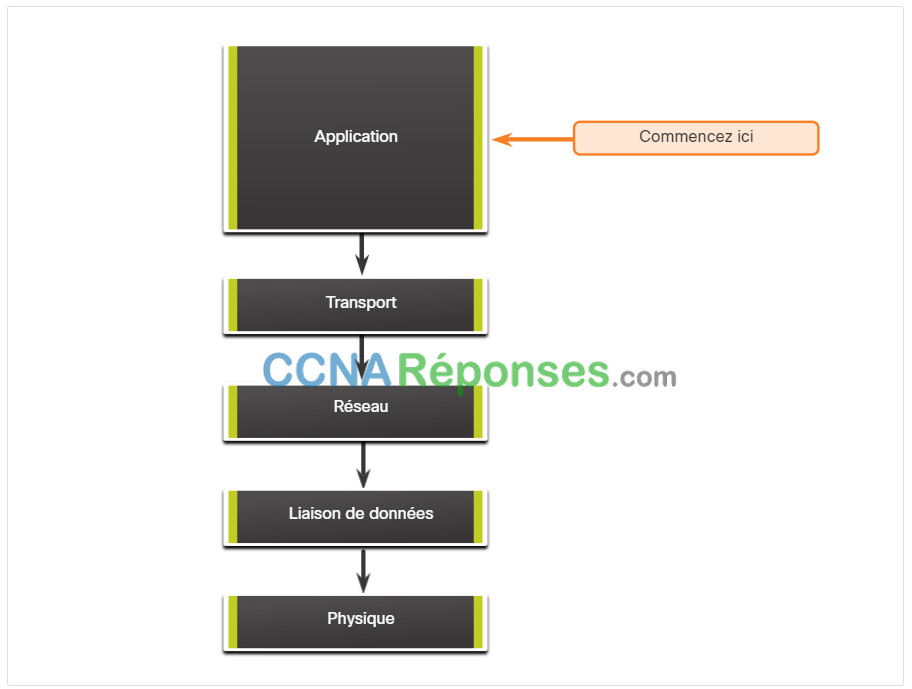
Dans la figure, le dépannage de haut en bas commence avec les applications de l'utilisateur final et descend à travers les couches du modèle OSI jusqu'à ce que la cause du problème ait été identifiée.
Les applications de l’utilisateur final d’un système d’extrémité sont testées avant de s’attaquer à des éléments plus précis du réseau. Utilisez cette approche pour les problèmes simples ou lorsque vous pensez que le problème concerne un élément logiciel.
L'inconvénient de l'approche descendante est qu'elle nécessite la vérification de chaque application réseau jusqu'à ce que la cause possible du problème ait été trouvée. Chaque conclusion et chaque possibilité doivent être documentées. Le défi consiste à déterminer quelle application examiner en premier lieu.
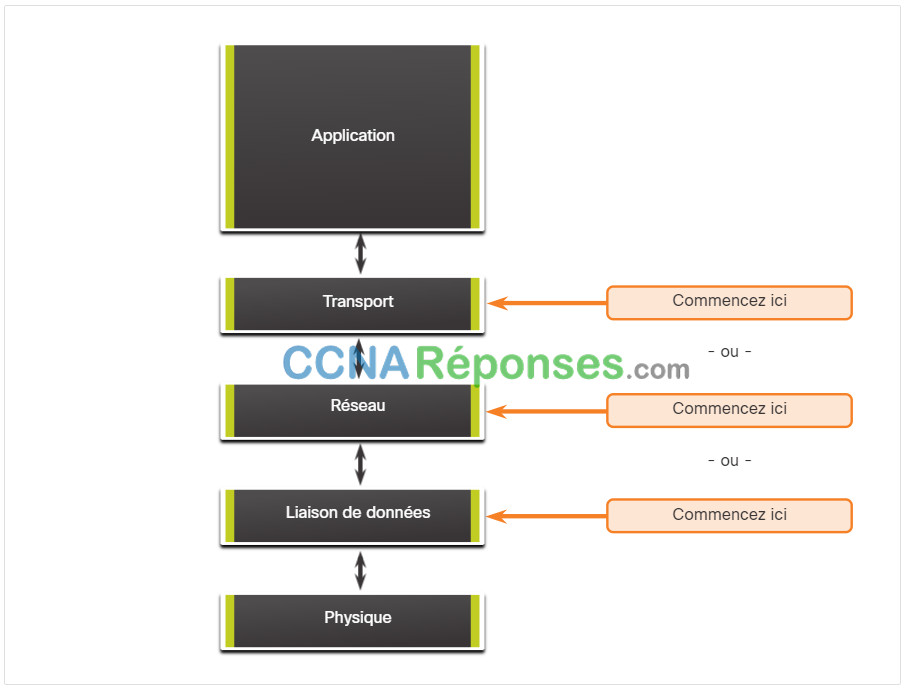
La figure montre l'approche "diviser pour mieux régner" pour résoudre un problème de réseau.
L'administrateur réseau sélectionne une couche et effectue des tests dans les deux sens à partir de cette couche.
Dans la méthode de dépannage « diviser et conquérir », vous commencez par collecter les expériences utilisateur du problème, vous documentez les symptômes, puis, à l'aide de ces informations, vous essayez de deviner par quelle couche OSI entreprendre vos recherches. Lorsqu'il a été vérifié qu'une couche donnée fonctionne correctement, on peut supposer que les couches inférieures fonctionnent également de manière appropriée. L'administrateur peut alors examiner les couches OSI supérieures. Si une couche OSI ne fonctionne pas correctement, l'administrateur peut progresser vers le bas du modèle de l'OSI.
Par exemple, si des utilisateurs ne peuvent pas accéder au serveur web, mais qu'ils peuvent envoyer des requêtes ping à celui-ci, cela signifie que le problème se situe au-dessus de la couche 3. Si une requête ping envoyée au serveur échoue, cela signifie que le problème se situe vraisemblablement au niveau d'une couche OSI inférieure.
C'est l'une des techniques de dépannage les plus élémentaires. L'approche consiste d'abord à découvrir le trajet réel du trafic, de l'origine à la destination. La portée du dépannage est réduite aux seuls liens et dispositifs qui se trouvent sur la voie de la transmission. L'objectif est d'éliminer les liens et les périphériques qui ne sont pas pertinents pour la tâche de dépannage à accomplir. Cette approche complète généralement l'une des autres approches.
Cette approche est également appelée "swap-the-component", car vous échangez physiquement l'appareil problématique avec un appareil connu et fonctionnel. Si le problème est résolu, il s'agit alors d'un problème lié à l'appareil retiré. Si le problème persiste, alors la cause peut être ailleurs.
Dans des situations spécifiques, cela peut être une méthode idéale pour la résolution rapide de problèmes, comme par exemple avec un point de défaillance unique critique. Par exemple, un routeur de frontière tombe en panne. Il peut être plus avantageux de simplement remplacer l'appareil et de rétablir le service, plutôt que de régler le problème.
Si le problème se trouve dans plusieurs périphériques, il peut ne pas être possible d'isoler correctement le problème.
Cette approche est également appelée approche ponctuelle des différences et tente de résoudre le problème en changeant les éléments non opérationnels pour qu'ils soient cohérents avec les éléments de travail. Vous comparez des configurations, des versions logicielles, du matériel ou d'autres propriétés de périphérique, des liens ou des processus entre des situations de travail et des situations non fonctionnelles et repérez des différences significatives entre elles.
L'utilisation de cette méthode peut conduire à une solution fonctionnelle, mais sans clairement révéler la cause du problème.
Cette approche est également appelée l'approche de dépannage "shoot-from-the-hip". Il s'agit d'une méthode de dépannage moins structurée qui utilise une estimation éclairée basée sur les symptômes du problème. Le succès de cette méthode varie en fonction de votre expérience et de vos capacités de dépannage. Les techniciens expérimentés ont plus de succès parce qu'ils peuvent s'appuyer sur leurs connaissances et leur expérience approfondies pour isoler et résoudre de manière décisive les problèmes de réseau. Avec un administrateur réseau moins expérimenté, cette méthode de dépannage s'apparente plutôt à un dépannage aléatoire.
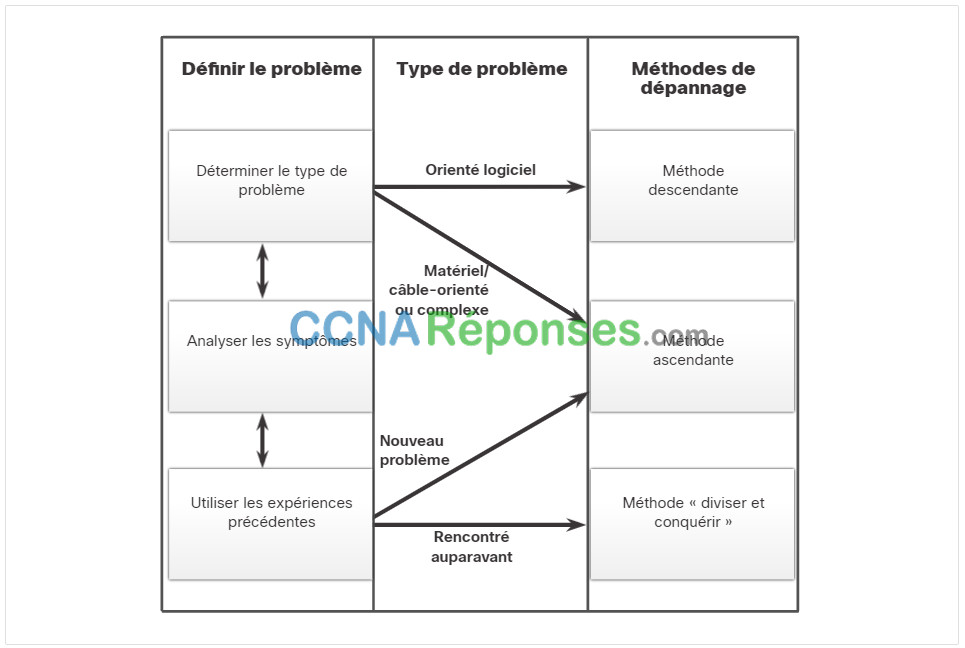
12.2.7 Recommandations pour sélectionner une méthode de dépannage
Afin de résoudre rapidement les problèmes réseau, prenez le temps de sélectionner la méthode de dépannage réseau la plus efficace.
La figure illustre la méthode qui pourrait être utilisée lorsqu’un certain type de problème est découvert.
12.3 Outils de dépannage
12.3.1 Outils logiciels de dépannage
Comme vous le savez, les réseaux sont constitués de logiciels et de matériel. Par conséquent, les logiciels et le matériel ont leurs outils respectifs pour le dépannage. Cette rubrique décrit les outils de dépannage disponibles pour les deux.
Un grand nombre d’outils logiciels et matériels pouvant faciliter le dépannage sont disponibles. Ces outils peuvent être utilisés pour la collecte et l’analyse des symptômes des problèmes réseau. Ils offrent également souvent des fonctions de surveillance et de création de rapports, pouvant servir à l’établissement de la ligne de base du réseau.
Cliquez sur chaque bouton pour obtenir une description détaillée des outils de dépannage logiciels courants.
12.3.2 Analyseurs de protocoles
Les analyseurs de protocole sont utiles pour étudier le contenu des paquets pendant qu’ils circulent sur le réseau. Un analyseur de protocole décode les différentes couches de protocole dans une trame enregistrée et présente ces informations dans un format relativement facile à utiliser. La figure montre une capture d’écran de l’analyseur de protocole Wireshark.
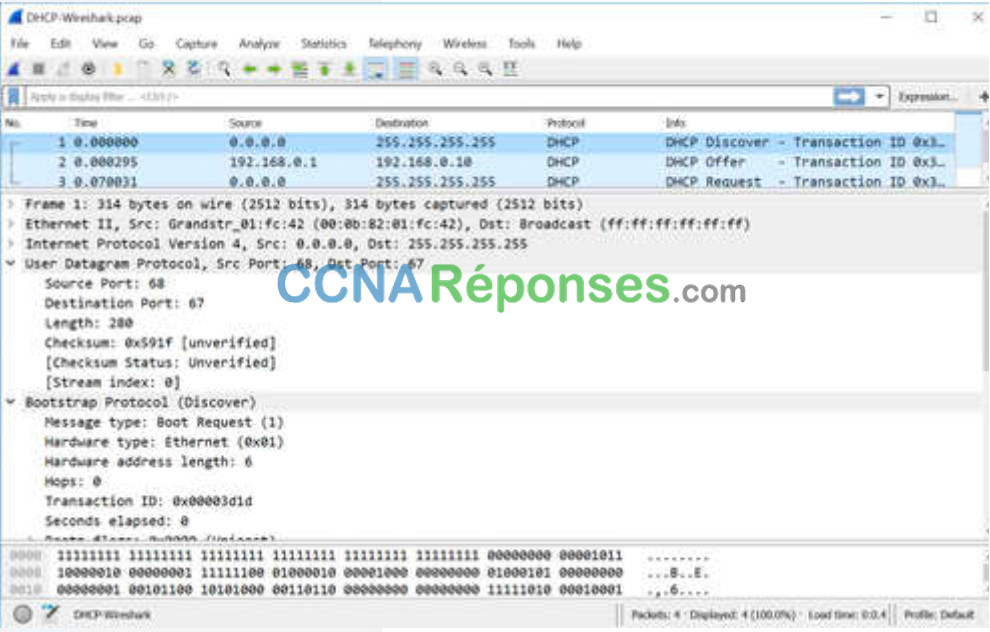
Les informations affichées par un analyseur de protocole incluent les couches physiques, liaison de données et protocole, ainsi que la description de chaque trame. La plupart des analyseurs de protocole peuvent filtrer le trafic répondant à certains critères ; par exemple, l’ensemble du trafic depuis et vers un certain périphérique peut être capturé. Des analyseurs de protocoles tels que Wireshark peuvent aider à dépanner des problèmes de performances réseau. Il est important d’avoir une bonne connaissance de TCP/IP et de savoir comment utiliser un analyseur de protocole pour examiner les informations dans chaque couche.
12.3.3 Outils matériels de dépannage
Il existe plusieurs types d’outils de dépannage du matériel.
Cliquez sur chaque bouton pour obtenir une description détaillée des outils de dépannage matériels courants.
- Multimètres numériques
- Testeurs de câble
- Analyseurs de câble
- Analyseurs de réseau portables
- Cisco Prime NAM
Les multimètres numériques (DMM), tels que le Fluke 179 illustré dans la figure, sont des instruments de test qui sont utilisés pour mesurer directement les valeurs électriques de la tension, du courant et de la résistance.
Lors du dépannage du réseau, la plupart des tests nécessitant un multimètre impliquent de vérifier les niveaux de tension d'alimentation et de s'assurer que les périphériques réseaux sont alimentés.
Les testeurs de câbles sont des appareils portables spécialisés conçus pour tester les différents types de câbles de transmission de données. L'illustration montre le testeur automatique du réseau Fluke LinkRunner AT.
Les testeurs de câble peuvent être utilisés pour détecter des câbles rompus ou croisés et des connexions court-circuitées ou mal jumelées. Ces appareils peuvent être des testeurs de continuité à bon marché, des testeurs de câble de données de prix modéré ou des réflectomètres onéreux. Les réflectomètres sont utilisés pour déterminer la distance jusqu'à une cassure dans un câble. Ces appareils envoient des signaux sur le câble et attendent qu'ils soient réfléchis. Le délai entre l'envoi du signal et sa réception en retour est converti en mesure de distance. La fonction d’un TDR est traditionnellement associée à des testeurs de câble. Les TDR utilisés pour tester les câbles à fibres optiques sont connus sous le nom de réflectomètres optiques dans le domaine temporel (OTDR).
Les analyseurs de câbles, tels que l'analyseur de câbles DTX de Fluke dans la figure, sont des appareils portables multifonctionnels qui sont utilisés pour tester et certifier les câbles en cuivre et en fibre optique pour différents services et normes.
Les outils les plus perfectionnés proposent des diagnostics de dépannage avancés, qui mesurent la distance jusqu'à un défaut, tel que la paradiaphonie (NEXT) ou la perte de réflexion (RL), identifient les mesures correctrices et affichent graphiquement la diaphonie et le comportement de l'impédance. Les analyseurs de câble comprennent également généralement des logiciels pour PC. Une fois les données de terrain collectées, les informations de l'appareil portable peuvent être chargées afin que l'administrateur réseau puisse créer des rapports à jour.
Les appareils portables comme le Fluke OptiView, illustré dans la figure, sont utilisés pour dépanner les réseaux commutés et les VLAN.
En branchant l'analyseur réseau n'importe où dans le réseau, un ingénieur réseau peut voir le port de commutation auquel le périphérique est connecté, ainsi que les utilisations moyenne et de pointe. L'analyseur peut également être utilisé pour découvrir la configuration du VLAN, identifier les principaux interlocuteurs du réseau (hôtes générant le plus de trafic), analyser le trafic réseau et afficher les détails de l'interface. Le périphérique envoie généralement ses résultats à un PC sur lequel un logiciel de surveillance réseau a été installé, à des fins d'analyse et de dépannage.
Le portefeuille de modules NAM (Cisco Prime Network Analysis Module), illustré dans la figure, comprend du matériel et des logiciels pour l'analyse des performances dans les environnements de commutation et de routage. Il offre une interface web intégrée qui génère des rapports sur le trafic qui consomme les ressources critiques du réseau. De plus, le NAM peut capturer, décoder des paquets et suivre les délais de réponse pour identifier un problème applicatif sur un réseau ou un serveur particulier.

12.3.4 Serveur Syslog en tant qu’outil de dépannage
Le protocole Syslog est un protocole simple utilisé par un périphérique IP faisant office de client Syslog, afin d’envoyer des messages textuels de journal vers un autre périphérique IP, à savoir le serveur Syslog. Le protocole Syslog est actuellement défini dans la RFC 5424.
L’implémentation d’une méthode de journalisation est une partie importante de la sécurité du réseau et du dépannage réseau. Les périphériques Cisco peuvent consigner des informations relatives aux modifications de configuration, aux violations des listes de contrôle d’accès, à l’état des interfaces ainsi qu’à de nombreux autres types d’événements. Les périphériques Cisco peuvent envoyer des messages de journal à diverses installations différentes. Les messages d’événement peuvent être envoyés à un ou plusieurs des éléments suivants :
- Console – La journalisation de la console est activée par défaut. Les messages sont consignés sur la console et peuvent être affichés lors de la modification ou du test du routeur ou du commutateur, en se connectant au port de console de l’appareil réseau à l’aide d’un logiciel d’émulation de terminal.
- Lignes de terminaux – Les sessions EXEC activées peuvent être configurées pour recevoir des messages de log sur n’importe quelle ligne de terminal. Comme la journalisation de la console, ce type de journalisation n’est pas stocké par le périphérique réseau et n’a donc de valeur que pour l’utilisateur sur cette ligne.
- Journalisation en mémoire tampon – La journalisation en mémoire tampon est un peu plus utile comme outil de dépannage car les messages de journalisation sont stockés en mémoire pendant un certain temps. Toutefois, les messages de journal sont effacés lors du redémarrage du périphérique.
- Pièges SNMP – Certains seuils peuvent être préconfigurés sur les routeurs et autres appareils. Les événements de routeur, tels que le dépassement d’un seuil, peuvent être traités par le routeur et transmis via un trap SNMP vers une station SNMP externe de gestion de réseau. Les pièges SNMP sont un moyen d’enregistrement de sécurité viable mais nécessitent la configuration et la maintenance d’un système SNMP.
- Syslog – Les routeurs et commutateurs Cisco peuvent être configurés pour transférer les messages du journal à un service syslog externe. Ce service peut résider sur un nombre quelconque de serveurs ou de stations de travail, notamment des systèmes exécutant Microsoft Windows ou Linux. Syslog est l’outil de journalisation des messages le plus populaire, car il permet le stockage des messages de routeur sur une longue période, et ce, dans un emplacement centralisé.
Les messages du journal IOS de Cisco se répartissent en huit niveaux, comme indiqué dans le tableau.
| Niveau | Mot clé | Description | Définition | |
|---|---|---|---|---|
| Niveau le plus élevé | 0 | Urgences | Système inutilisable | LOG_EMERG |
| 1 | Alertes | Action immédiate requise | LOG_ALERT | |
| 2 | Essentiel | Existence de conditions critiques | LOG_CRIT | |
| 3 | Erreurs | Existence de conditions d’erreur | LOG_ERR | |
| 4 | Avertissements | Existence de conditions d’avertissement | LOG_WARNING | |
| Niveau le plus bas | 5 | Notifications | Condition normale (mais significative) | LOG_NOTICE |
| 6 | Information | Message d’information uniquement | LOG_INFO | |
| 7 | Débogage | Messages de débogage | LOG_DEBUG |
Plus le numéro de niveau est faible, plus le niveau de gravité est important. Par défaut, tous les messages appartenant aux niveaux de 0 à 7 sont consignés dans la console. Même si la possibilité d’afficher des journaux sur un serveur Syslog central s’avère utile en cas de dépannage, l’analyse d’une grande quantité de données peut être une tâche fastidieuse. La commande logging trap level limite les messages enregistrés sur le serveur syslog en fonction de leur gravité. Le niveau est le nom ou le numéro du niveau de gravité Seuls les messages égaux ou numériquement inférieurs au niveau spécifié sont enregistrés.
Dans la sortie de commande, les messages système de niveau 0 (urgences) à 5 (notifications) sont envoyés au serveur syslog au 209.165.200.225.
R1(config)# logging host 209.165.200.225 R1(config)# logging trap notifications R1(config)# logging on R1(config)#
12.4 Symptômes et causes des problèmes de réseau
12.4.1 Dépannage de la couche physique
Maintenant que vous avez votre documentation, une connaissance des méthodes de dépannage et des outils logiciels et matériels à utiliser pour diagnostiquer les problèmes, vous êtes prêt à commencer le dépannage ! Cette rubrique couvre les problèmes les plus courants que vous trouverez lors du dépannage d’un réseau.
Les problèmes survenant sur un réseau se présentent souvent sous la forme de problèmes de performances. La présence de problèmes de performances signifie qu’il existe une différence entre le comportement attendu et le comportement observé, et que le système ne fonctionne pas comme on peut raisonnablement s’y attendre. Les défaillances et les conditions sous-optimales au niveau de la couche physique perturbent les utilisateurs et peuvent également avoir un impact sur la productivité globale de l’entreprise. Les réseaux qui connaissent ce type de problèmes tombent généralement en panne. Étant donné que les couches supérieures du modèle OSI dépendent de la couche physique pour fonctionner, un administrateur réseau doit avoir la possibilité d’isoler et corriger de façon efficace les problèmes qui se produisent au niveau de cette couche.
La figure résume les symptômes et les causes des problèmes de réseau de couche physique.
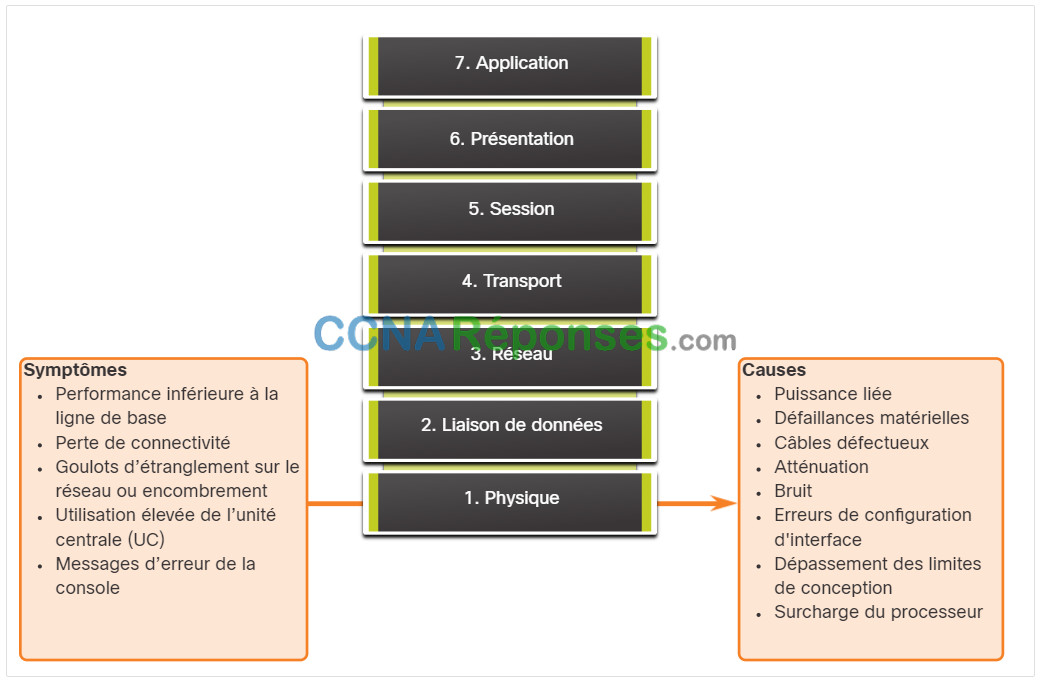
Le tableau répertorie les symptômes courants des problèmes de réseau de couche physique.
| Signe | Description |
|---|---|
| Performance inférieure à la ligne de base |
|
| Perte de connectivité |
|
| Goulots d’étranglement sur le réseau ou encombrement |
|
| Utilisation élevée de l’unité centrale (UC) |
|
| Messages d’erreur de la console |
|
Les problèmes réseau relatifs à la couche physique les plus fréquents sont les suivants :
| Cause du problème | Description |
|---|---|
| Problèmes d’alimentation |
|
| Défaillances matérielles |
|
| Câbles défectueux |
|
| Atténuation |
|
| Bruit |
|
| Erreurs de configuration d’interface |
|
| Dépassement des limites de conception |
|
| Surcharge du processeur |
|
12.4.2 Dépannage de la couche liaison de données
Le dépannage des problèmes de couche 2 peuvent être un processus délicat. La configuration et le fonctionnement de ces protocoles sont critiques pour la création d’un réseau fonctionnel et correctement adapté. Les problèmes de couche 2 entraînent l’apparition de symptômes spécifiques qui, lorsqu’ils sont détectés, permettent d’identifier rapidement le problème.
La figure résume les symptômes et les causes des problèmes de réseau de couche de liaison de données.
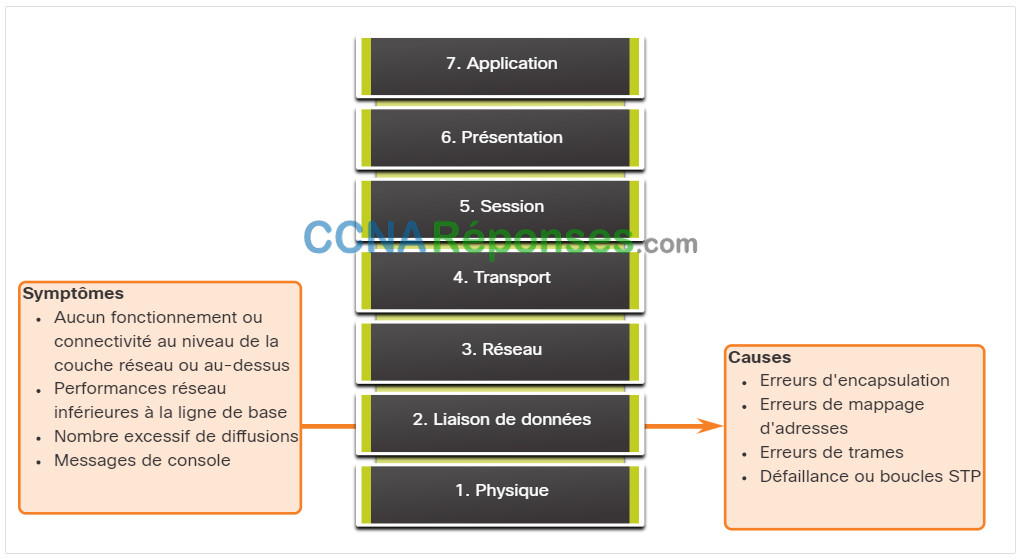
Le tableau répertorie les symptômes courants des problèmes de réseau de couche de liaison de données.
| Signe | Description |
|---|---|
| Erreur de fonctionnement ou de connectivité au niveau de la couche réseau ou au-dessus | Certains problèmes de couche 2 peuvent arrêter l’échange de trames à travers un lien, tandis que d’autres ne provoquent que la dégradation des performances du réseau. |
| Performances réseau inférieures au point de référence |
|
| Nombre excessif de diffusions |
|
| Messages de console |
|
Le tableau énumère les problèmes qui causent couramment des problèmes de réseau au niveau de la couche liaison de données.
| Cause du problème | Description |
|---|---|
| Erreurs d’encapsulation |
|
| Erreurs de mappage d’adresses |
|
| Erreurs de trames |
|
| Défaillance ou boucles STP |
|
12.4.3 Dépannage de la couche réseau
Les problèmes de la couche réseau comprennent tout problème impliquant un protocole de couche 3, tel que IPv4, IPv6, EIGRP, OSPF, etc. La figure résume les symptômes et les causes des problèmes de réseau de la couche réseau.
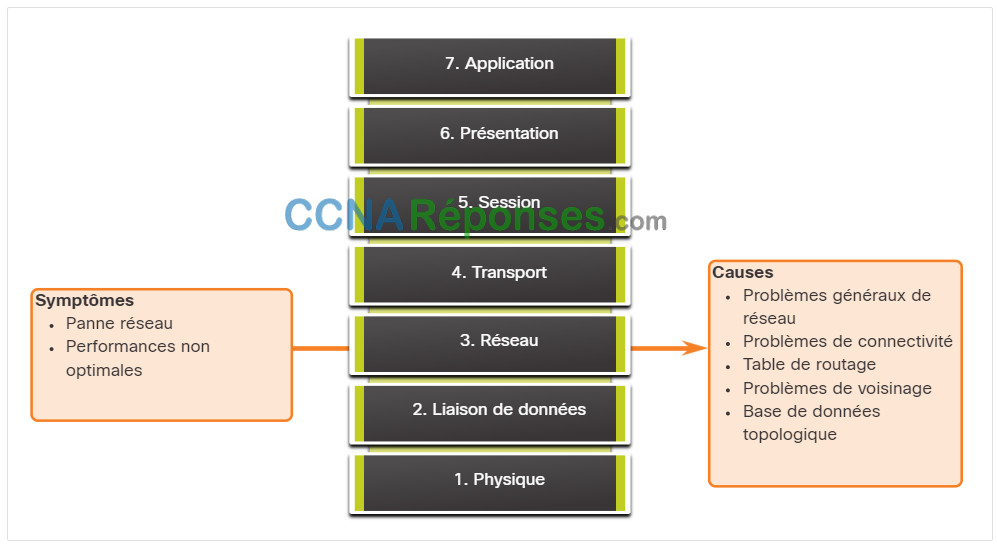
Le tableau répertorie les symptômes courants des problèmes de réseau de couche de liaison de données.
| Signe | Description |
|---|---|
| Panne réseau |
|
| Performances non optimales |
|
Dans la plupart des réseaux, des routes statiques sont utilisées en combinaison avec des protocoles de routage dynamique. Une configuration incorrecte de ces routes statiques peut entraîner un routage non optimal. Dans certains cas, des routes statiques mal configurées peuvent créer des boucles de routage rendant inaccessibles certaines parties du réseau.
Le dépannage des protocoles de routage dynamique nécessite une connaissance approfondie de leur mode de fonctionnement. Certains problèmes sont communs à l’ensemble des protocoles de routage, tandis que d’autres sont spécifiques à un protocole de routage individuel.
Il n’existe pas de modèle de résolution unique des problèmes de couche 3. Pour résoudre les problèmes de routage, il convient de suivre un processus méthodique en utilisant une série de commandes afin d’isoler et de diagnostiquer le problème.
Domaines à analyser lors du diagnostic d’un éventuel problème relatif aux protocoles de routage :
| Cause du problème | Description |
|---|---|
| Problèmes généraux de réseau |
|
| Problèmes de connectivité |
|
| Table de routage |
|
| Problèmes de voisinage | Si le protocole de routage établit une contiguïté avec un voisin, vérifiez s’il y a des problèmes avec les routeurs formant des contiguïtés voisines. |
| Base de données topologique | Si le protocole de routage utilise une table de topologie ou une base de données, vérifiez la table pour détecter tout élément inattendu, tel que des entrées manquantes ou des entrées inattendues. |
12.4.4 Dépannage de la couche transport – listes de contrôle d’accès
Des problèmes réseau peuvent survenir à partir de problèmes de couche transport sur le routeur, en particulier au niveau de la périphérie du réseau où le trafic est examiné et modifié. Par exemple, les listes de contrôle d’accès (ACLs) et la traduction d’adresses réseau (NAT) fonctionnent sur la couche réseau et peuvent impliquer des opérations sur la couche de transport, comme le montre la figure.
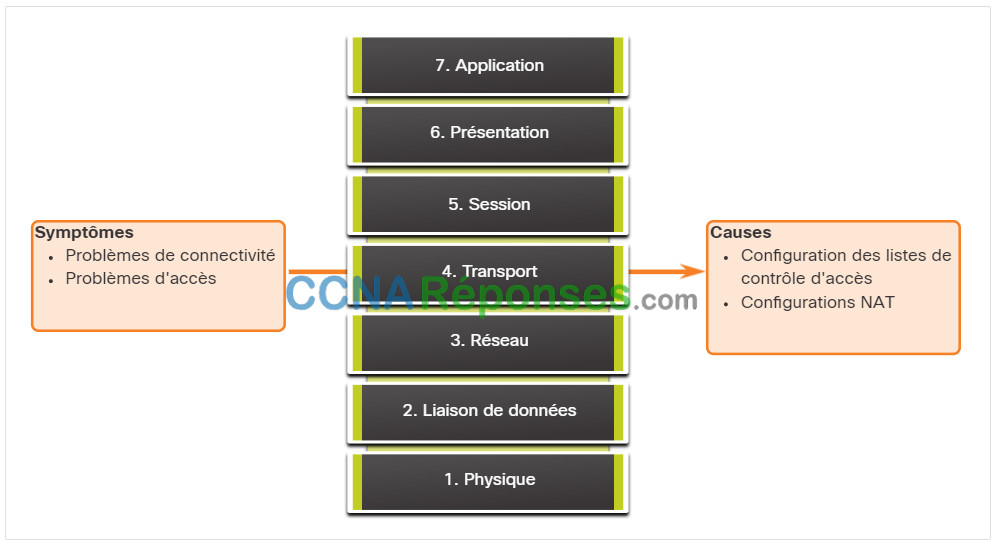
Les problèmes les plus courants avec les LCA sont dus à une mauvaise configuration, comme le montre la figure.

Les problèmes de listes de contrôle d’accès peuvent entraîner la défaillance de systèmes parfaitement opérationnels. Le tableau énumère les domaines dans lesquels des erreurs de configuration se produisent fréquemment.
| Mauvaises configurations | Description |
|---|---|
| Sélection du flux de trafic |
|
| Ordre incorrect des entrées de contrôle d’accès |
|
| Implicite deny any | Lorsque la sécurité élevée n’est pas requise sur l’ACL, cet accès implicite peut être la cause d’une mauvaise configuration de l’ACL. |
| Masques génériques d’adresses et IPv4 |
|
| Sélection de protocole de couche transport |
|
| Ports source et de destination |
|
| Utilisation du mot-clé established |
|
| Protocoles non courants |
|
Le mot-clé log est une commande utile pour visualiser le fonctionnement du ACL sur les entrées du ACL. Ce mot clé demande au routeur de placer une entrée dans le journal du système chaque fois que cette condition d’entrée est satisfaite. L’événement consigné contient des détails relatifs au paquet qui correspondait à l’élément de liste de contrôle d’accès. Le mot-clé log est particulièrement utile pour le dépannage et fournit des informations sur les tentatives d’intrusion bloquées par l’ACL.
12.4.5 Dépannage de la couche transport – NAT pour IPv4
Il y a plusieurs problèmes avec la NAT, comme le fait de ne pas interagir avec des services comme le DHCP et le tunneling. Il peut s’agir de NAT internes ou externes ou d’ACL mal configurés. Les autres problèmes concernent l’interopérabilité avec d’autres technologies réseau, en particulier celles qui contiennent ou qui créent des informations à partir de l’adressage du réseau hôte dans le paquet.
La figure résume les domaines d’interopérabilité communs avec la NAT.

Le tableau énumère les domaines d’interopérabilité communs avec le NAT.
| Signe | Description |
|---|---|
| Protocoles BOOTP et DHCP |
|
| DNS |
|
| SNMP |
|
| Protocoles de tunneling et de chiffrement |
|
12.4.6 Dépannage de la couche application
La plupart des protocoles de couche Application fournissent des services utilisateur. Les protocoles de couche Application sont généralement utilisés pour la gestion du réseau, le transfert de fichiers, les services de fichiers distribués, l’émulation de terminal et l’e-mail. De nouveaux services utilisateur sont souvent ajoutés, comme les VPN et le protocole VoIP.
La figure montre les protocoles de la couche application TCP/IP les plus connus et les plus mis en œuvre.
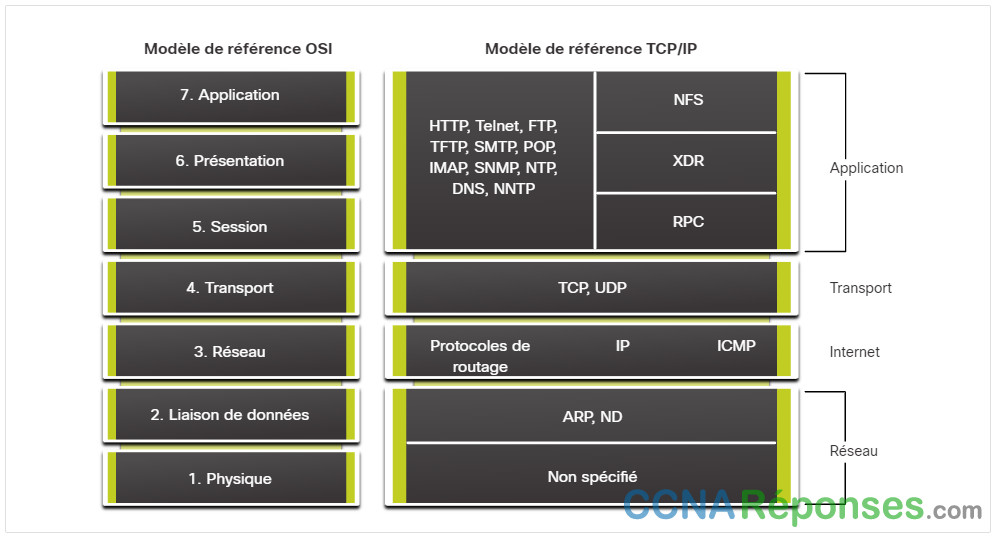
Le tableau fournit une brève description de ces protocoles de couche d’application.
| Applications | Description |
|---|---|
| SSH/TelNet | Permet aux utilisateurs d’établir des connexions de session de terminal avec des hôtes distants. |
| HTTP | Permet l’échange de textes, d’images graphiques, de sons, de vidéos et d’autres fichiers multimédia sur le web. |
| FTP | Effectue des transferts de fichiers interactifs entre les hôtes. |
| TFTP | Effectue des transferts de fichiers interactifs de base, généralement entre des hôtes et des dispositifs de réseau. |
| SMTP | Prend en charge les services de base de transmission de messages. |
| POP | Se connecte aux serveurs de messagerie et télécharge le courrier électronique. |
| SNMP | Collecte des informations de gestion à partir des périphériques réseau. |
| DNS | Fait correspondre les adresses IP aux noms attribués aux appareils du réseau. |
| Network File System (NFS) | Permet aux ordinateurs de monter des lecteurs sur des hôtes distants et de les faire fonctionner comme s’il s’agissait de lecteurs locaux. Initialement développé par Sun Microsystems, il se combine avec deux autres protocoles de la couche application, la représentation externe des données (XDR) et l’appel de procédure à distance (RPC), pour permettre un accès transparent aux ressources réseau distantes. |
Les types de symptômes et de causes dépendent de l’application réelle elle-même.
Les problèmes liés à la couche application empêchent la fourniture de services aux applications. Un problème au niveau de la couche application peut conduire à des ressources inaccessibles ou inutilisables, même si les couches physique, liaison de données, réseau et transport fonctionnent correctement. Il se peut que la connectivité réseau soit complète, mais l’application ne peut tout simplement pas fournir de données.
Un autre type de problème de couche application se produit lorsque les couches physique, liaison de données, réseau et transport fonctionnent correctement, mais que le transfert de données et les requêtes de services réseau à partir d’un service réseau ou d’une application unique ne correspondent pas aux attentes normales d’un utilisateur.
Un problème au niveau de la couche applicative peut amener les utilisateurs à se plaindre que le réseau ou une application avec laquelle ils travaillent est léthargique ou plus lent que d’habitude lors du transfert de données ou de la demande de services réseau.
12.5 Dépannage de la connectivité IP
12.5.1 Éléments de dépannage de la connectivité de bout en bout
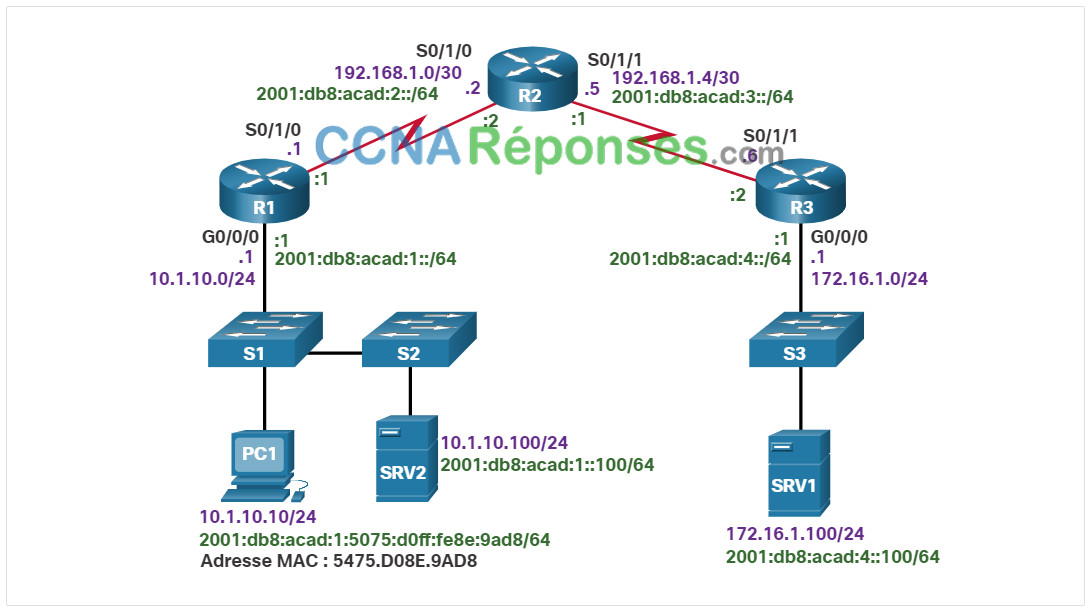
Cette rubrique présente une topologie unique et les outils permettant de diagnostiquer et, dans certains cas, de résoudre un problème de connectivité de bout en bout. Le diagnostic et la résolution de problèmes sont des compétences essentielles des administrateurs réseau. Il n’existe pas de recette unique pour résoudre les problèmes, et un problème peut être diagnostiqué de plusieurs façons. Toutefois, grâce à la mise en œuvre d’une approche structurée pour le processus de dépannage, un administrateur peut diminuer le temps nécessaire au diagnostic et à la résolution d’un problème.
Le scénario ci-dessous est utilisé tout au long de cette rubrique. L’hôte client PC1 ne peut pas accéder aux applications se trouvant sur les serveurs SRV1 et SRV2. La figure illustre la topologie de ce réseau. PC1 utilise SLAAC avec EUI-64 pour créer son adresse de monodiffusion globale IPv6. EUI-64 crée l’ID d’interface à l’aide de l’adresse MAC Ethernet, insère FFFE au milieu et manipule le septième bit.
Lorsqu’il n’y a pas de connectivité de bout en bout, et que l’administrateur choisit de dépanner avec une approche ascendante, voici les mesures courantes qu’il peut prendre :
Étape 1. Vérifiez la connectivité physique à l’endroit où la communication réseau s’arrête. Cela inclut les câbles et le matériel. Le problème peut concerner un câble défectueux ou une interface défaillante, ou impliquer du matériel mal configuré ou défaillant.
Étape 2. Vérifiez les incohérences de duplex.
Étape 3. Vérifiez l’adressage des couches de liaison de données et réseau sur le réseau local. Cela inclut les tables ARP IPv4, les tables de voisinage IPv6, les tables d’adresses MAC et les attributions de VLAN.
Étape 4. Vérifiez que la passerelle par défaut est correcte.
Étape 5. Assurez-vous que les appareils déterminent le chemin correct entre la source et la destination. Si nécessaire, manipulez les informations de routage.
Étape 6. Vérifiez que la couche transport fonctionne correctement. Telnet peut également être utilisé pour tester les connexions de la couche transport à partir de la ligne de commande.
Étape 7. Vérifiez qu’il n’y a pas de listes de contrôle d’accès qui bloquent le trafic.
Étape 8. Vérifiez que les paramètres DNS sont corrects. Un serveur DNS devrait être accessible.
Le résultat de ce processus est une connectivité opérationnelle de bout en bout. Si toutes les étapes ont été effectuées sans aucune résolution, l’administrateur réseau peut soit répéter les étapes précédentes, soit soumettre le problème à un administrateur supérieur.
12.5.2 Problème de connectivité de bout en bout nécessitant un dépannage
D’une manière générale, c’est la découverte d’un problème de connectivité de bout en bout qui initie un dépannage. Deux des services publics les plus couramment utilisés pour vérifier un problème de connectivité de bout en bout sont ping et traceroute , comme le montre la figure.
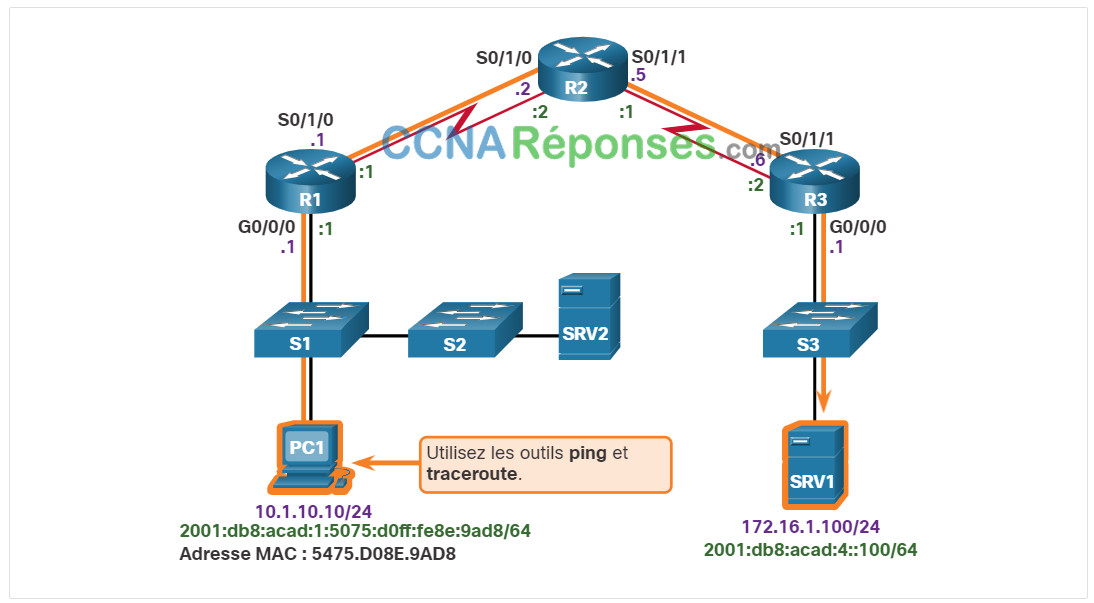
Cliquez sur chaque bouton pour consulter les utilitaires ping, traceroute et tracert.
Remarque: la commande traceroute est généralement exécutée lorsque la commande ping échoue. Si le ping réussit, le traceroute n’est généralement pas nécessaire car le technicien sait que la connectivité existe.
12.5.3 Étape 1: Vérification de la couche physique
Tous les périphériques réseau sont des systèmes informatiques spécialisés. Au minimum, ces périphériques se composent d’un processeur, d’une mémoire vive et d’un espace de stockage, permettant au périphérique de démarrer et d’exécuter un système d’exploitation ainsi que des interfaces. Cette structure permet la réception et la transmission de trafic réseau. Lorsqu’un administrateur réseau détecte l’existence d’un problème sur un périphérique donné et qu’il semble que ce problème soit lié au matériel, il est utile de vérifier le fonctionnement de ces composants génériques. Les commandes Cisco IOS les plus couramment utilisées à cet effet sont show processes cpu**show memory, et show interfaces. Cette rubrique présente la commande show interfaces**.
Lorsque le dépannage concerne des problèmes liés aux performances et que l’on soupçonne un défaut du matériel, la commande show interfaces peut être utilisée pour vérifier les interfaces par lesquelles passe le trafic.
Reportez-vous à la sortie de commande de la commande show interfaces.
R1# show interfaces GigabitEthernet 0/0/0 GigabitEthernet0/0/0 is up, line protocol is up Hardware is CN Gigabit Ethernet, address is d48c.b5ce.a0c0(bia d48c.b5ce.a0c0) Internet address is 10.1.10.1/24 (Output omitted) Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0 Queueing strategy: fifo Output queue: 0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 85 packets input, 7711 bytes, 0 no buffer Received 25 broadcasts (0 IP multicasts) 0 runts, 0 giants, 0 throttles 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored 0 watchdog, 5 multicast, 0 pause input 10112 packets output, 922864 bytes, 0 underruns 0 output errors, 0 collisions, l interface resets 11 unknown protocol drops 0 babbles, 0 late collision, 0 deferred 0 lost carrier, 0 no carrier, 0 pause output 0 output buffer failures, 0 output buffers swapped out R1#
Cliquez sur chaque bouton pour obtenir une explication de la sortie en surbrillance.
12.5.4 Étape 2 – Vérifier les erreurs de concordance des duplex
Une autre cause courante d’erreur d’interface est une incohérence dans les paramètres bidirectionnels entre les deux extrémités d’une liaison Ethernet. Dans de nombreux réseaux Ethernet, les connexions point à point constituent aujourd’hui la norme tandis que l’utilisation de concentrateurs avec le fonctionnement associé en mode bidirectionnel non simultané est devenue moins courante. Cela signifie que la plupart des liaisons Ethernet fonctionnent aujourd’hui en mode duplex intégral, et si les collisions étaient normales pour une liaison Ethernet, les collisions d’aujourd’hui indiquent souvent que la négociation duplex a échoué, ou que la liaison ne fonctionne pas dans le mode duplex correct.
La norme IEEE 802.3ab Gigabit Ethernet nécessite l’utilisation de la négociation automatique pour la vitesse et le mode bidirectionnel. Par ailleurs et bien que cela ne soit pas strictement obligatoire, pratiquement toutes les cartes réseau Fast Ethernet utilisent également la négociation automatique par défaut. L’utilisation de la négociation automatique pour la vitesse et le mode bidirectionnel est la pratique couramment recommandée.
Toutefois, si la négociation en mode bidirectionnel échoue pour l’une ou l’autre raison, il peut s’avérer nécessaire de définir la vitesse et le mode bidirectionnel manuellement sur les deux extrémités. D’une manière générale, cela impliquerait la configuration du mode bidirectionnel en mode bidirectionnel simultané au niveau des deux extrémités de la connexion. Si cela ne fonctionne pas, il est préférable de choisir le mode bidirectionnel non simultané aux deux extrémités plutôt que d’avoir une incohérence de mode bidirectionnel.
Les directives de configuration du duplex sont les suivantes :
- La négociation automatique de vitesse et de mode bidirectionnel est recommandée.
- Si la négociation automatique échoue, paramétrez manuellement le débit et le mode bidirectionnel aux extrémités interconnectées.
- Les liaisons Ethernet point à point doivent toujours être exécutées en mode bidirectionnel simultané.
- Le mode bidirectionnel non simultané est rare et ne se rencontre généralement qu’en cas d’utilisation d’anciens concentrateurs.
Exemple de dépannage
Dans le scénario précédent, l’administrateur réseau devait ajouter des utilisateurs supplémentaires dans le réseau. Afin d’intégrer ces nouveaux utilisateurs, l’administrateur réseau a installé un second commutateur et l’a connecté au premier. Peu après l’ajout de S2 au réseau, les utilisateurs des deux commutateurs ont commencé à rencontrer d’importants problèmes de performances pour se connecter aux appareils de l’autre commutateur, comme le montre la figure.
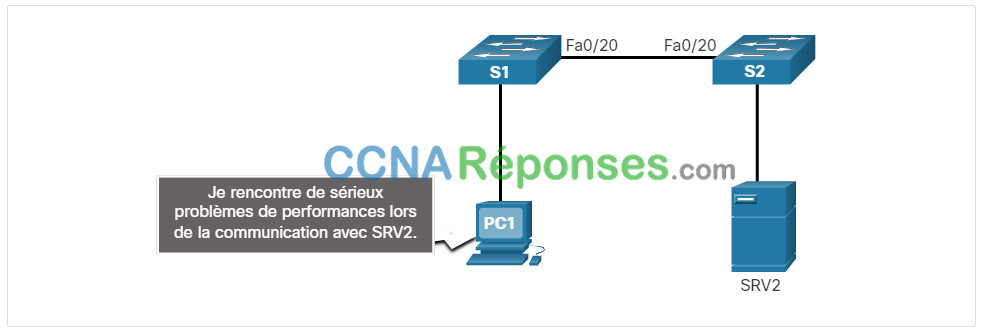
L’administrateur réseau note la présence d’un message de console sur le commutateur S2 :
*Mar 1 00:45:08.756: %CDP-4-DUPLEX_MISMATCH: duplex mismatch discovered on FastEthernet0/20 (not half duplex), with Switch FastEthernet0/20 (half duplex).
À l’aide de la commande show interfaces fa 0/20, l’administrateur réseau examine l’interface sur S1 qui est utilisée pour se connecter à S2 et remarque qu’elle est réglée en duplex intégral, comme le montre la sortie de la commande.
S1# show interface fa 0/20
FastEthernet0/20 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0cd9.96e8.8a01 (bia 0cd9.96e8.8a01)
MTU 1500 bytes, BW 10000 Kbit/sec, DLY 1000 usec, reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set Keepalive set (10 sec)
Full-duplex, Auto-speed, media type is 10/100BaseTX
(Output omitted)
S1#
L’administrateur réseau examine maintenant l’autre côté de la connexion, à savoir le port sur S2. La commande out montre que ce côté de la connexion a été configuré pour le semi-duplex.
S2# show interface fa 0/20
FastEthernet0/20 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0cd9.96d2.4001 (bia 0cd9.96d2.4001)
MTU 1500 bytes, BW 100000 Kbit/sec, DLY 100 usec, reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set Keepalive set (10 sec)
Half-duplex, Auto-speed, media type is 10/100BaseTX
(Output omitted)
S2(config)# interface fa 0/20
S2(config-if)# duplex auto
S2(config-if)#
L’administrateur réseau corrige le paramètre à duplex auto pour négocier automatiquement le duplex. Le port sur S1 étant défini en mode bidirectionnel simultané, S2 utilise également ce mode.
Les utilisateurs signalent qu’ils ne rencontrent plus de problèmes de performances.
12.5.5 Étape 3 – Vérification de l’adressage sur le réseau local
Lors d’un dépannage de la connectivité de bout en bout, il est utile de vérifier les mappages entre les adresses IP de destination et les adresses Ethernet de couche 2 sur des segments individuels. Dans IPv4, cette fonctionnalité est fournie par le protocole ARP. Dans IPv6, la fonctionnalité ARP est remplacée par le processus de découverte de voisins et ICMPv6. La table de voisinage met en cache les adresses IPv6 ainsi que leurs adresses physiques Ethernet résolues (MAC).
Cliquez sur chaque bouton pour obtenir un exemple et une explication de la commande pour vérifier l’adressage des couches 2 et 3.
12.5.6 Exemple de dépannage des problèmes d’attribution de VLAN
Un autre problème à prendre en considération lors du dépannage de la connectivité de bout en bout est l’attribution de VLAN. Au sein du réseau commuté, chaque port d’un commutateur appartient à un VLAN. Chaque VLAN est considéré comme un réseau logique distinct et les paquets destinés aux stations n’appartenant pas au VLAN doivent être transférés par un périphérique qui prend en charge le routage. Si un hôte d’un VLAN envoie une trame de diffusion Ethernet, telle qu’une demande ARP, tous les hôtes du même VLAN reçoivent la trame, tandis que ceux des autres VLAN ne la reçoivent pas. Même si deux hôtes se trouvent dans le même réseau IP, ils ne pourront pas communiquer entre eux s’ils sont connectés à des ports attribués à deux VLAN distincts. De plus, si le VLAN auquel appartient le port est supprimé, le port devient inactif. Tous les hôtes reliés aux ports appartenant au VLAN qui a été supprimé ne peuvent plus communiquer avec le reste du réseau. Des commandes telles que show vlan peuvent être utilisées pour valider les attributions VLAN sur un commutateur.
Supposons par exemple, que dans un effort pour améliorer la gestion des fils dans le placard de câblage, votre entreprise a réorganisé les câbles de connexion au commutateur S1. Presque immédiatement après, des utilisateurs ont commencé à appeler le centre d’assistance en indiquant qu’ils ne parvenaient plus à accéder aux périphériques situés en dehors de leur propre réseau.
Cliquez sur chaque bouton pour obtenir une explication du processus utilisé pour résoudre ce problème.
12.5.7 Étape 4 – Vérification de la passerelle par défaut
S’il n’y a pas de route détaillée sur le routeur, ou si l’hôte est configuré avec la mauvaise passerelle par défaut, alors la communication entre deux points d’extrémité dans des réseaux différents ne fonctionne pas.
La figure illustre la façon dont le PC1 utilise R1 comme passerelle par défaut. De même, R1 utilise R2 en guise de passerelle par défaut ou de passerelle de dernier recours. Si un hôte a besoin d’accéder à des ressources situées en dehors du réseau local, la passerelle par défaut doit être configurée. La passerelle par défaut est le premier routeur rencontré sur le chemin vers les destinations situées en dehors du réseau local.
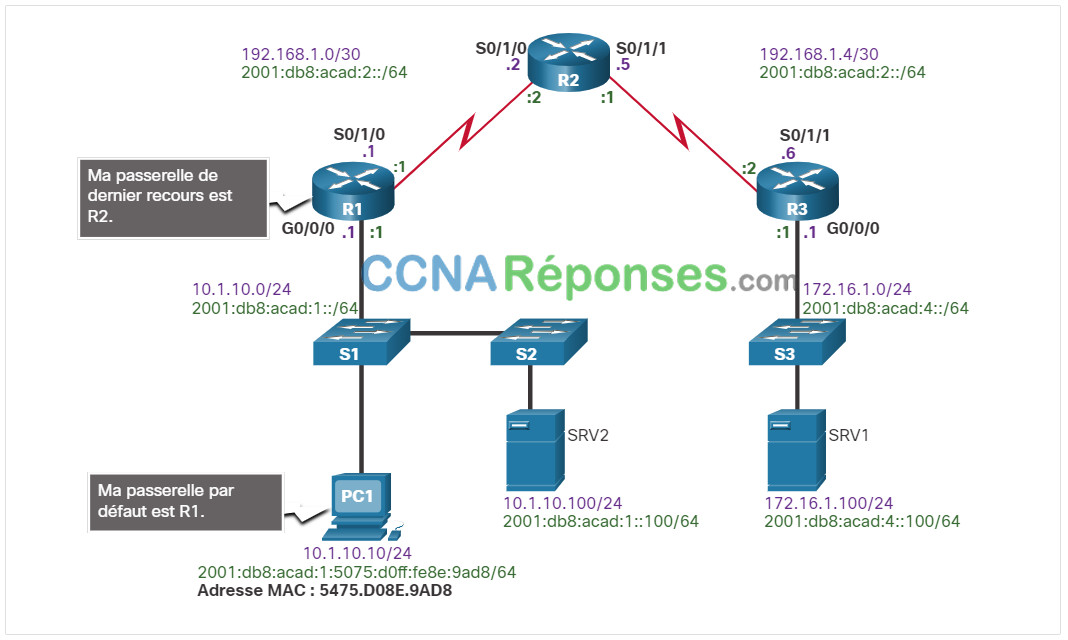
Exemple de dépannage de la passerelle par défaut IPv4
Dans cet exemple, R1 a la passerelle par défaut correcte, qui est l’adresse IPv4 de R2. Toutefois, PC1 possède une passerelle par défaut incorrecte. PC1 devrait avoir la passerelle par défaut de R1 10.1.10.1. Cette passerelle doit être configurée manuellement si les informations d’adressage IPv4 ont été configurées manuellement sur PC1. Si les informations d’adressage IPv4 ont été obtenues automatiquement d’un serveur DHCPv4, la configuration de celui-ci doit être examinée. Un problème de configuration sur un serveur DHCP affecte généralement plusieurs clients.
Cliquez sur chaque bouton pour afficher la sortie de commande pour R1 et PC1.
12.5.8 Exemple de dépannage de la passerelle par défaut IPv6
Dans IPv6, la passerelle par défaut peut être configurée manuellement, à l’aide de l’auto configuration sans état (SLAAC) ou du DHCPv6. Avec SLAAC, la passerelle par défaut est annoncée par le routeur aux hôtes à l’aide de messages d’annonce de routeur (RA) ICMPv6. La passerelle par défaut indiquée dans le message d’annonce de routeur est l’adresse IPv6 link-local d’une interface de routeur. Si la passerelle par défaut est configurée manuellement sur l’hôte, ce qui est très peu probable, la passerelle par défaut peut être configurée soit sur l’adresse IPv6 globale, soit sur l’adresse IPv6 locale du lien.
Cliquez sur chaque bouton pour obtenir un exemple et une explication de dépannage d’un problème de passerelle IPv6 par défaut.
12.5.9 Étape 5 – Vérification du chemin correct
Lors d’un dépannage, il est souvent nécessaire de vérifier le chemin vers le réseau de destination. La figure montre la topologie de référence indiquant le chemin prévu pour les paquets de PC1 à SRV1.
La figure représente une topologie de référence qui indique le chemin prévu de PC1 à SRV1. R1 est relié à R2 par une connexion série. R2 est relié à R3 par une connexion série. R1 a un lien avec S1. S1 a un lien avec PC1 et S2. S2 a un lien avec SRV2. R3 a un lien avec S3. S3 a un lien avec SRV1. Il y a une ligne dessine le chemin de R1 vers l’interface R3s G0/0/0 en utilisant les commandes show ip route et show ipv6 route.
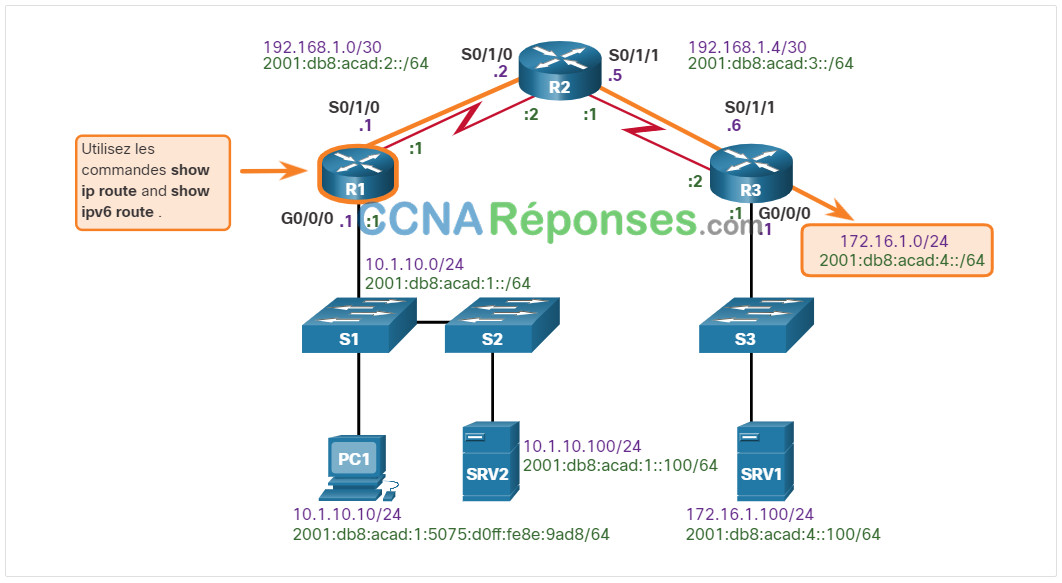
Les routeurs du chemin prennent la décision de routage en fonction des informations contenues dans les tables de routage. Cliquez sur chaque bouton pour afficher les tables de routage IPv4 et IPv6 pour R1.
Les méthodes suivantes permettent de compléter les tables de routage IPv4 et IPv6 :
- Réseaux connectés directement
- Routes d’hôte local ou routes locales
- Routes statiques
- Routes dynamiques
- Routes par défaut
Le processus de transfert de paquets IPv4 et IPv6 se base sur le bit ou le préfixe correspondant le plus long. Le processus de table de routage tentera de faire suivre le paquet en utilisant une entrée dans la table de routage avec le plus grand nombre de bits correspondants à gauche. Le nombre de bits correspondants est indiqué par la longueur de préfixe de la route.
La figure décrit le processus pour les tables de routage IPv4 et IPv6.
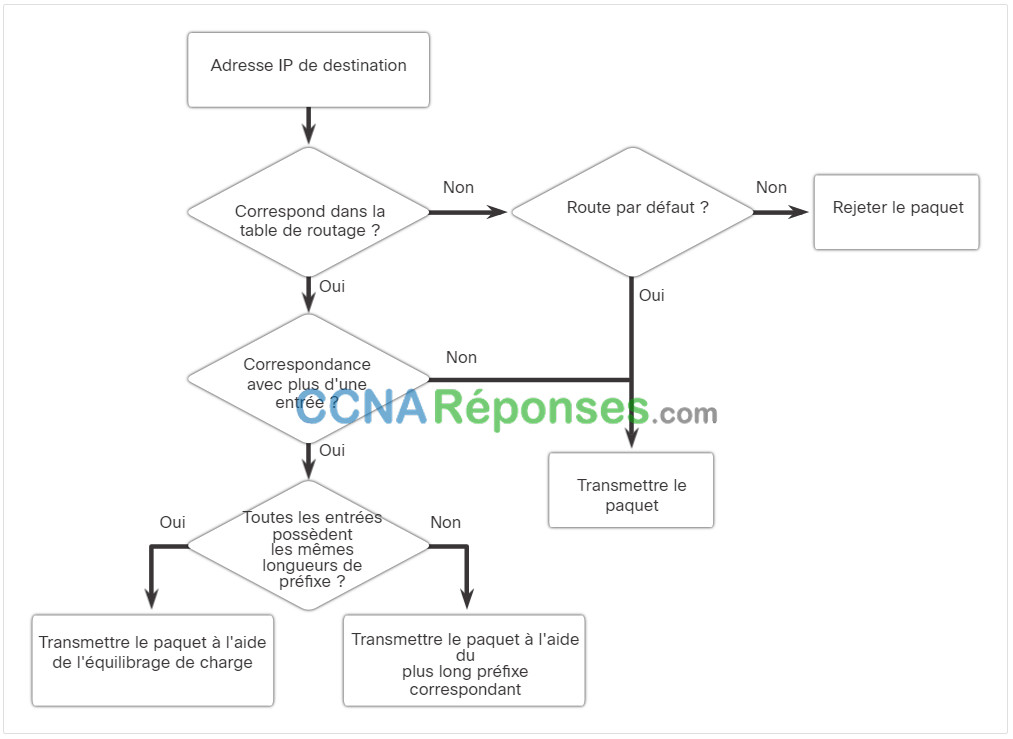
Adresse IP de destinationCorrespond dans la table de routage ?OuiCorrespondance avec plus d’une entrée ?Toutes les entrées possèdent
les mêmes
longueurs de préfixe ?NonNonNonOuiOuiNonOuiTransmettre le paquet à l’aide de l’équilibrage de chargeTransmettre le paquet à l’aide du
plus long préfixe correspondantTransmettre le paquetRejeter le paquetRoute par défaut ?
Examinez les scénarios suivants en fonction de l’organigramme ci-dessus. Si l’adresse de destination dans un paquet :
- Ne correspond pas à une entrée de la table de routage, la route par défaut est utilisée. Si aucune route par défaut n’est configurée, le paquet est rejeté.
- Correspond à une seule entrée de la table de routage, le paquet est transféré par l’interface définie dans cette route.
- Correspond à plusieurs entrées de la table de routage et que les entrées de routage possèdent la même longueur de préfixe, les paquets devant rejoindre cette destination peuvent être distribués parmi les routes définies dans la table de routage.
- Correspond à plusieurs entrées de la table de routage et que les entrées de routage possèdent des longueurs de préfixe différentes, les paquets devant rejoindre cette destination sont transférés depuis l’interface associée à la route qui présente le préfixe correspondant le plus long.
Exemple de dépannage
Les périphériques ne peuvent pas se connecter au serveur SRV1 à l’adresse 172.16.1.100. À l’aide de cette commande show ip route, l’administrateur doit vérifier si une entrée de routage existe vers le réseau 172.16.1.0/24. Si la table de routage ne possède pas de route spécifique vers le réseau de SRV1, l’administrateur réseau doit contrôler l’existence d’une entrée de route par défaut ou de route récapitulative en direction du réseau 172.16.1.0/24. Si aucune de ces entrées n’existe, il peut s’agir d’un problème de routage et l’administrateur doit alors vérifier que le réseau est inclus dans la configuration des protocoles de routage dynamique, ou ajouter une route statique.
12.5.10 Étape 6 – Vérification de la couche transport
Si la couche réseau semble fonctionner comme prévu, mais que les utilisateurs ne peuvent toujours pas accéder aux ressources, l’administrateur réseau doit commencer par dépanner les couches supérieures. Deux des problèmes les plus fréquents qui affectent la connectivité de la couche transport sont liés à la configuration des listes de contrôle d’accès et à la configuration NAT. Un outil couramment utilisé pour tester la fonctionnalité de la couche transport est l’utilitaire Telnet.
Caution: Si Telnet peut être utilisé pour tester la couche transport, pour des raisons de sécurité, SSH doit être utilisé pour gérer et configurer les appareils à distance.
Exemple de dépannage
Un administrateur réseau est en train de dépanner un problème où il ne peut pas se connecter à un routeur en utilisant le protocole HTTP. L’administrateur pings R2 comme indiqué dans la sortie de la commande.
R1# ping 2001:db8:acad:2::2 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 2001:DB8:ACAD:2::2, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 2/2/3 ms R1#
R2 répond et confirme que la couche réseau et toutes les couches situées sous la couche réseau sont opérationnelles. L’administrateur sait par conséquent que le problème se situe au niveau de la couche 4 ou d’une couche supérieure et il doit donc commencer par dépanner ces couches.
Ensuite, l’administrateur vérifie qu’ils peuvent envoyer du Telnet à R2 comme indiqué dans la sortie de la commande.
R1# telnet 2001:db8:acad:2::2 Trying 2001:DB8:ACAD:2::2 ... Open User Access Verification Password: R2> exit [Connection to 2001:db8:acad:2::2 closed by foreign host] R1#
L’administrateur a confirmé que les services Telnet s’exécutent sur R2. Bien que l’application serveur Telnet s’exécute sur le port 23, son port spécifique bien connu, et que les clients Telnet se connectent sur ce port par défaut, il est possible de spécifier un numéro de port différent sur le client pour se connecter à tout port TCP devant être testé. L’utilisation d’un autre port que le port TCP 23 indique si la connexion est acceptée (comme l’indique le mot « Open » dans la sortie), refusée, ou si le temps est écoulé. Il est possible de tirer des conclusions supplémentaires en matière de connectivité à partir de n’importe laquelle de ces réponses. Certaines applications, si elles utilisent un protocole de session ASCII, peuvent même afficher une bannière d’application et il est possible de déclencher certaines réponses du serveur en tapant des mots-clés spécifiques, comme dans le cas des protocoles SMTP, FTP et HTTP.
Par exemple, l’administrateur tente de Telnet à R2 en utilisant le port 80.
R1# telnet 2001:db8:acad:2::2 80 Trying 2001:DB8:ACAD:2::2, 80 ... Open ^C HTTP/1.1 400 Bad Request Date: Mon, 04 Nov 2019 12:34:23 GMT Server: cisco-IOS Accept-Ranges: none 400 Bad Request [Connection to 2001:db8:acad:2::2 closed by foreign host] R1#
La sortie vérifie une connexion réussie de la couche transport, mais R2 refuse la connexion en utilisant le port 80.
12.5.11 Étape 7 – Vérification des listes de contrôle d’accès
Sur les routeurs, il peut y avoir des ACLs qui interdisent aux protocoles de passer par l’interface dans le sens entrant ou sortant.
Utilisez la commande show ip access-lists pour afficher le contenu de toutes les ACL IPv4 et la commande show ipv6 access-list pour afficher le contenu de toutes les ACL IPv6 configurées sur un routeur. La ACL spécifique peut être affichée en entrant le nom ou le numéro de la ACL comme option pour cette commande. Les commandes show ip interfaces et show ipv6 interfaces affichent les informations d’interface IPv4 et IPv6 qui indiquent si des ACL IP sont définies sur l’interface.
Exemple de dépannage
Pour prévenir les attaques de type « spoofing », l’administrateur réseau a décidé de mettre en place un ACL qui empêche les appareils ayant une adresse réseau source de 172.16.1.0/24 d’entrer dans l’interface S0/0/1 entrante sur R3, comme le montre la figure. Le reste du trafic IP doit être autorisé.
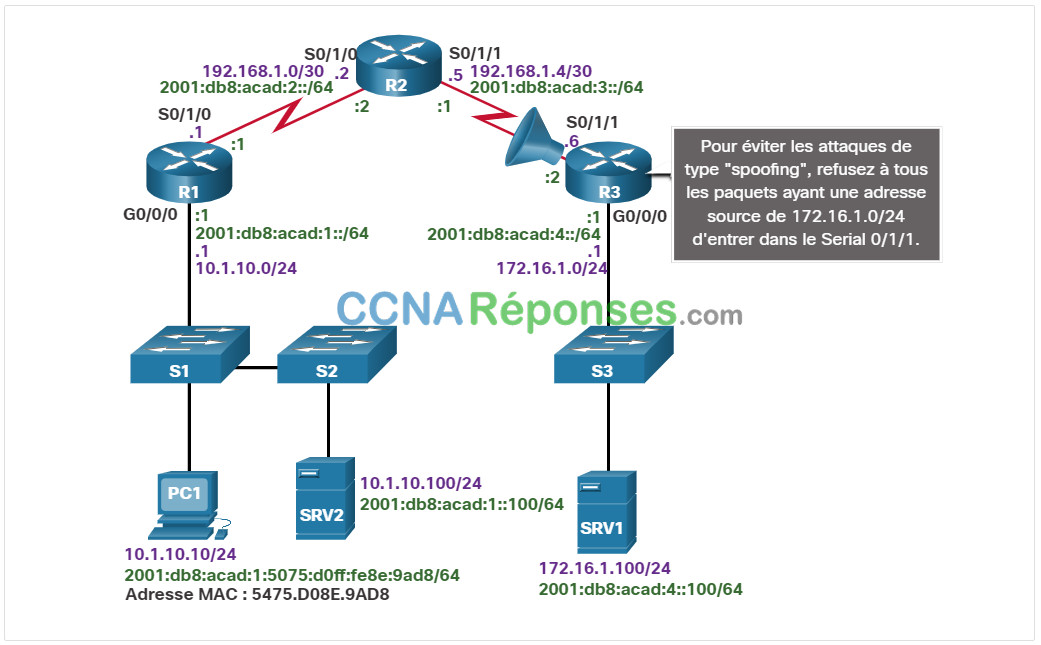
Toutefois, peu après l’implémentation de la liste de contrôle d’accès, les utilisateurs du réseau 10.1.10.0/24 n’ont pas pu se connecter aux périphériques présents sur le réseau 172.16.1.0/24, par exemple SRV1.
Cliquez sur chaque bouton pour obtenir un exemple de résolution de ce problème.
12.5.12 Étape 8 – Vérification du DNS
Le protocole DNS contrôle le DNS, à savoir une base de données distribuée avec laquelle vous pouvez mapper des noms d’hôtes vers des adresses IP. Lorsque vous configurez le DNS sur l’appareil, vous pouvez substituer le nom d’hôte à l’adresse IP par toutes les commandes IP, telles que ping ou telnet.
Pour afficher les informations de configuration DNS sur le commutateur ou le routeur, utilisez la commande show running-config. Lorsqu’aucun serveur DNS n’est installé, il est possible d’entrer des mappages de nom vers adresse IP directement dans la configuration du commutateur ou du routeur. Utilisez la commande ip host pour entrer un nom à utiliser à la place de l’adresse IPv4 du commutateur ou du routeur, comme indiqué dans la sortie de la commande.
R1(config)# ip host ipv4-server 172.16.1.100 R1(config)# exit R1#
Maintenant, le nom attribué peut être utilisé au lieu d’utiliser l’adresse IP, comme indiqué dans la sortie de la commande.
R1# ping ipv4-server Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.1.100, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 4/5/7 ms R1#
Pour afficher les informations de mappage de nom vers adresse IP sur le PC exécutant Windows, utilisez la commande nslookup.
12.5.13 Packet Tracer – Dépanner les réseaux d’entreprise
Cette activité utilise une variété de technologies que vous avez rencontrées au cours de vos études CCNA, y compris le routage, la sécurité des ports, EtherChannel, DHCP et NAT. Votre tâche consiste à examiner les spécifications, à isoler et résoudre tous les problèmes, et à documenter les étapes suivies en vue de vérifier ces spécifications.
12.6 Module pratique et questionnaire
12.6.1 Packet Tracer – Défi du dépannage – Documenter le réseau
Dans cette activité Tracer de paquets, vous documentez un réseau qui vous est inconnu.
- Test de la connectivité réseau
- Compiler les informations d’adressage de l’hôte.
- Accédez à distance aux périphériques de passerelle par défaut.
- Documentez les configurations de périphériques de passerelle par défaut.
- Découvrez les périphériques sur le réseau.
- Dessinez la topologie du réseau.
12.6.2 Packet Tracer – Confirmation de dépannage – Utilisation de la documentation pour résoudre des problèmes
Dans cette activité Packet Tracer, vous utilisez la documentation du réseau pour identifier et résoudre les problèmes de communication du réseau.
- Utiliser diverses techniques et outils pour identifier les problèmes de connectivité.
- Utilisez la documentation pour guider les efforts de dépannage.
- Identifier les problèmes de réseau spécifiques.
- Mettre en œuvre des solutions aux problèmes de communication réseau.
- Vérifier le fonctionnement du réseau.
12.6.3 Qu’est-ce que j’ai appris dans ce module?
Documentation du réseau
La documentation réseau commune comprend : les topologies de réseau physiques et logiques, la documentation de périphérique réseau enregistrant toutes les informations pertinentes sur les périphériques et la documentation de base sur les performances réseau. Les informations trouvées sur une topologie physique comprennent généralement le nom du périphérique, l’emplacement du périphérique (adresse, numéro de pièce, emplacement du rack, etc.), l’interface et les ports utilisés, ainsi que le type de câble. La documentation du périphérique réseau pour un routeur peut inclure l’interface, l’adresse IPv4, l’adresse IPv6, l’adresse MAC et le protocole de routage. La documentation du périphérique réseau pour un commutateur peut inclure le port, l’accès, le VLAN, le trunk, EtherChannel, natif et activé. La documentation des périphériques réseau pour les systèmes terminaux peut inclure le nom du périphérique, le système d’exploitation, les services, l’adresse MAC, les adresses IPv4 et IPv6, la passerelle par défaut et le DNS. Une base de référence de réseau devrait répondre aux questions suivantes :
- Quelles sont les performances du réseau pendant une journée normale ou moyenne ?
- Où survient le plus grand nombre d’erreurs ?
- Quelle partie du réseau est la plus utilisée ?
- Quelle partie du réseau est la moins utilisée ?
- Quels appareils doivent être surveillés et quels seuils d’alerte doivent être définis ?
- Le réseau peut-il satisfaire les politiques identifiées ?
Lors de la réalisation de la base de référence initiale, commencez par sélectionner quelques variables qui représentent les politiques définies, telles que l’utilisation de l’interface et l’utilisation du CPU. Un diagramme de topologie de réseau logique peut être utile pour identifier les dispositifs clés et les ports à surveiller. La durée et les informations de base recueillies doivent être suffisamment longues pour déterminer une image « normale » du réseau. Lorsque vous documentez le réseau, recueillez des informations directement auprès des routeurs et des commutateurs en utilisant les commandes show, ping, traceroute, and telnet.
Processus de dépannage
Le processus de dépannage doit être guidé par des méthodes structurées. Une méthode est le processus de dépannage en sept étapes : 1. Définissez le problème, 2. Rassembler des informations, 3. Analyser l’information, 4. Éliminer les causes possibles, 5. Proposer une hypothèse, 6. Hypothèse de test, et 7. Résoudre le problème Lorsque vous parlez aux utilisateurs finaux de leurs problèmes de réseau, posez des questions ouvertes et fermées. Utilisez les commandes show, ping, traceroute, et telnet pour collecter des informations à partir de périphériques. Utilisez les modèles en couches pour effectuer un dépannage ascendant, descendant ou diviser et conquérir. D’autres modèles comprennent le suivi du chemin, la substitution, la comparaison et la devinette instruite. Les problèmes logiciels sont souvent résolus à l’aide d’une approche descendante tandis que les problèmes matériels sont résolus à l’aide de l’approche ascendante. De nouveaux problèmes peuvent être résolus par un technicien expérimenté utilisant la méthode de division et de conquête.
Outils de dépannage
Les outils de dépannage logiciels courants incluent les outils NMS, les bases de connaissances et les outils de base. Un analyseur de protocole décode les différentes couches de protocole dans une trame enregistrée et présente ces informations dans un format relativement facile à utiliser. Les outils de dépannage matériel comprennent un NAM, les multimètres numériques, les testeurs de câbles, les analyseurs de câbles et les analyseurs de réseau portables. Le serveur Syslog peut également être utilisé comme outil de dépannage. L’implémentation d’une méthode de journalisation est une partie importante de la sécurité du réseau et du dépannage réseau. Les périphériques Cisco peuvent consigner des informations relatives aux modifications de configuration, aux violations des listes de contrôle d’accès, à l’état des interfaces ainsi qu’à de nombreux autres types d’événements. Les messages d’événement peuvent être envoyés à un ou plusieurs des éléments suivants : console, lignes de terminal, journalisation en mémoire tampon, interruptions SNMP et syslog. Plus le numéro de niveau est faible, plus le niveau de gravité est important. La commande logging trap level limite les messages enregistrés sur le serveur syslog en fonction de leur gravité. Le niveau est le nom ou le numéro du niveau de gravité Seuls les messages égaux ou numériquement inférieurs au niveau spécifié sont enregistrés.
Symptômes et causes des problèmes de réseau
Les défaillances et les conditions sous-optimales de la couche physique entraînent généralement l’arrêt des réseaux. Les administrateurs réseau doivent être en mesure d’isoler et de corriger efficacement les problèmes au niveau de cette couche. Les symptômes incluent des performances inférieures à la ligne de base, une perte de connectivité, une congestion, une utilisation élevée du processeur et des messages d’erreur de la console. Les causes sont généralement liées à l’alimentation, aux défaillances matérielles, aux défaillances de câblage, à l’atténuation, au bruit, aux erreurs de configuration de l’interface, au dépassement des limites de conception des composants et à la surcharge du processeur.
Les problèmes de la couche de liaison des données provoquent des symptômes spécifiques qui, lorsqu’ils sont reconnus, permettent d’identifier rapidement le problème. Parmi les symptômes, mentionnons l’absence de fonctionnalité/connectivité à la couche 2 ou supérieure, le réseau fonctionnant en dessous des niveaux de base, les diffusions excessives et les messages de la console. Les causes sont généralement des erreurs d’encapsulation, des erreurs de mappage d’adresses, des erreurs de cadrage et des échecs STP ou des boucles.
Les problèmes de couche réseau incluent tous les problèmes relatifs à un protocole de couche 3, à savoir à la fois les protocoles routés (tels que les protocoles IPv4 et IPv6) et les protocoles de routage (tels que les protocoles EIGRP, OSPF, etc.). Les symptômes incluent une défaillance du réseau et des performances sous-optimales. Les causes sont généralement des problèmes de réseau généraux, des problèmes de connectivité, des problèmes de table de routage, des problèmes de voisinage et de la base de données de topologie.
Des problèmes réseau peuvent survenir à partir de problèmes de couche transport sur le routeur, en particulier au niveau de la périphérie du réseau où le trafic est examiné et modifié. Les symptômes incluent des problèmes de connectivité et d’accès. Les causes sont susceptibles d’être mal configurées NAT ou ACL. Les erreurs de configuration des ACL se produisent fréquemment lors de la sélection du flux de trafic, de l’ordre des entrées de contrôle d’accès, des refus implicites, des adresses et des masques génériques IPv4, de la sélection du protocole de la couche transport, des ports source et destination, de l’utilisation du mot-clé établi et des protocoles peu courants. Il y a plusieurs problèmes avec la NAT, notamment une mauvaise configuration de la NAT à l’intérieur, de la NAT à l’extérieur ou des ACL. Les zones d’interopérabilité communes avec NAT comprennent BOOTP et DHCP, DNS, SNMP, ainsi que les protocoles de tunneling et de cryptage.
Un problème au niveau de la couche application peut conduire à des ressources inaccessibles ou inutilisables, même si les couches physique, liaison de données, réseau et transport fonctionnent correctement. Il se peut que la connectivité réseau soit complète, mais l’application ne peut tout simplement pas fournir de données. Un autre type de problème de couche application se produit lorsque les couches physique, liaison de données, réseau et transport fonctionnent correctement, mais que le transfert de données et les requêtes de services réseau à partir d’un service réseau ou d’une application unique ne correspondent pas aux attentes normales d’un utilisateur.
Dépannage de la connectivité IP
Le diagnostic et la résolution de problèmes sont des compétences essentielles des administrateurs réseau. Il n’existe pas de recette unique pour résoudre les problèmes, et un problème peut être diagnostiqué de plusieurs façons. Toutefois, grâce à la mise en œuvre d’une approche structurée pour le processus de dépannage, un administrateur peut diminuer le temps nécessaire au diagnostic et à la résolution d’un problème.
Les problèmes de connectivité de bout en bout sont généralement à l’origine d’un effort de dépannage. Deux des utilitaires les plus courants utilisés pour vérifier un problème de connectivité de bout en bout sont ping et traceroute. la commande ping utilise un protocole de couche 3 qui fait partie de la suite TCP/IP appelée ICMP. La commande traceroute est généralement exécutée lorsque la commande ping échoue.
Étape 1. Vérifiez la couche physique. Les commandes Cisco IOS les plus couramment utilisées à cette fin sont show processes cpu, show memory, et show interfaces.
Étape 2. Vérifiez les incohérences de duplex. Une autre cause courante d’erreur d’interface est une incohérence dans les paramètres bidirectionnels entre les deux extrémités d’une liaison Ethernet. Dans de nombreux réseaux Ethernet, les connexions point à point constituent aujourd’hui la norme tandis que l’utilisation de concentrateurs avec le fonctionnement associé en mode bidirectionnel non simultané est devenue moins courante. Utilisez la commande show interfaces interface pour diagnostiquer ce problème.
Étape 3. Vérifiez l’adressage sur le réseau local. Lors d’un dépannage de la connectivité de bout en bout, il est utile de vérifier les mappages entre les adresses IP de destination et les adresses Ethernet de couche 2 sur des segments individuels. La commande Windows arp affiche et modifie les entrées dans le cache ARP qui sont utilisées pour stocker les adresses IPv4 et leurs adresses physiques Ethernet (MAC) résolues. La commande Windows netsh interface ipv6 show neighbor répertorie l’ensemble des périphériques figurant actuellement dans la table de voisinage. La sortie de la commande show ipv6 neighbors affiche un exemple de table de voisinage sur le routeur Cisco IOS. Utilisez la commande show mac address-table pour afficher le tableau des adresses MAC sur l’interrupteur.
Un autre problème à prendre en considération lors du dépannage de la connectivité de bout en bout est l’attribution de VLAN. Utilisez la commande arp Windows pour afficher l’entrée d’une passerelle par défaut. Utilisez la commande show mac address-table pour vérifier la table MAC du commutateur. Cela peut montrer que les attributions de VLAN ne sont pas correctes.
Étape 4. Vérifier la passerelle par défaut. La sortie de commande de la commande show ip route Cisco IOS est utilisée pour vérifier la passerelle par défaut d’un routeur. Sur un hôte Windows, la commande Windows route print permet de vérifier la présence de la passerelle par défaut.
Dans IPv6, la passerelle par défaut peut être configurée manuellement, à l’aide de l’auto configuration sans état (SLAAC) ou du DHCPv6. La commande show ipv6 route Cisco IOS est utilisée pour vérifier la route IPv6 par défaut sur un routeur. La commande Windows ipconfig permet de vérifier si un PC1 possède une passerelle IPv6 par défaut. La sortie de commande du show ipv6 interface interface vous indiquera si un routeur est ou n’est pas activé en tant que routeur IPv6. Activez un routeur en tant que routeur à l’aide de la commande ipv6 unicast-routing. Pour vérifier qu’un hôte a défini la passerelle par défaut, utilisez la commande ipconfig sur le PC Microsoft Windows ou la commande netstat -r ou ip route sur Linux et Mac OS X.
Étape 5. Vérifiez le chemin correct. Les routeurs dans le chemin prennent la décision de routage sur la base des informations contenues dans les tables de routage. Utilisez la commande show ip route | begin Gateway pour une table de routage IPv4. Utilisez la commande show ipv6 route pour une table de routage IPv6.
Étape 6. Vérifiez la couche de transport. Deux des problèmes les plus fréquents qui affectent la connectivité de la couche transport sont liés à la configuration des listes de contrôle d’accès et à la configuration NAT. Un outil couramment utilisé pour tester la fonctionnalité de la couche transport est l’utilitaire Telnet.
Étape 7. Vérifiez les ACLs. Utilisez la commande show ip access-lists pour afficher le contenu de toutes les ACL IPv4 et la commande show ipv6 access-list pour afficher le contenu de toutes les ACL IPv6 configurées sur un routeur. Vérifiez à quelle interface a été appliquée à l’aide de la commande show ip interfaces.
Étape 8. Vérifiez le DNS. Pour afficher les informations de configuration DNS sur le commutateur ou le routeur, utilisez la commande show running-config. Utilisez la commande ip host pour entrer un nom à utiliser à la place de l’adresse IPv4 du commutateur ou du routeur, comme indiqué dans la sortie de la commande.