14.0 Introduction
14.0.1 Pourquoi devrais-je suivre ce module?
Bienvenue sur la couche Transport !
La couche de transport est l’endroit où, comme son nom l’indique, les données sont transportées d’un hôte à un autre. C’est là que votre réseau se déplace vraiment ! La couche transport utilise deux protocoles : TCP et UDP. Pensez à TCP comme recevoir une lettre recommandée par la poste. Vous devez signer pour cela avant que le transporteur ne vous le laisse. Cela ralentit un peu le processus, mais l’expéditeur sait avec certitude que vous avez reçu la lettre et quand vous l’avez reçue. UDP ressemble plus à une lettre régulière, estampillée. Il arrive dans votre boîte aux lettres et, si c’est le cas, il est probablement destiné à vous, mais il pourrait en fait être pour quelqu’un d’autre qui n’y vit pas. En outre, il peut ne pas arriver du tout dans votre boîte aux lettres. L’expéditeur ne peut pas être sûr de l’avoir reçu. Néanmoins, il y a des moments où UDP, comme une lettre estampillée, est le protocole qui est nécessaire. Cette rubrique explique comment fonctionnent TCP et UDP dans la couche de transport. Plus loin dans ce module, il y a plusieurs vidéos pour vous aider à comprendre ces processus.
14.0.2 Qu’est-ce que je vais apprendre dans ce module?
Titre du module: Couche Transport
Objectif du module: Comparer les opérations des protocoles de la couche de transport dans la prise en charge de la communication de bout en bout.
| Titre du rubrique | Objectif du rubrique |
|---|---|
| Transport des données | Expliquer l’objectif de la couche de transport dans la gestion du transport de données dans la communication de bout en bout. |
| Présentation du protocole TCP | Expliquer les caractéristiques du TCP. |
| Aperçu de l’UDP | Expliquer les caractéristiques de l’UDP. |
| Numéros de port | Expliquez comment TCP et UDP utilisent les numéros de port. |
| Processus de communication TCP | Expliquer comment les processus d’établissement et de fin de session TCP facilitent une communication fiable. |
| Fiabilité et contrôle des flux | Expliquer comment les unités de données du protocole TCP sont transmises et reconnues pour garantir la livraison. |
| Communication UDP | Comparer les opérations des protocoles de la couche transport dans la prise en charge de la communication de bout en bout. |
14.1 Transport des données
14.1.1 Rôle de la couche transport
Les programmes de la couche application génèrent des données qui doivent être échangées entre les hôtes source et destination. La couche de transport est responsable des communications logiques entre les applications exécutées sur différents hôtes. Cela peut inclure des services tels que l’établissement d’une session temporaire entre deux hôtes et la transmission fiable d’informations pour une application.
Comme le montre l’illustration, la couche transport constitue la liaison entre la couche application et les couches inférieures chargées de la transmission sur le réseau.
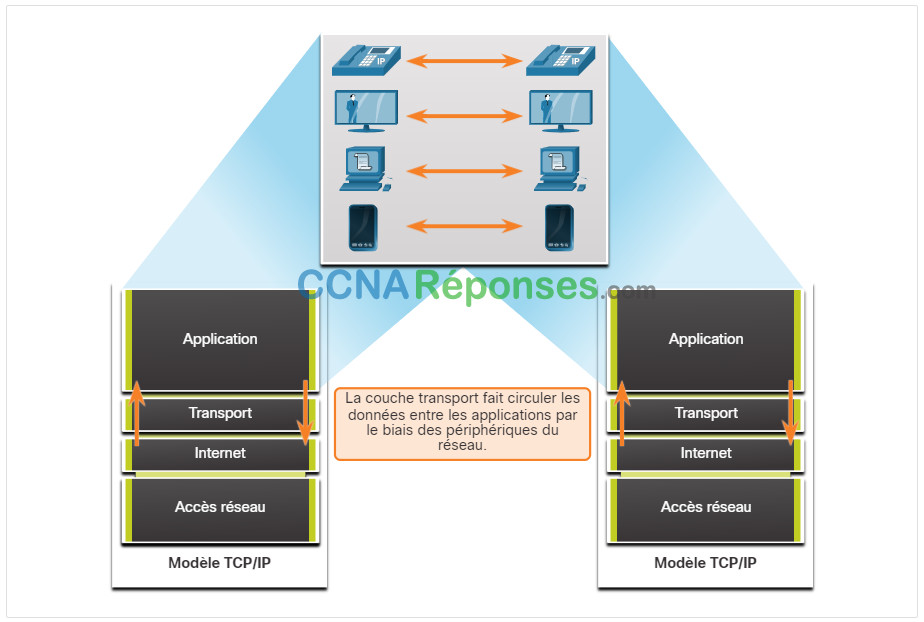
La couche transport ne connaît pas le type d’hôte de destination, le type de support sur lequel les données doivent voyager, le chemin emprunté par les données, l’encombrement d’une liaison ou la taille du réseau.
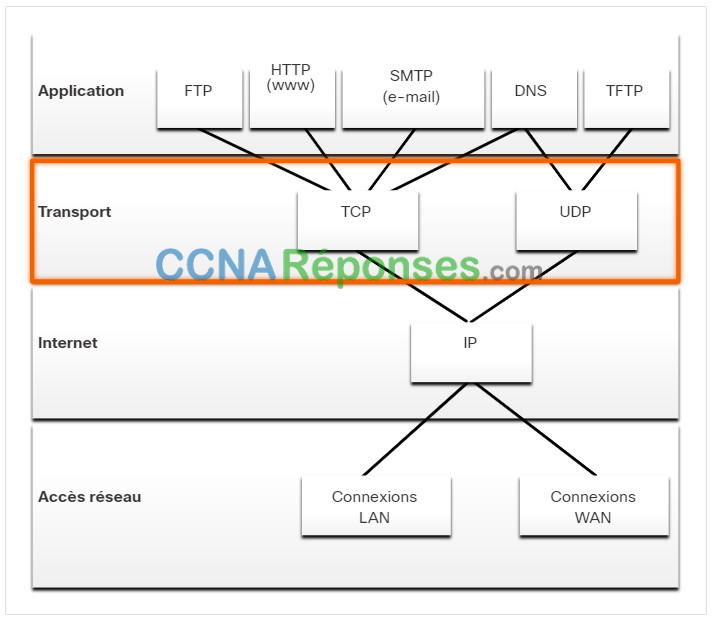
La couche de transport comprend deux protocoles:
- Protocole TCP (Transmission Control Protocol)
- Protocole UDP (User Datagram Protocol)
14.1.2 Responsabilités de la couche transport
La couche transport a de nombreuses responsabilités.
Cliquez sur chaque bouton pour obtenir plus d’informations.
- Suivi des conversations individuelles
- Segmentation des données et reconstitution des segments
- Ajouter des informations d'en-tête
- Identification des applications
- Multiplexage de conversations
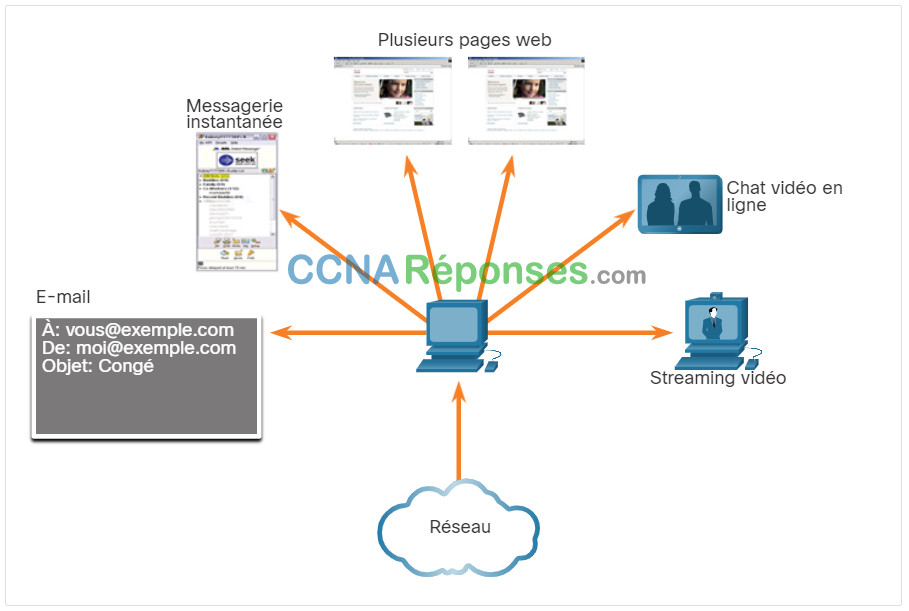
Au niveau de la couche transport, chaque ensemble de données circulant entre une application source et une application destination est connu sous le nom de conversation et est suivi séparément. La couche transport est chargée de garantir ces multiples conversations et d'en effectuer le suivi.
Comme l'illustre la figure, un hôte peut avoir plusieurs applications qui communiquent simultanément sur le réseau.
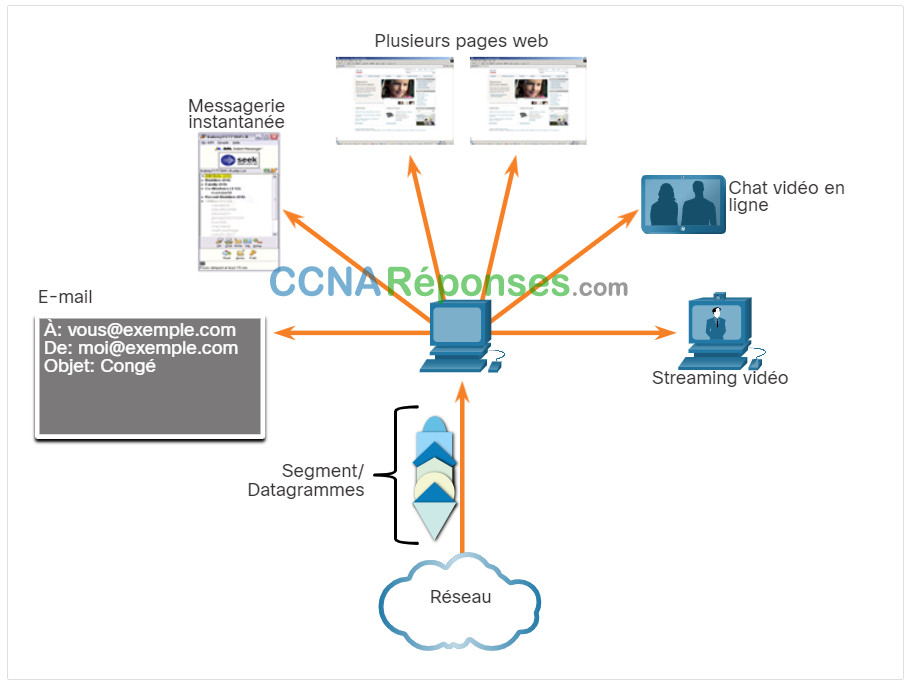
La plupart des réseaux limitent la quantité de données pouvant être incluses dans un paquet. Par conséquent, les données doivent être divisées en morceaux gérables.
C'est la responsabilité de la couche de transport de diviser les données de l'application en blocs de taille appropriée. Selon le protocole de couche de transport utilisé, les blocs de couche de transport sont appelés segments ou datagrammes. La figure illustre la couche de transport en utilisant différents blocs pour chaque conversation.
La couche de transport divise les données en blocs plus petits (c'est-à-dire des segments ou des datagrammes) qui sont plus faciles à gérer et à transporter.
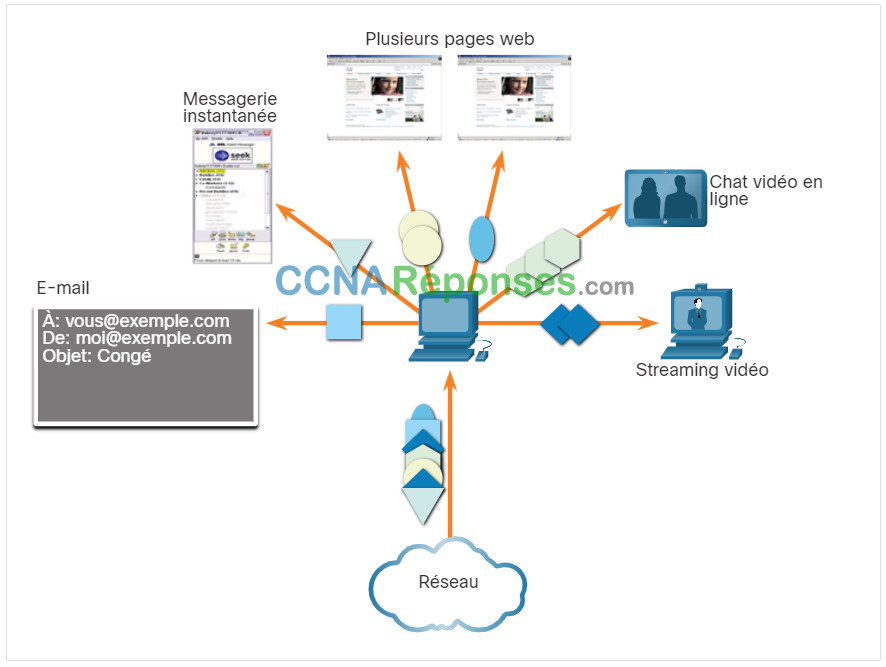
Le protocole de la couche transport ajoute également à chaque bloc de données des informations d'en-tête contenant des données binaires organisées en plusieurs champs. Ce sont les valeurs contenues dans ces champs qui permettent aux différents protocoles de couche transport d'exécuter des fonctions diverses de gestion des communications de données.
Par exemple, les informations d'en-tête sont utilisées par l'hôte récepteur pour réassembler les blocs de données dans un flux de données complet pour le programme de couche d'application de réception.
La couche transport s'assure que même lorsque plusieurs applications s'exécutent sur un périphérique, toutes les applications reçoivent les données correctes.
La couche transport doit pouvoir segmenter et gérer plusieurs communications ayant des exigences différentes en matière de transport. Pour transmettre les flux de données aux applications appropriées, la couche transport identifie l'application cible à l'aide d'un identifiant appelé numéro de port. Comme l'illustre la figure, chaque processus logiciel qui doit accéder au réseau se voit attribuer un numéro de port unique à cet hôte.

L'envoi de certains types de données (par exemple, une vidéo en continu) sur un réseau, en tant que flux de communication complet, peut consommer toute la largeur de bande disponible. De fait, cela empêche d'autres communications d'avoir lieu en même temps. En outre, cela rend également difficiles la reprise sur erreur et la retransmission des données endommagées.
Comme le montre la figure, la couche de transport utilise la segmentation et le multiplexage pour permettre à différentes conversations de communication d'être entrelacées sur le même réseau.
La vérification des erreurs peut être effectuée sur les données du segment, afin de déterminer si le segment a été altéré pendant la transmission.

14.1.3 Protocoles de couche transport
IP ne s’occupe que de la structure, de l’adressage et du routage des paquets. Il ne fixe pas le mode d’acheminement ou de transport des paquets.
Les protocoles de La couche de transport spécifient comment transférer des messages entre les hôtes et ils sont responsables de la gestion des exigences de fiabilité d’une conversation. La couche transport comprend les protocoles TCP et UDP.
Des applications différentes ont des exigences différentes en matière de fiabilité du transport. Par conséquent, TCP/IP fournit deux protocoles de couche de transport, comme indiqué sur la figure.
14.1.4 Protocole TCP (Transmission Control Protocol)
L’IP ne concerne que de la structure, l’adressage et le routage des paquets, de l’expéditeur initial à la destination finale. IP n’est pas responsable de garantir la livraison ou de déterminer si une connexion entre l’expéditeur et le destinataire doit être établie.
Le protocole TCP est un protocole de couche transport fiable et complet, qui garantit que toutes les données arrivent à la destination. TCP inclut des champs qui assurent la livraison des données de l’application. Ces champs nécessitent un traitement supplémentaire par les hôtes d’envoi et de réception.
Remarque: Le protocole TCP divise les données en segments.
Le transport TCP revient à envoyer des paquets qui sont suivis de la source à la destination. Si la commande à expédier est divisée en plusieurs colis, un client peut vérifier en ligne l’ordre des livraisons.
TCP assure la fiabilité et le contrôle du flux en utilisant les opérations de base suivantes:
- Numéroter et suivre les segments de données transmis à un hôte spécifique à partir d’une application spécifique
- Accuser la réception des données reçues
- Retransmettre toute donnée non reconnue après un certain temps
- Données de séquence qui pourraient arriver dans le mauvais ordre
- Envoyer des données à un taux efficace et acceptable par le destinataire
Afin de maintenir l’état d’une conversation et de suivre les informations, TCP doit d’abord établir une connexion entre l’expéditeur et le destinataire. Le protocole TCP est un protocole connexion orienté.
Cliquez sur Lecture dans l’illustration pour voir comment des accusés de réception et des segments TCP sont transmis entre un expéditeur et son destinataire.
14.1.5 Protocole UDP (User Datagram Protocol)
UDP est un protocole de couche de transport plus simple que TCP. Il ne fournit pas de fiabilité et de contrôle de flux, ce qui signifie qu’il nécessite moins de champs d’en-tête. Étant donné que les processus UDP de l’expéditeur et du récepteur n’ont pas à gérer la fiabilité et le contrôle de flux, cela signifie que les datagrammes UDP peuvent être traités plus rapidement que les segments TCP. UDP fournit des fonctions de base permettant d’acheminer des segments de données entre les applications appropriées tout en ne nécessitant que très peu de surcharge et de vérification des données.
Remarque: UDP divise les données en datagrammes qui sont également appelés segments.
UDP est un protocole sans connexion. Étant donné que UDP ne fournit pas de fiabilité ou de contrôle de débit, il ne nécessite pas de connexion établie. Car UDP ne suit pas les informations envoyées ou reçues entre le client et le serveur, UDP est également connu sous le nom de protocole sans état.
UDP est également connu comme un protocole de livraison du meilleur effort, car il n’y a pas d’accusé de réception des données à la destination. Avec l’UDP, il n’y a pas de processus de la couche transport qui informe l’expéditeur d’une livraison réussie.
L’UDP est comme le dépôt d’une lettre ordinaire, non recommandée, dans le courrier. L’expéditeur de la lettre ne sait pas si le destinataire pourra la recevoir. En outre, le bureau de poste n’est pas responsable du suivi de la lettre et ne doit pas non plus informer l’expéditeur si elle n’atteint pas sa destination finale.
Cliquez sur Lecture dans la figure pour voir une animation des datagrammes UDP transmis de l’émetteur au récepteur.
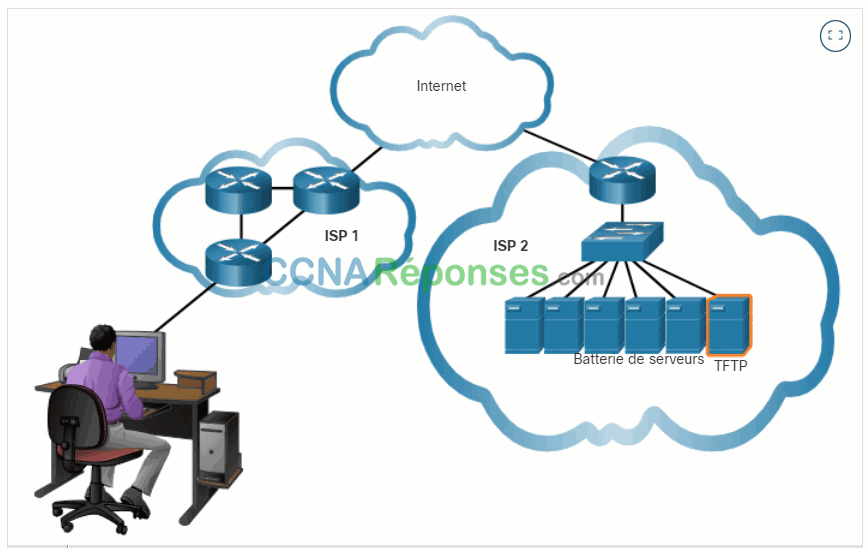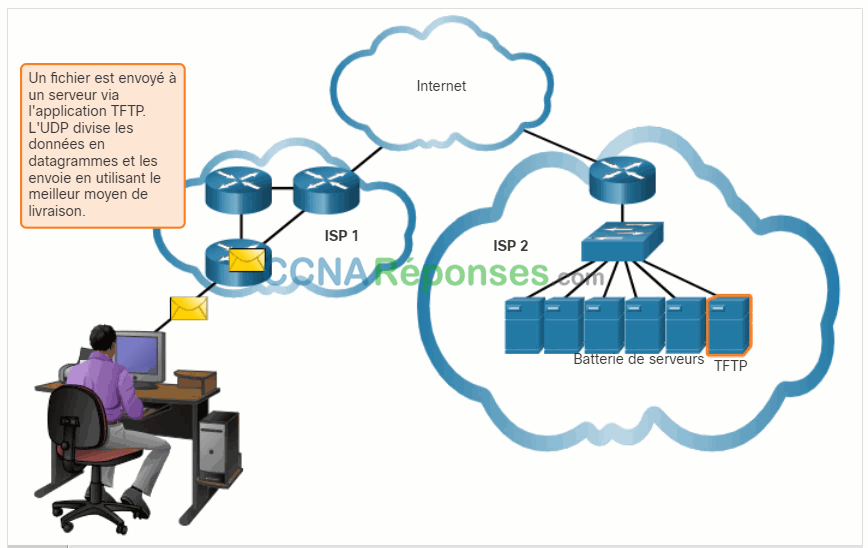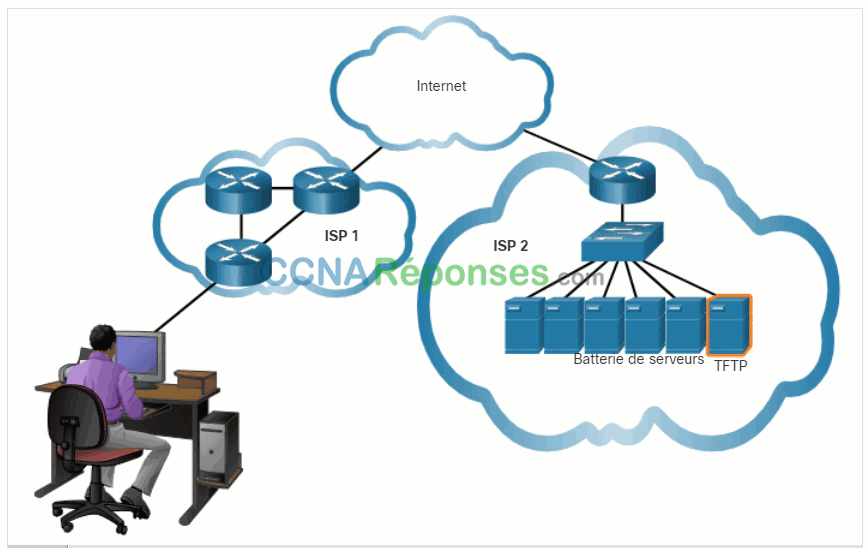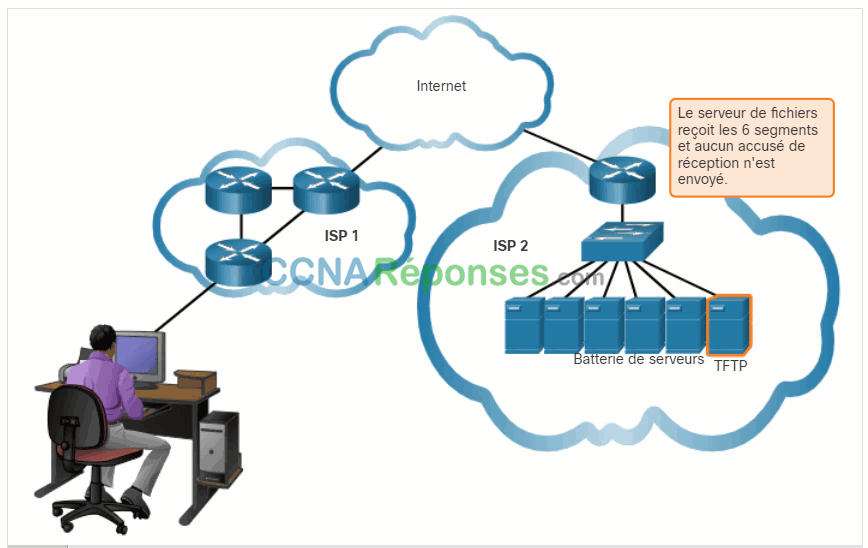
14.1.6 Choix du protocole de couche transport le mieux adapté à une application donnée
Certaines applications peuvent tolérer une certaine perte de données lors de la transmission sur le réseau, mais les retards de transmission sont inacceptables. Pour ces applications, l’UDP est le meilleur choix car il nécessite moins de surcharge du réseau. L’UDP est préférable pour les applications telles que la voix sur IP (VoIP). Les accusés de réception et la retransmission ralentiraient la livraison et rendraient la conversation vocale inacceptable.
UDP est également utilisé par les applications de demande et de réponse où les données sont minimales, et la retransmission peut être effectuée rapidement. Par exemple, le service de noms de domaine (DNS) utilise UDP pour ce type de transaction. Le client demande des adresses IPv4 et IPv6 pour un nom de domaine connu à partir d’un serveur DNS. Si le client ne reçoit pas de réponse dans un délai prédéterminé, il envoie simplement la demande à nouveau.
Par exemple, si au cours d’une lecture vidéo, un ou deux segments n’arrivent pas, cela entraîne une interruption momentanée du flux. Cela peut se traduire par une distorsion de l’image ou du son, que l’utilisateur ne remarque peut-être même pas. Si par contre le périphérique de destination doit tenir compte de la perte de données, il se peut que le flux soit retardé à cause des retransmissions qu’il attend, causant ainsi une forte dégradation de la qualité de l’image ou du son. Dans ce cas, il est préférable de fournir la meilleure qualité possible en fonction des segments reçus et de renoncer à la fiabilité.
Pour d’autres applications, il est important que toutes les données arrivent et qu’elles puissent être traitées dans leur ordre approprié. Pour ces types d’applications, TCP est utilisé comme protocole de transport. Par exemple, les applications telles que les bases de données, les navigateurs web et les clients de messagerie ont besoin que toutes les données envoyées arrivent à destination dans leur état d’origine. Toute donnée manquante pourrait corrompre une communication, la rendre soit incomplète soit illisible. Par exemple, lorsqu’on accède aux informations bancaires sur le Web, il est important de s’assurer que toutes les informations sont envoyées et reçues correctement.
Les développeurs d’applications doivent déterminer quel type de protocole de transport est approprié en fonction des exigences des applications. La vidéo peut être envoyée via TCP ou UDP. Les applications qui diffusent en continu des données audio et vidéo stockées utilisent généralement le protocole TCP. L’application utilise TCP pour effectuer la mise en mémoire tampon, la détection de la bande passante et le contrôle de la congestion, afin de mieux contrôler l’expérience utilisateur.
La vidéo et la voix en temps réel utilisent généralement UDP, mais peuvent également utiliser TCP, ou les deux UDP et TCP. Une application de vidéo conférence peut utiliser UDP par défaut, mais comme de nombreux pare-feu bloquent UDP, l’application peut également être envoyée par TCP.
Les applications qui diffusent en continu des données audio et vidéo stockées utilisent le protocole TCP. Par exemple, si votre réseau ne peut soudainement plus prendre en charge la bande passante nécessaire pour regarder un film à la demande, l’application interrompt la lecture. Pendant cette interruption, un message de mise en tampon peut apparaître tandis que le protocole TCP s’efforce de rétablir le flux de données. Lorsque tous les segments sont en ordre et qu’un niveau minimum de bande passante est rétabli, votre session TCP reprend, et la lecture du film reprend.
La figure résume les différences entre l’UDP et le TCP.

14.2 Présentation du protocole TCP
14.2.1 Fonctions du protocole TCP
Dans la rubrique précédente, vous avez appris que TCP et UDP sont les deux protocoles de couche de transport. Cette rubrique donne plus de détails sur ce que fait TCP et quand il est conseillé de l’utiliser au lieu d’UDP.
Pour comprendre les différences entre TCP et UDP, il est important de comprendre comment chaque protocole met en œuvre des caractéristiques de fiabilité spécifiques et comment chaque protocole suit les conversations.
En plus de soutenir les fonctions de base de la segmentation et du réassemblage des données, le TCP fournit également les services suivants :
- Établit une session – TCP est un protocole connexion orienté qui négocie et établit une connexion (ou session) permanente entre les appareils source et destination avant d’acheminer tout trafic. Grâce à l’établissement de la session, les périphériques négocient la quantité de trafic pouvant être transmise à un moment donné et les données de communication peuvent être étroitement gérées.
- Garantit une livraison fiable – Pour de nombreuses raisons, il est possible qu’un segment soit corrompu ou complètement perdu lors de sa transmission sur le réseau. TCP s’assure que chaque segment envoyé par la source arrive à la destination
- Fournit la livraison dans le même ordre – Parce que les réseaux peuvent fournir plusieurs routes qui peuvent avoir des taux de transmission différents, les données peuvent arriver dans le mauvais ordre. En numérotant et en séquençant les segments, TCP s’assure que les segments sont réassemblés dans le bon ordre.
- Soutien le contrôle des flux – Les hôtes du réseau ont des ressources limitées (c’est-à-dire, mémoire et puissance de traitement). Quand le protocole TCP détermine que ces ressources sont surexploitées, il peut demander à l’application qui envoie les données d’en réduire le flux. Cela se fait par le TCP qui régule la quantité de données transmises par la source. Le contrôle du flux contribue à rendre inutile la retransmission des données lorsque les ressources de l’hôte de réception sont saturées.
Pour plus d’informations sur TCP, recherchez la RFC 793 sur Internet.
14.2.2 En-tête TCP
TCP est un protocole avec état, ce qui signifie qu’il garde une trace de l’état de la session de communication. Pour suivre l’état d’une session, le protocole TCP enregistre les informations qu’il a envoyées et les informations qu’il a reçues. La session en état commence avec l’établissement de la session et se termine avec la clôture de la session.
Un segment TCP ajoute 20 octets (c’est-à-dire 160 bits) de surcharge lors de l’encapsulation des données de la couche d’application. La figure montre les champs d’un en-tête TCP.
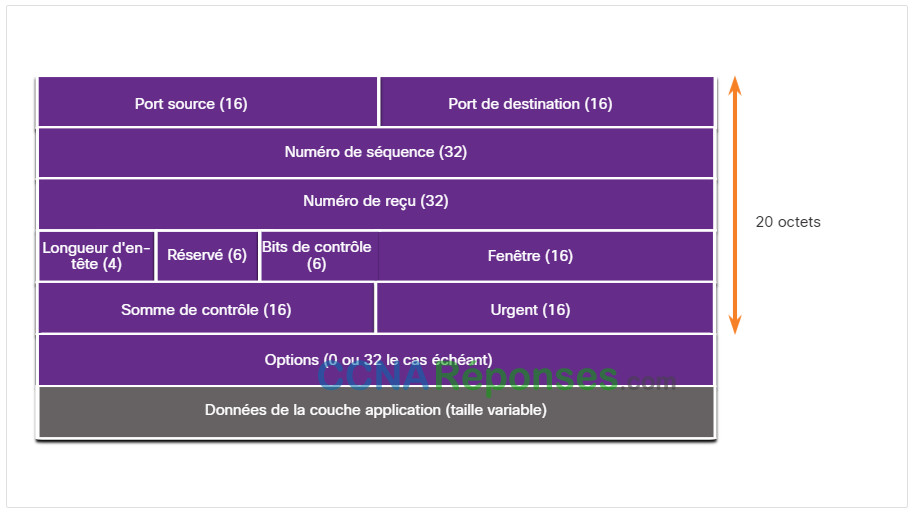
14.2.3 Champs d’en-tête TCP
Le tableau identifie et décrit les dix champs d’un en-tête TCP.
| Champ d’en-tête TCP | Description |
|---|---|
| Port source | Champ 16 bits utilisé pour identifier l’application source par le numéro de port. |
| Port de destination | Champ 16 bits utilisé pour identifier l’application de destination par numéro de port. |
| Numéro d’ordre | Champ 32 bits utilisé à des fins de réassemblage de données. |
| Numéro d’accusé de réception | Champ 32 bits utilisé pour indiquer que les données ont été reçues et que le prochain octet est attendu de la source. |
| Longueur d’en-tête | Un champ 4 bits connu sous le nom de «offset de données» qui indique la longueur de l’en-tête du segment TCP. |
| Réservé | Un champ de 6 bits qui est réservé pour une utilisation future. |
| Bits de contrôle | Champ 6 bits qui inclut des codes de bits, ou des indicateurs, qui indiquent l’objectif et la fonction du segment TCP. |
| Taille de fenêtre | Champ 16 bits utilisé pour indiquer le nombre d’octets pouvant être acceptés à un moment donné. |
| Somme de contrôle | Un champ de 16 bits utilisé pour la vérification des erreurs de l’en-tête du segment et des données. |
| Urgent | Champ 16 bits utilisé pour indiquer si les données contenues sont urgentes. |
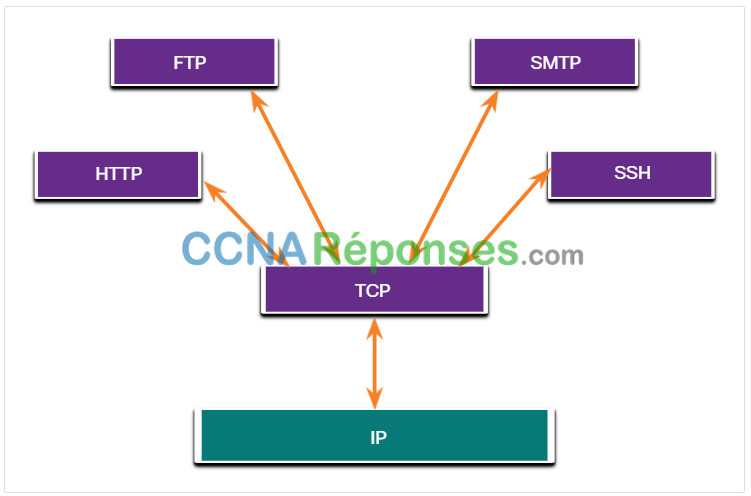
14.2.4 Applications utilisant le protocole TCP
TCP est un bon exemple de la manière dont les différentes couches de la suite de protocoles TCP/IP ont des rôles spécifiques. Le TCP gère toutes les tâches associées à la division du flux de données en segments, à la fiabilité, au contrôle du flux de données et à la réorganisation des segments. Le protocole TCP libère l’application de la gestion de l’ensemble de ces tâches. Les applications, telles que celles illustrées dans la figure, peuvent simplement envoyer le flux de données à la couche transport et utiliser les services du protocole TCP.
14.3 Aperçu de l’UDP
14.3.1 Fonctions du protocole UDP
Cette rubrique couvrira UDP, ce qu’il fait et quand il est conseillé de l’utiliser au lieu de TCP. UDP est un protocole de transport optimal. UDP est un protocole de transport léger qui offre la même segmentation et le même réassemblage de données que TCP, mais sans la fiabilité et le contrôle de flux de TCP.
UDP est un protocole tellement simple qu’il est généralement décrit en termes de ce qu’il ne fait pas par rapport à TCP.
Les caractéristiques de l’UDP sont les suivantes :
- Les données sont reconstituées selon l’ordre de réception.
- Les segments qui sont perdus ne sont pas renvoyés.
- Il n’y a pas d’établissement de session.
- L’expéditeur n’est pas informé de la disponibilité des ressources.
Pour plus d’informations sur l’UDP, recherchez le RFC sur Internet.
14.3.2 En-tête UDP
L’UDP est un protocole sans état, ce qui signifie que ni le client, ni le serveur, ne suit l’état de la session de communication. Si la fiabilité est nécessaire dans le cadre de l’utilisation d’UDP comme protocole de transport, elle doit être prise en charge par l’application.
L’une des conditions les plus importantes pour fournir une vidéo en direct et faire transiter des données vocales sur un réseau est que le flux de données soit rapide. Les applications vidéo en direct et de communication vocale peuvent tolérer certaines pertes de données, dont l’impact est faible ou indétectable, et sont donc parfaitement adaptées au protocole UDP.
Les blocs de communication dans l’UDP sont appelés datagrammes, ou segments. Ces datagrammes sont envoyés au mieux par le protocole de la couche transport.
L’en-tête UDP est beaucoup plus simple que l’en-tête TCP car il n’a que quatre champs et nécessite 8 octets (c’est-à-dire 64 bits). La figure montre les champs d’un en-tête UDP.

14.3.3 Champs d’en-tête UDP
Le tableau identifie et décrit les quatre champs d’un en-tête UDP.
| Champ d’en-tête UDP | Description |
|---|---|
| Port source | Champ 16 bits utilisé pour identifier l’application source par le numéro de port. |
| Port de destination | Champ 16 bits utilisé pour identifier l’application de destination par numéro de port. |
| Longueur | Champ 16 bits indiquant la longueur de l’en-tête de datagramme UDP. |
| Somme de contrôle | Champ 16 bits utilisé pour la vérification des erreurs de l’en-tête et des données du datagramme. |
14.3.4 Applications utilisant l’UDP
Il existe trois types d’application plus adaptés au protocole UDP:
- Applications vidéo et multimédia en direct – Ces applications peuvent tolérer une certaine perte de données, mais ne nécessitent que peu ou pas de délai. La voix sur IP et le streaming vidéo en sont de bons exemples.
- Applications simples de demande et de réponse – Applications avec des transactions simples où un hôte envoie une demande et peut ou non recevoir une réponse. Exemples comprennent le DNS et le DHCP.
- Applications qui gèrent elles-mêmes la fiabilité – Communications unidirectionnelles où le contrôle de flux, la détection des erreurs, les accusés de réception et la récupération des erreurs ne sont pas nécessaires, ou peuvent être gérés par l’application. Exemples incluent: SNMP et TFTP.
La figure identifie les applications qui nécessitent UDP.
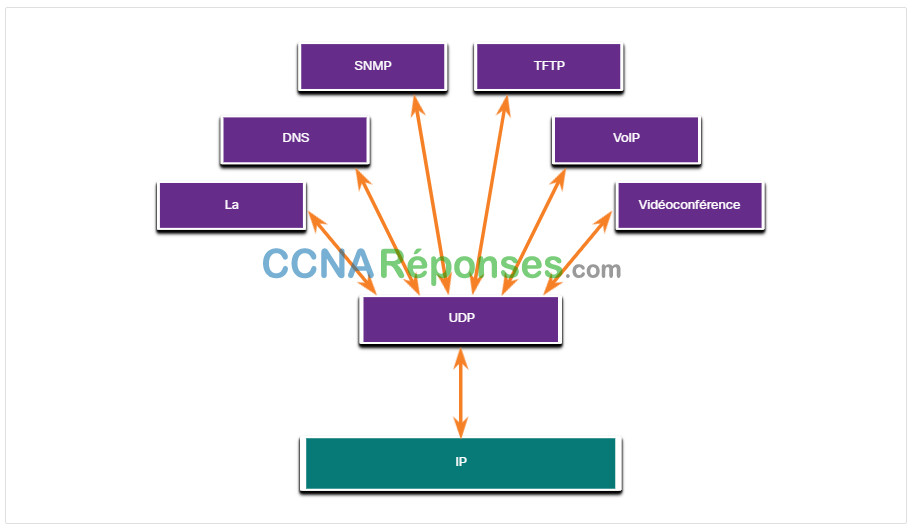
Bien que DNS et SNMP utilisent UDP par défaut, ces deux protocoles peuvent également utiliser TCP. Le DNS utilisera TCP si la requête ou la réponse DNS est supérieure à 512 octets, par exemple lorsqu’une réponse DNS comprend de nombreuses résolutions de noms. De manière similaire, dans certaines situations, il se peut que l’administrateur réseau souhaite configurer SNMP de manière à utiliser TCP.
14.4 Numéros de port
14.4.1 Communications Multiples et Séparées
Comme vous l’avez appris, il y a certaines situations dans lesquelles TCP est le bon protocole pour le travail, et d’autres situations dans lesquelles UDP devrait être utilisé. Quel que soit le type de données transportées, TCP et UDP utilisent des numéros de port.
Les protocoles de couches de transport TCP et UDP utilisent des numéros de port pour gérer plusieurs conversations simultanées. Comme le montre la figure, les champs d’en-tête TCP et UDP identifient un numéro de port d’application source et destination.

Le numéro de port source est associé à l’application d’origine sur l’hôte local tandis que le numéro de port de destination est associé à l’application de destination sur l’hôte distant.
Par exemple, supposons qu’un hôte initie une demande de page Web à partir d’un serveur Web. Lorsque l’hôte lance la demande de page Web, le numéro de port source est généré dynamiquement par l’hôte pour identifier de manière unique la conversation. Chaque requête générée par un hôte utilisera un numéro de port source différent, créé dynamiquement. Ce processus permet d’avoir plusieurs conversations simultanément.
Dans la demande, le numéro de port de destination est ce qui identifie le type de service demandé du serveur Web de destination. Par exemple, lorsque le client spécifie le port 80 comme port de destination, le serveur qui reçoit le message sait que des services web sont demandés.
Un serveur peut offrir plusieurs services simultanément, tels que des services web sur le port 80, tandis qu’il propose l’établissement d’une connexion FTP (File Transfer Protocol) sur le port 21.
14.4.2 Paires d’interfaces de connexion
Les ports sources et de destination sont placés à l’intérieur du segment. Les segments sont ensuite encapsulés dans un paquet IP. Le paquet IP contient l’adresse IP de la source et de la destination. La combinaison de l’adresse IP source et du numéro de port source, ou de l’adresse IP de destination et du numéro de port de destination, est appelée interface de connexion.
Dans l’exemple de la figure, le PC demande simultanément des services FTP et Web à partir du serveur de destination.
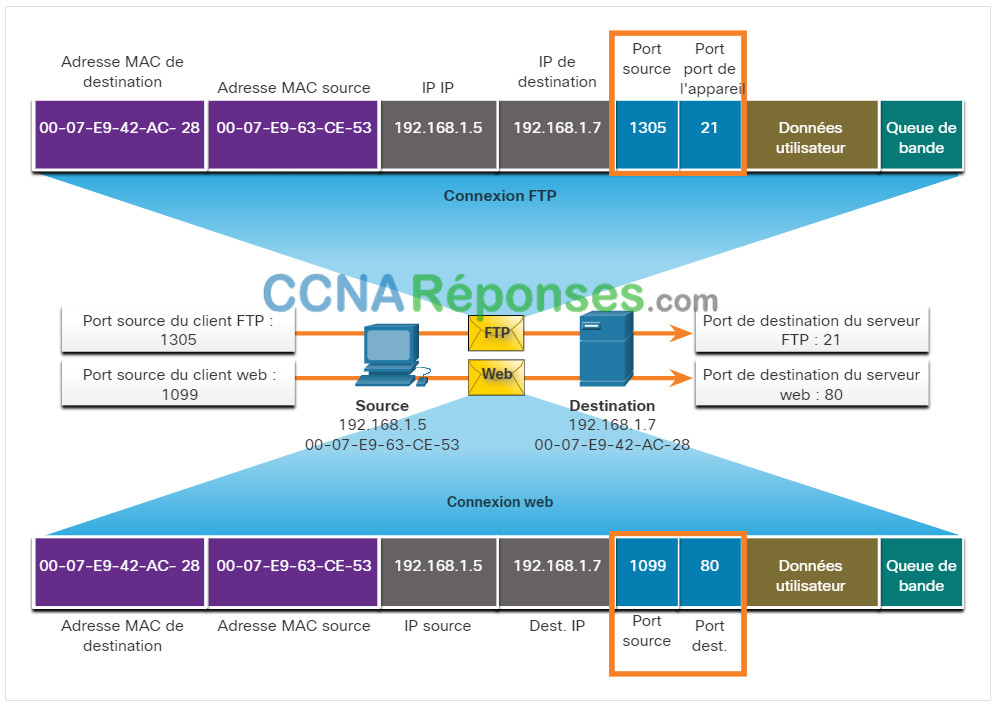
Dans l’exemple, la requête FTP générée par le PC inclut les adresses MAC de couche 2 et les adresses IP de couche 3. La demande identifie également le port source 1305 (c’est-à-dire généré dynamiquement par l’hôte) et le port de destination, identifiant les services FTP sur le port 21. L’hôte a également demandé une page Web au serveur utilisant les mêmes adresses de couche 2 et de couche 3. Cependant, il utilise le port source numéro 1099 (c’est-à-dire généré dynamiquement par l’hôte) et le port de destination identifiant le service Web sur le port 80.
L’interface de connexion sert à identifier le serveur et le service demandés par le client. Une interface de connexion cliente peut se présenter comme suit, 1099 représentant le numéro du port source : 192.168.1.5:1099
L’interface de connexion d’un serveur web peut être 192.168.1.7:80
Ensemble, ces deux interfaces de connexion constituent une paire d’interfaces de connexion: 192.168.1.5:1099 et 192.168.1.7:80
Les interfaces de connexion permettent à plusieurs processus exécutés sur un client de se différencier les uns des autres, et aux multiples connexions à un processus serveur de se distinguer les unes des autres.
Le numéro de port source fait office d’adresse de retour pour l’application envoyant la requête. La couche transport effectue le suivi du port et de l’application à l’origine de la requête afin que la réponse, quand elle sera envoyée, soit transmise à l’application appropriée.
14.4.3 Groupes de numéros de port
L’IANA (Internet Assigned Numbers Authority) est l’organisme de normalisation chargé d’attribuer diverses normes d’adressage, notamment les numéros de port de 16 bits. Les 16 bits utilisés pour identifier les numéros de port source et de destination fournissent une gamme de ports comprise entre 0 et 65535.
L’IANA a divisé la gamme de numéros en trois groupes de ports suivants.
Note: Certains systèmes d’exploitation clients peuvent utiliser des numéros de port enregistrés au lieu de numéros de port dynamiques pour l’attribution des ports sources.
Le tableau présente quelques numéros de port courants bien connus et leurs applications associées.
Well-Known Port Numbers
| Numéro de port | Protocole | Application |
|---|---|---|
| 20 | TCP | FTP (File Transfer Protocol) – Données |
| 21 | TCP | FTP (File Transfer Protocol) – Contrôle |
| 22 | TCP | SSH (Secure Shell) |
| 23 | TCP | Telnet |
| 25 | TCP | Protocole SMTP |
| 53 | UDP, TCP | Service de noms de domaine (Domain Name System, DNS) |
| 67 | UDP | Serveur DHCP (Dynamic Host Configuration Protocol) |
| 68 | UDP | Protocole DHCP (Dynamic Host Configuration Protocol) (client) |
| 69 | UDP | Protocole TFTP (Trivial File Transfer Protocol) |
| 80 | TCP | Protocole HTTP (Hypertext Transfer Protocol) |
| 110 | TCP | protocole POP3 (Post Office Protocol version 3) |
| 143 | TCP | IMAP (Internet Message Access Protocol) |
| 161 | UDP | Simple Network Management Protocol (SNMP) |
| 443 | TCP | protocole HTTPS (Hypertext Transfer Protocol Secure) |
Certaines applications utilisent le protocole TCP et le protocole UDP. Par exemple, DNS utilise le protocole UDP lorsque des clients envoient des requêtes à un serveur DNS. Toutefois, la communication entre deux serveurs DNS se fait toujours via le protocole TCP.
Recherchez le registre des ports sur le site web de l’IANA pour afficher la liste complète des numéros de port et des applications associées.
14.4.4 Commande netstat
Les connexions TCP inexpliquées peuvent poser un risque de sécurité majeur. Elles peuvent signaler que quelque chose ou quelqu’un est connecté à l’hôte local. Il est parfois nécessaire de savoir quelles connexions TCP actives sont ouvertes et s’exécutent sur un hôte en réseau. L’utilitaire netstat est un utilitaire de réseau important qui peut être utilisé pour vérifier ces connexions. Comme indiqué ci-dessous, entrez la commande netstat pour lister les protocoles utilisés, l’adresse et les numéros de port locaux, l’adresse et les numéros de port étrangers et l’état de la connexion.
C:\> netstat Active Connections Proto Local Address Foreign Address State TCP 192.168.1.124:3126 192.168.0.2:netbios-ssn ESTABLISHED TCP 192.168.1.124:3158 207.138.126.152:http ESTABLISHED TCP 192.168.1.124:3159 207.138.126.169:http ESTABLISHED TCP 192.168.1.124:3160 207.138.126.169:http ESTABLISHED TCP 192.168.1.124:3161 sc.msn.com:http ESTABLISHED TCP 192.168.1.124:3166 www.cisco.com:http ESTABLISHED (output omitted) C:\>
Par défaut, la netstat commande tentera de résoudre les adresses IP en noms de domaine et les numéros de port en applications connues. Cette -n option peut être utilisée pour afficher les adresses IP et les numéros de port sous leur forme numérique.
14.5 Processus de communication TCP
14.5.1 Processus serveur TCP
Vous connaissez déjà les principes fondamentaux de TCP. Comprendre le rôle des numéros de port vous aidera à saisir les détails du processus de communication TCP. Dans cette rubrique, vous découvrirez également les processus de poignée de main à trois voies TCP et de fin de session.
Chaque processus de demande s’exécutant sur un serveur est configuré pour utiliser un numéro de port. Le numéro de port est soit attribué automatiquement, soit configuré manuellement par un administrateur système.
Deux services ne peuvent pas être affectés au même numéro de port d’un serveur au sein des mêmes services de la couche transport. Par exemple, un hôte qui exécute une application de serveur web et une application de transfert de fichiers ne peut pas avoir les deux configurées pour utiliser le même port, tel que le port TCP 80.
Une application de serveur active affectée à un port spécifique est considérée comme étant ouverte, ce qui signifie que la couche transport accepte et traite les segments adressés à ce port. Toute demande entrante d’un client qui est adressée à l’interface de connexion correcte est acceptée et les données sont transmises à l’application de serveur. De nombreux ports peuvent être ouverts simultanément sur un serveur, chacun étant destiné à une application de serveur active.
Cliquez sur chaque bouton pour plus d’informations sur les processus du serveur TCP.
- Clients envoyant des requêtes TCP
- Ports de destination des requêtes
- Ports source des requêtes
- Ports de destination des réponses
- Ports source des réponses
Le client 1 demande des services Web et le client 2 demande un service de courriel à l'aide de ports bien connus (c-à-d. services Web = port 80, services de courriel = port 25).
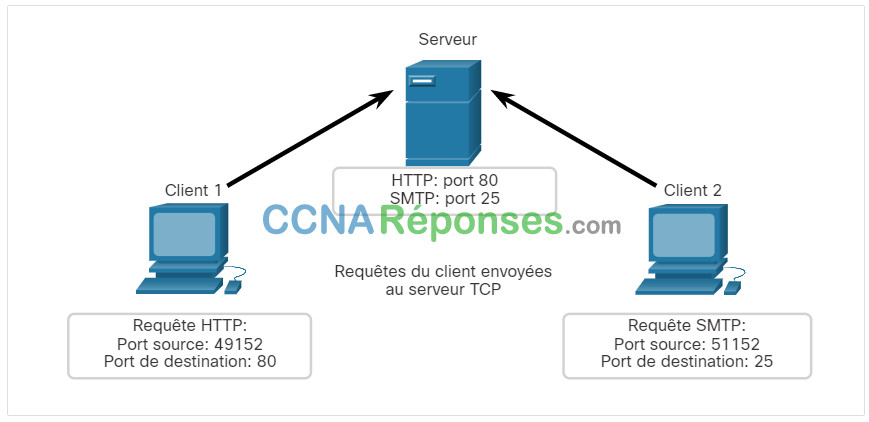
Les demandes génèrent dynamiquement un numéro de port source. Dans ce cas, le client 1 utilise le port source 49152 et le client 2 utilise le port source 51152.
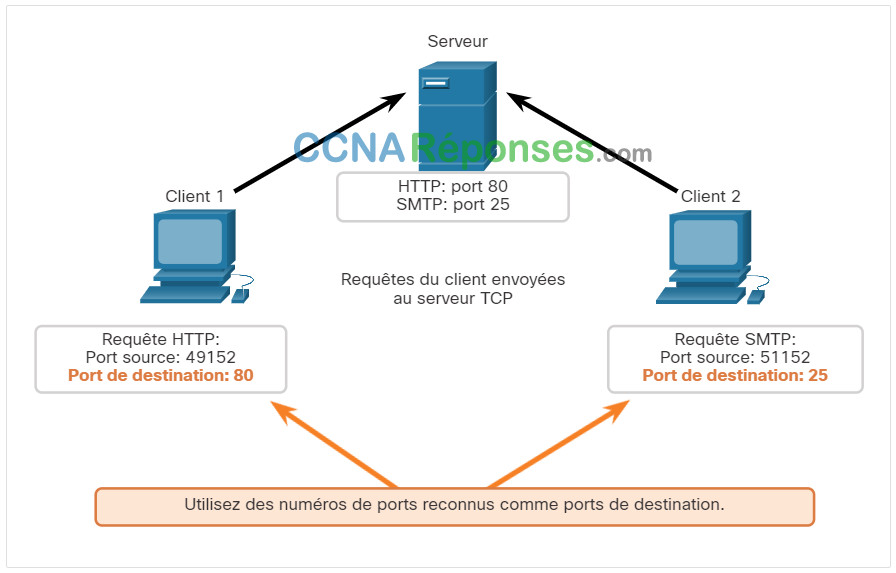
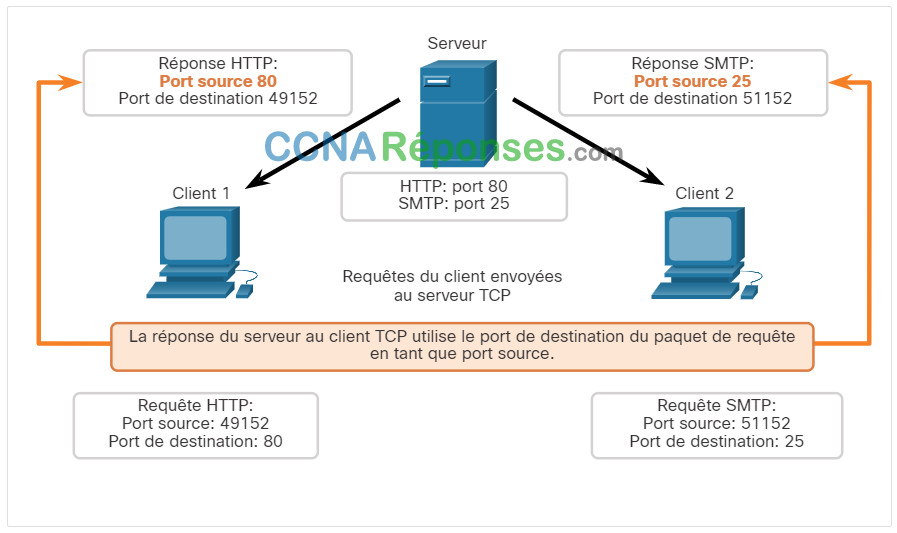
Lorsque le serveur répond aux demandes du client, il inverse les ports de destination et source de la demande initiale.
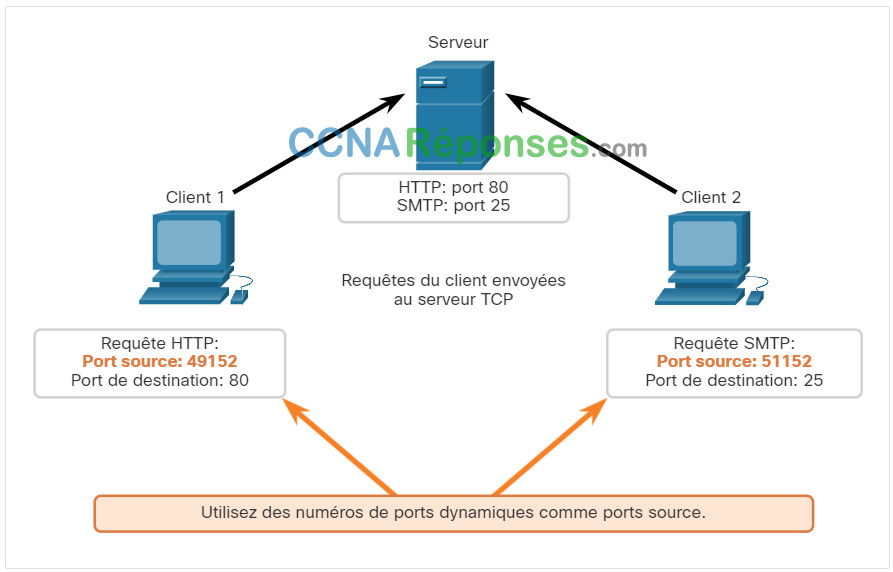
Notez que la réponse du serveur à la demande Web a maintenant le port de destination 49152 et que la réponse e-mail a maintenant le port de destination 51152.
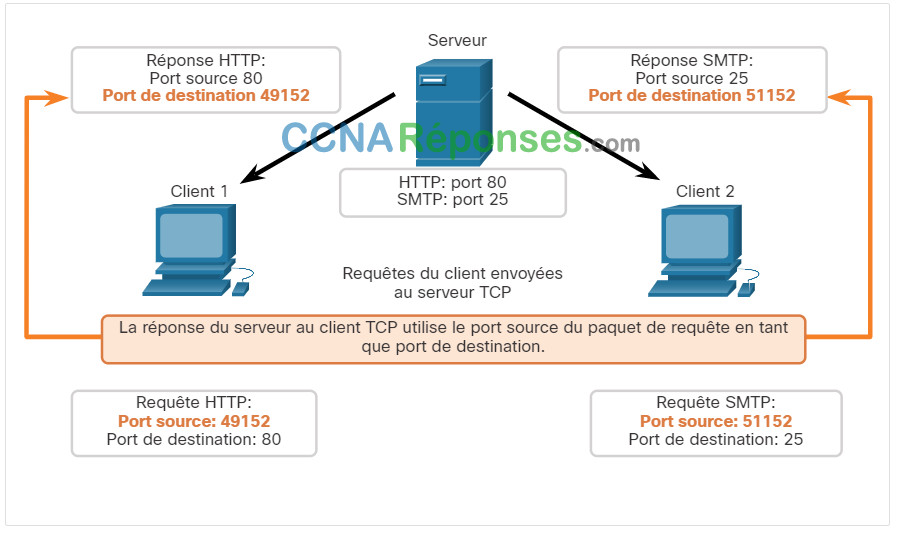
Le port source dans la réponse du serveur est le port de destination d'origine dans les demandes initiales.
14.5.2 Établissement d’une connexion TCP
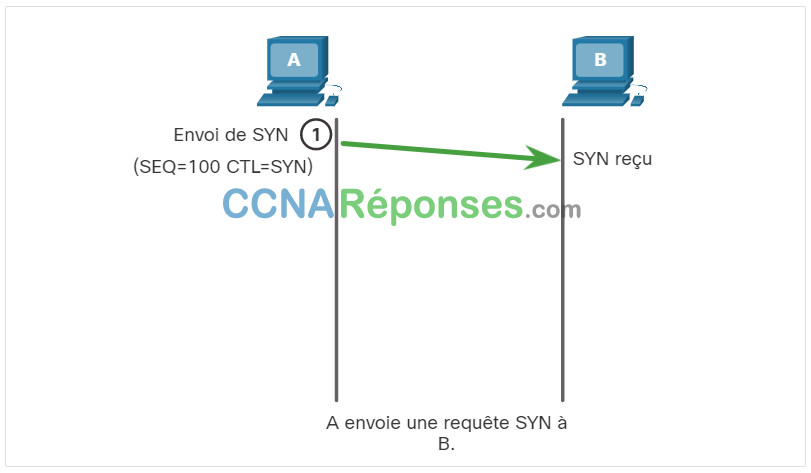
Dans certaines cultures, lorsque deux personnes se rencontrent, elles se saluent en se serrant la main. Les deux parties comprennent l’acte de serrer la main comme un signal de salutation amicale. D’une certaine manière, il en va de même pour les connexions sur le réseau. Dans les connexions TCP, le client hôte établit la connexion avec le serveur en utilisant le processus de poignée de main à trois voies.
Cliquez sur chaque bouton pour plus d’informations sur chaque étape d’établissement de connexion TCP.
Le client demande l'établissement d'une session de communication client-serveur avec le serveur.
Le serveur accuse réception de la session de communication client-serveur et demande l'établissement d'une session de communication serveur-client.
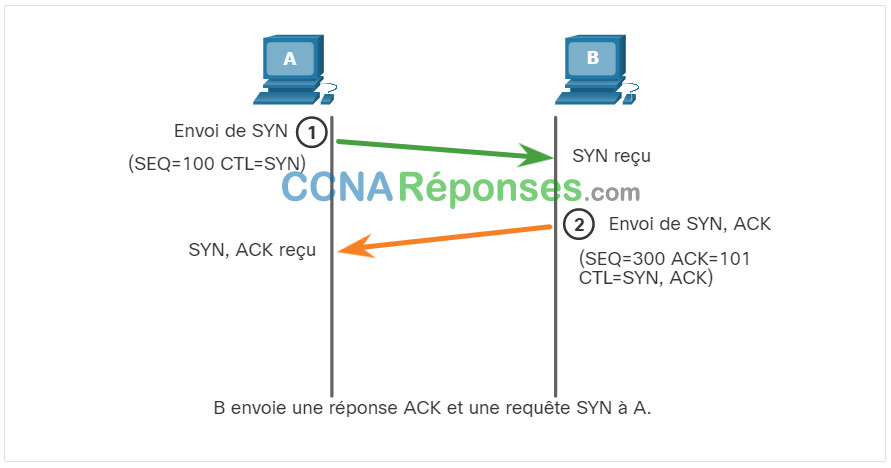
Le client accuse réception de la session de communication serveur-client.
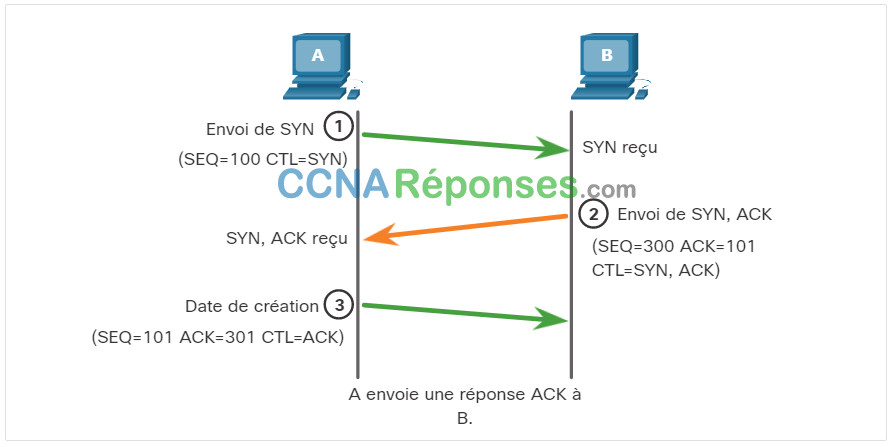
La connexion en trois étapes valide que l’hôte de destination est disponible pour communiquer. Dans cet exemple, l’hôte A a validé que l’hôte B est disponible.
14.5.3 Interruption de session
Pour mettre fin à une connexion, l’indicateur de contrôle FIN (Finish) doit être défini dans l’en-tête de segment. Pour mettre fin à chaque session TCP unidirectionnelle, on utilise un échange en deux étapes constitué d’un segment FIN et d’un segment ACK. Pour mettre fin à une seule conversation TCP, quatre échanges sont nécessaires pour mettre fin aux deux sessions. La terminaison peut être initiée par le client ou le serveur.
Dans l’exemple, les termes client et serveur sont utilisés comme référence pour plus de simplicité, mais deux hôtes quelconques qui ont une session ouverte peuvent lancer le processus de terminaison.
Cliquez sur chaque bouton pour plus d’informations sur les étapes de fin de session.
Quand le client n'a plus de données à envoyer dans le flux, il envoie un segment dont l'indicateur FIN est défini.

Le serveur envoie un segment ACK pour informer de la bonne réception du segment FIN afin de fermer la session du client au serveur.
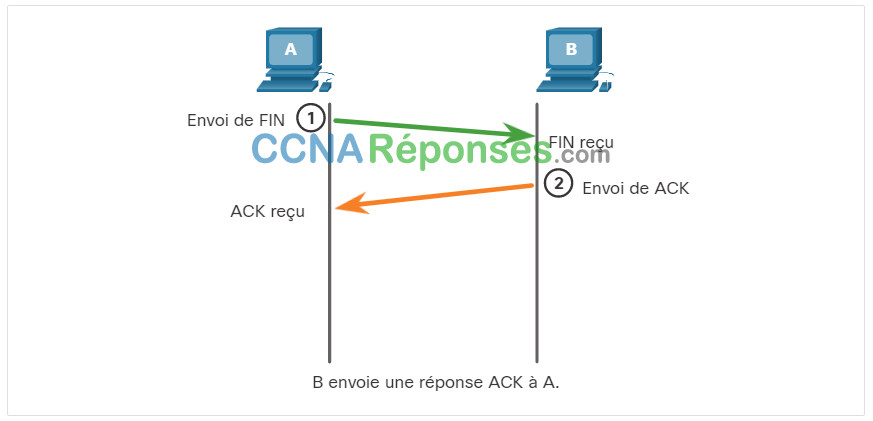
Le serveur envoie un segment FIN au client pour mettre fin à la session du serveur au client.
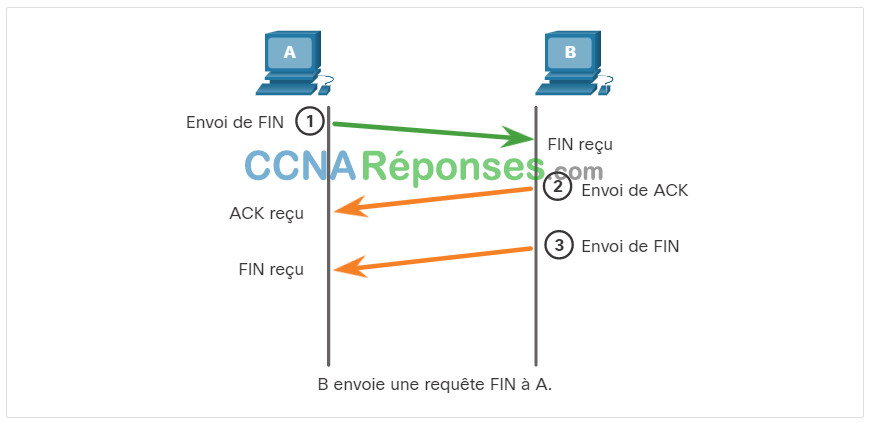
Le client répond à l'aide d'un segment ACK pour accuser réception du segment FIN envoyé par le serveur.
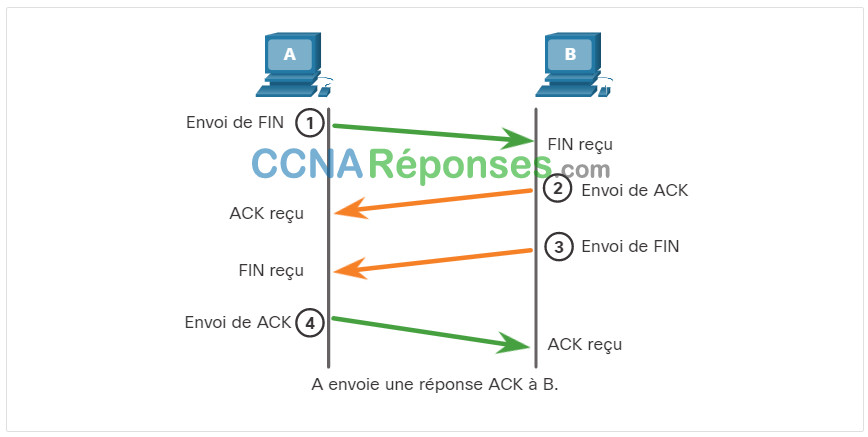
Quand la réception de tous les segments a été confirmée, la session est fermée.
14.5.4 Analyse de la connexion TCP en trois étapes
Les hôtes maintiennent l’état, suivent chaque segment de données au cours d’une session et échangent des informations sur les données reçues en utilisant les informations de l’en-tête TCP. TCP est un protocole full-duplex, où chaque connexion représente deux sessions de communication à sens unique. Pour établir la connexion, l’hôte effectue une connexion en trois étapes. Comme le montre la figure, les bits de contrôle dans l’en-tête TCP indiquent la progression et l’état de la connexion.
Ce sont les fonctions de la poignée de main à trois voies:
- Elle vérifie que le périphérique de destination est bien présent sur le réseau.
- Elle s’assure que le périphérique de destination a un service actif et qu’il accepte les requêtes sur le numéro de port de destination que le client qui démarre la session a l’intention d’utiliser.
- Elle informe le périphérique de destination que le client source souhaite établir une session de communication sur ce numéro de port.
Une fois la communication est terminée, les sessions sont terminées et la connexion est interrompue. Les mécanismes de connexion et de session permettent la fonction de fiabilité du TCP.
Champ des bits de contrôle

Les six bits du champ des bits de contrôle de l’en-tête du segment TCP sont également des indicateurs. Un indicateur est un bit qui est actif ou inactif.
Les six indicateurs de bits de contrôle sont les suivants:
- URG – Champ de pointeur urgent significatif (Urgent pointer field significant)
- ACK – Indicateur d’accusé de réception utilisé dans l’établissement de la connexion et la fin de la session
- PSH – Fonction push (Push function)
- RST – Réinitialisation de la connexion en cas d’erreur ou de dépassement de délai
- SYN – Synchroniser les numéros de séquence utilisés dans l’établissement de connexion
- FIN – Plus de données de l’expéditeur et utilisées dans la fin de session
Faites une recherche sur Internet pour en savoir plus sur les indicateurs de PSH et URG.
14.6 Fiabilité et contrôle des flux
14.6.1 Fiabilité du TCP – Livraison garantie et commandée
La raison pour laquelle TCP est le meilleur protocole pour certaines applications est que, contrairement à UDP, il renvoie les paquets abandonnés et numérote les paquets pour indiquer leur ordre correct avant la livraison. TCP peut également aider à maintenir le flux des paquets afin que les périphériques ne soient pas surchargés. Cette rubrique couvre en détail ces fonctionnalités de TCP.
Il peut arriver que les segments TCP n’arrivent pas à leur destination. D’autres fois, les segments TCP peuvent arriver en mauvais état. Pour que le message original soit compris par le destinataire, toutes les données doivent être reçues et les données de ces segments doivent être réassemblées dans l’ordre original. Pour cela, des numéros d’ordre sont affectés à l’en-tête de chaque paquet. Le numéro d’ordre représente le premier octet de données du segment TCP.
Lors de la configuration de la session, un numéro d’ordre initial, ou ISN, est défini. Cet ISN représente la valeur de départ des octets de cette session qui est transmise à l’application destinataire. Lors de la transmission des données pendant la session, le numéro d’ordre est incrémenté du nombre d’octets ayant été transmis. Ce suivi des octets de données permet d’identifier chaque segment et d’en accuser réception individuellement. Il est ainsi possible d’identifier les segments manquants.
L’ISN ne commence pas à un mais est en fait un nombre aléatoire. Cela permet d’empêcher certains types d’attaques de programmes malveillants. Pour des raisons de simplicité, nous utiliserons un ISN égal à 1 dans les exemples de ce chapitre.
Les numéros d’ordre des segments indiquent comment réassembler et réordonnancer les segments reçus, ainsi que l’illustre la figure ci-contre.
Les segments TCP sont réorganisés au niveau de la destination
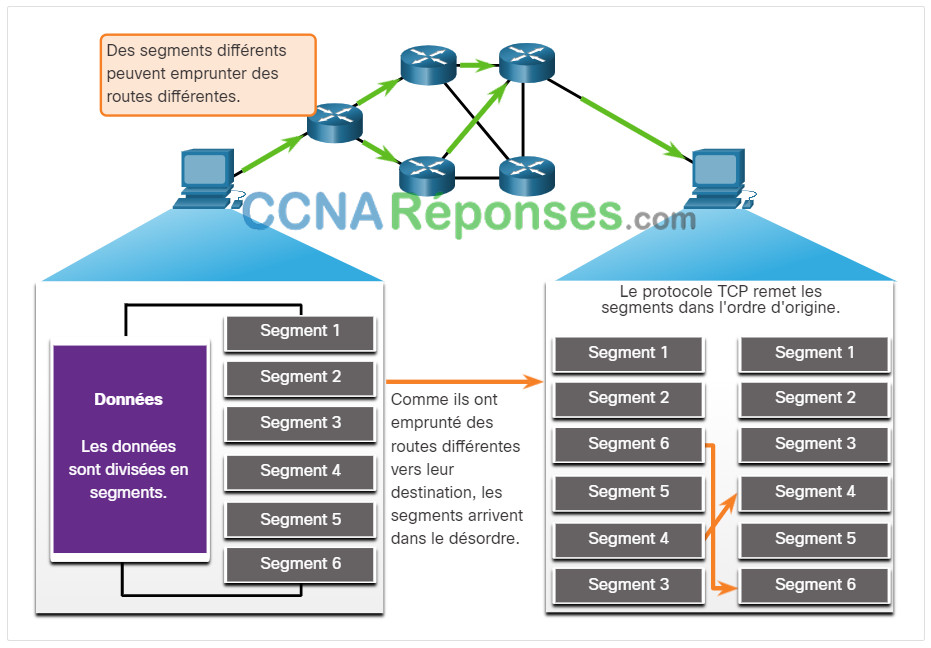
Le processus TCP récepteur place les données d’un segment dans une mémoire tampon de réception. Les segments sont ensuite placés dans l’ordre approprié et transmis à la couche d’application lorsqu’ils sont réassemblés. Tous les segments qui arrivent en désordre sont conservés en vue d’un traitement ultérieur. Ces segments sont ensuite traités dans l’ordre lorsque les segments contenant les octets manquants sont reçus.
14.6.3 Fiabilité du TCP – Perte de données et retransmission
Quelle que soit la conception d’un réseau, la perte de données qui se produit occasionnellement. Le protocole TCP fournit des méthodes de gestion des pertes de segments. Parmi elles se trouve un mécanisme de retransmission des segments pour les données sans accusé de réception.
Le numéro d’ordre (SEQ) et le numéro d’accusé de réception (ACK) sont utilisés ensemble pour confirmer la réception des octets de données contenus dans les segments envoyés. Le numéro SEQ identifie le premier octet de données dans le segment transmis. Le protocole TCP utilise le numéro ACK renvoyé à la source pour indiquer l’octet suivant que le destinataire s’attend à recevoir. C’est ce que l’on appelle un accusé de réception prévisionnel.
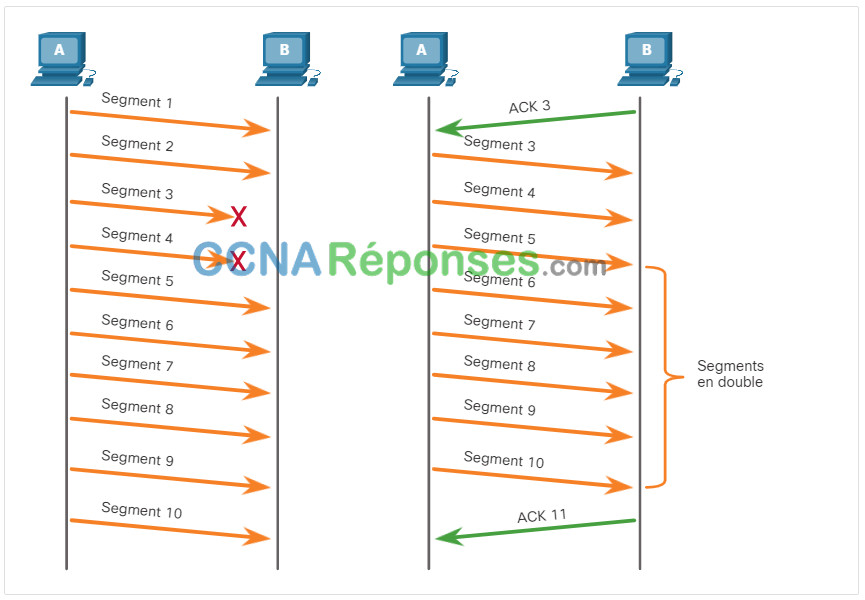
Avant les améliorations ultérieures, TCP ne pouvait reconnaître que l’octet suivant attendu. Par exemple, dans la figure, en utilisant des numéros de segment pour simplifier, l’hôte A envoie les segments 1 à 10 à l’hôte B. Si tous les segments arrivent à l’exception des segments 3 et 4, l’hôte B répondra en indiquant que le segment suivant attendu est le segment 3. L’hôte A n’a aucune idée si d’autres segments sont arrivés ou non. L’hôte A renverrait donc les segments 3 à 10. Si tous les segments de répétition arrivaient avec succès, les segments 5 à 10 seraient des doublons. Cela peut entraîner des retards, des embouteillages et des inefficacités.
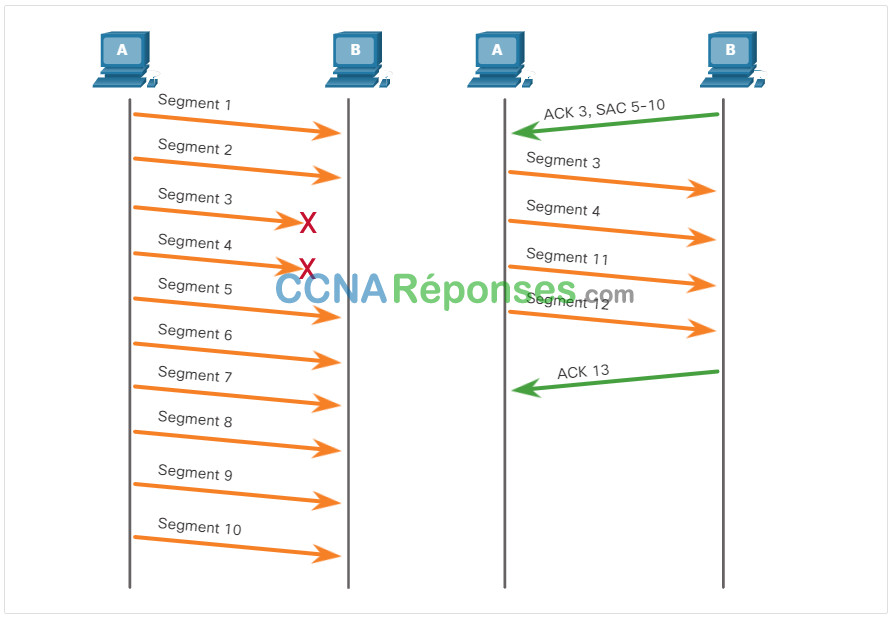
Aujourd’hui, les systèmes d’exploitation hôtes utilisent généralement une fonctionnalité TCP facultative appelée reconnaissance sélective (SACK), négociée au cours de la poignée de main à trois voies. Si les deux hôtes prennent en charge SACK, le récepteur peut explicitement reconnaître quels segments (octets) ont été reçus, y compris les segments discontinus. L’hôte émetteur n’aurait donc qu’à retransmettre les données manquantes. Par exemple, dans la figure suivante, à nouveau en utilisant des numéros de segment pour simplifier, l’hôte A envoie les segments 1 à 10 à l’hôte B. Si tous les segments arrivent à l’exception des segments 3 et 4, l’hôte B peut reconnaître qu’il a reçu les segments 1 et 2 (ACK 3) et reconnaître sélectivement les segments 5 à 10 (SACK 5-10). L’hôte A n’aurait besoin que de renvoyer les segments 3 et 4.
Remarque: TCP envoie généralement des ACK pour tous les autres paquets, mais d’autres facteurs au-delà de la portée de cette rubrique peuvent modifier ce comportement.
TCP utilise des minuteries pour savoir combien de temps attendre avant de renvoyer un segment. Dans la figure, lisez la vidéo et cliquez sur le lien pour télécharger le fichier PDF. La vidéo et le fichier PDF examinent la perte de données TCP et la retransmission.
14.6.5 Contrôle de flux TCP – Taille de fenêtre et accusés de réception
Le protocole TCP offre des mécanismes de contrôle des flux. Le protocole TCP inclut également des mécanismes de contrôle de flux, qui correspond au volume de données que l’hôte de destination peut recevoir et traiter de manière fiable. Le contrôle de flux aide à maintenir la fiabilité des transmissions TCP en réglant le flux de données entre la source et la destination pour une session donnée. Pour cela, l’en-tête TCP inclut un champ de 16 bits appelé taille de fenêtre.
La figure illustre un exemple de taille de fenêtre et d’accusés de réception.
Exemple de taille de fenêtre TCP
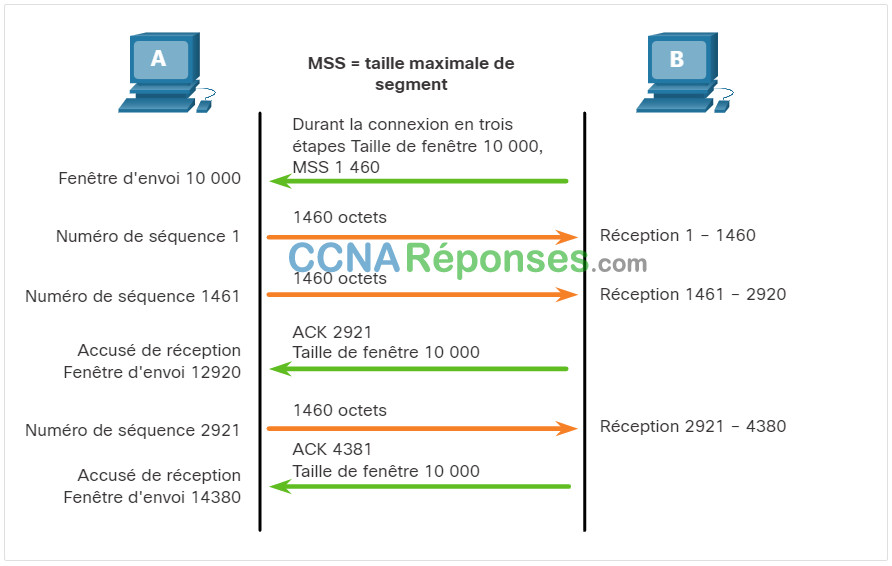
La taille de fenêtre détermine le nombre d’octets qui peuvent être envoyés avant de recevoir un accusé de réception. Le numéro d’accusé de réception est le numéro du prochain octet attendu.
La taille de fenêtre est le nombre d’octets que le périphérique de destination d’une session TCP peut accepter et traiter en une fois. Dans cet exemple, la taille initiale de la fenêtre du PC B pour la session TCP est de 10000 octets. En commençant par le premier octet, à savoir l’octet numéro 1, le dernier octet que le PC-A peut envoyer sans recevoir d’accusé de réception est l’octet 10000. C’est ce qu’on appelle la fenêtre d’envoi du PC A. La taille de la fenêtre est incluse dans chaque segment TCP, de sorte que la destination peut modifier la taille de la fenêtre à tout moment en fonction de la disponibilité de la mémoire tampon.
La taille de fenêtre initiale est déterminée lors de l’établissement de la session TCP par l’intermédiaire de la connexion en trois étapes. Le périphérique source doit limiter le nombre d’octets envoyés au périphérique de destination en fonction de la taille de la fenêtre de la destination. Une fois que le périphérique source a reçu un accusé de réception l’informant que les octets ont été reçus, il peut continuer à envoyer plus de données pour la session. D’une manière générale, la destination n’attend pas que tous les octets de sa taille de fenêtre aient été reçus avant de répondre par un accusé de réception. Une fois que tous les octets ont été reçus et traités, la destination envoie des accusés de réception afin d’informer la source qu’elle peut continuer à envoyer des octets supplémentaires.
Par exemple, il est typique que le PC B n’attende pas que les 10000 octets aient été reçus avant d’envoyer un accusé de réception. Cela signifie que le PC A peut ajuster sa fenêtre d’envoi lorsqu’il reçoit des accusés de réception du PC B. Comme le montre la figure, lorsque le PC A reçoit un accusé de réception portant le numéro 2921, qui est le prochain octet attendu. La fenêtre d’envoi PC A va incrémenter 2920 octets. Cela change la fenêtre d’envoi de 10000 octets à 12920. Le PC A peut maintenant continuer à envoyer jusqu’à 10000 octets supplémentaires au PC B tant qu’il n’envoie pas plus que sa nouvelle fenêtre d’envoi à 12920.
Une destination qui envoie des accusés de réception au fur et à mesure qu’elle traite les octets reçus, et l’ajustement continu de la fenêtre d’envoi source, sont connus sous le nom de fenêtres coulissantes. Dans l’exemple précédent, la fenêtre d’envoi du PC A incrémente ou glisse sur un autre 2 921 octets, passant de 10000 à 12920.
Si l’espace libre dans la mémoire tampon de la destination diminue, cette dernière peut réduire sa taille de fenêtre afin de demander à la source de diminuer le nombre d’octets envoyés avant de recevoir un accusé de réception.
Remarque: Les appareils d’aujourd’hui utilisent le protocole des fenêtres coulissantes. Le récepteur envoie généralement un accusé de réception tous les deux segments qu’il reçoit. Le nombre de segments reçus avant l’envoi d’un accusé de réception peut varier. L’avantage des fenêtres dynamiques est de permettre à l’expéditeur de transmettre des segments en continu, tant que le destinataire accuse réception des segments précédents. Les détails de la fonction de hachage sortent du cadre de ce cours.
14.6.6 Contrôle de flux TCP – Taille maximale du segment (MSS)
Dans la figure, la source transmet 1460 octets de données dans chaque segment TCP. Il s’agit généralement de la taille maximale de segment (MSS) que le périphérique de destination peut recevoir. Le MSS fait partie du champ d’options de l’en-tête TCP qui spécifie la plus grande quantité de données, en octets, qu’un périphérique peut recevoir dans un seul segment TCP. La taille MSS n’inclut pas l’en-tête TCP. Le MSS est généralement inclus lors de la poignée de main à trois voies.
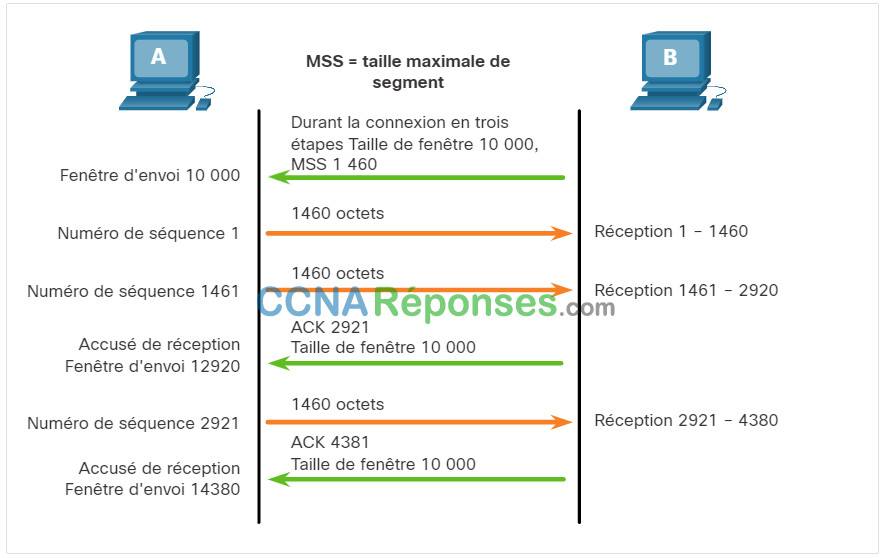
Un MSS commun est de 1 460 octets lors de l’utilisation d’IPv4. Un hôte détermine la valeur de son champ MSS en soustrayant les en-têtes IP et TCP de la MTU Ethernet. La MTU par défaut d’une interface Ethernet est de 1500 octets. En retranchant l’en-tête IPv4 de 20 octets et l’en-tête TCP de 20 octets, la taille par défaut du MSS sera de 1460 octets, comme le montre la figure.

14.6.7 Contrôle de flux TCP – Prévention des encombrements
Lorsque la congestion se produit sur un réseau, elle a pour conséquence que les paquets sont rejetés par le routeur surchargé. Lorsque les paquets contenant des segments TCP n’atteignent pas leur destination, ils sont laissés sans accusé de réception. En déterminant la vitesse à laquelle les segments TCP sont envoyés, mais non reçus, la source peut estimer le niveau d’encombrement du réseau.
Chaque fois qu’il y a encombrement, les segments TCP perdus sont retransmis par la source. Si la retransmission n’est pas correctement contrôlée, une retransmission supplémentaire des segments TCP peut aggraver encore le niveau d’encombrement du réseau. Non seulement de nouveaux paquets contenant des segments TCP sont introduits sur le réseau, mais l’effet de rétroaction des segments TCP perdus et retransmis encombre encore davantage le réseau. Afin d’éviter et de contrôler l’encombrement du réseau, le protocole TCP utilise divers mécanismes, minuteurs et algorithmes de gestion des encombrements.
Si la source détermine que les segments TCP n’ont pas été reçus ou qu’ils n’ont pas été reçus à temps, elle peut diminuer le nombre d’octets à envoyer avant la réception d’un accusé de réception. Comme illustré dans la figure, PC A détecte une congestion et réduit donc le nombre d’octets qu’il envoie avant de recevoir un accusé de réception de PC B.
Contrôle d’encombrement TCP
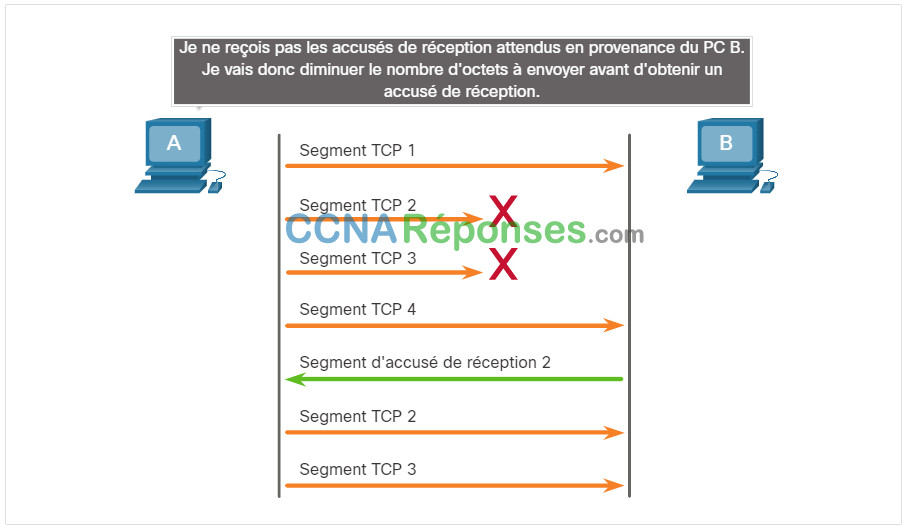
Notez que c’est la source qui diminue le nombre d’octets non reçus à envoyer et non la taille de fenêtre déterminée par la destination.
Remarque: L’explication des mécanismes, des minuteurs et des algorithmes réels de gestion des encombrements sort du cadre de ce cours.
14.7 Communication UDP
14.7.1 Faible surcharge et fiabilité du protocole UDP
Comme expliqué précédemment, UDP est parfait pour les communications qui doivent être rapides, comme la VoIP. Cette rubrique explique en détail pourquoi UDP est parfait pour certains types de transmissions. Comme le montre la figure, UDP n’établit pas de connexion. Le protocole UDP fournit un transport de données à faible surcharge car il utilise de petits en-têtes de datagrammes et n’offre pas de gestion du trafic réseau.
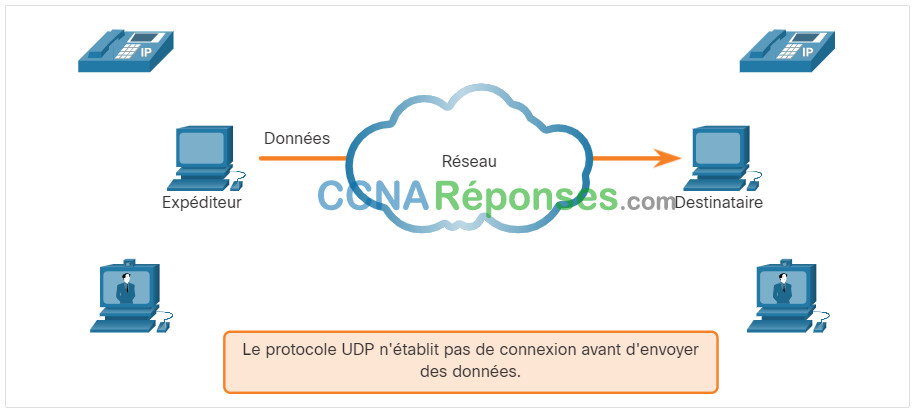
14.7.2 Réassemblage de datagrammes UDP
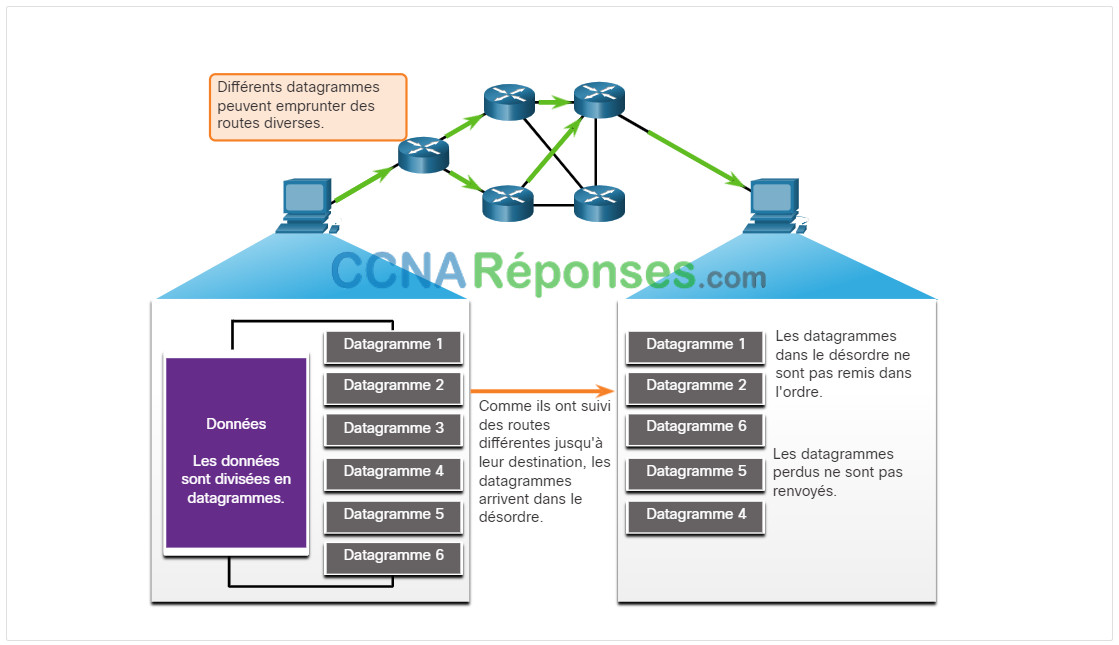
Comme pour les segments envoyés au moyen du protocole TCP, lorsque des datagrammes UDP sont envoyés vers une destination, ils peuvent souvent emprunter des chemins différents et arriver dans le désordre. Le protocole UDP n’effectue pas de suivi des numéros d’ordre comme le fait le protocole TCP. Le protocole UDP ne peut pas réassembler les datagrammes dans leur ordre de transmission, comme illustré dans la figure.
Le protocole UDP se contente donc de réassembler les données dans l’ordre dans lequel elles ont été reçues, puis de les transmettre à l’application. Si l’ordre des données est important pour l’application, cette dernière doit identifier l’ordre correct et déterminer le mode de traitement des données.
UDP : sans connexion et peu fiable
14.7.3 Processus et requêtes des serveurs UDP
Comme pour les applications basées sur le protocole TCP, des numéros de ports réservés sont affectés aux applications serveur basées sur le protocole UDP, comme le montre la figure. Lorsque ces applications ou processus s’exécutent sur un serveur, elles ou ils acceptent les données correspondant au numéro de port attribué. Quand le protocole UDP reçoit un datagramme destiné à l’un de ces ports, il transmet les données applicatives à l’application appropriée d’après son numéro de port.
Écoute du serveur UDP pour les requêtes
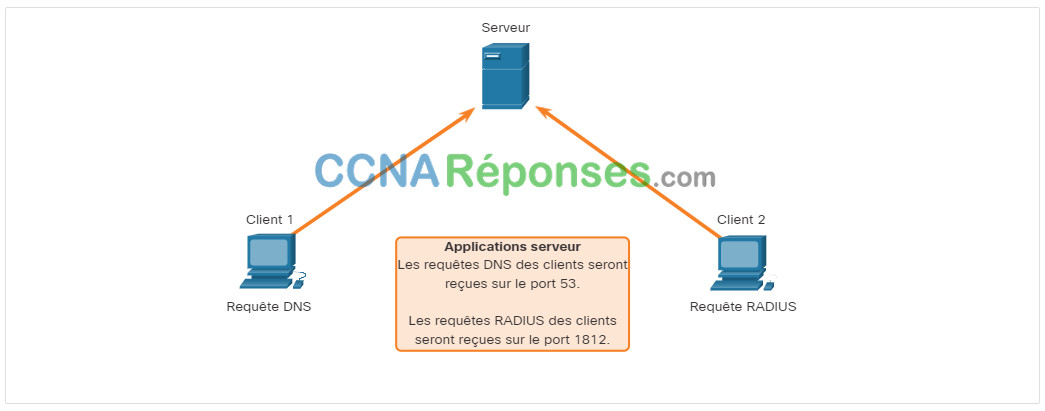
Remarque: Le serveur RADIUS (Remote Authentication Dial-in User Service) illustré dans la figure fournit des services d’authentification, d’autorisation et de comptabilité pour gérer l’accès des utilisateurs. Le fonctionnement de RADIUS sort du cadre de ce cours.
14.7.4 Processus des clients UDP
Comme c’est le cas avec le protocole TCP, la communication entre le client et le serveur est initiée par une application cliente qui demande des données à un processus serveur. Le processus client UDP sélectionne dynamiquement un numéro de port dans une plage de numéros de ports et il l’utilise en tant que port source pour la conversation. Le port de destination est généralement le numéro de port réservé affecté au processus serveur.
Après qu’un client a sélectionné les ports source et destination, la même paire de ports est utilisée dans l’en-tête de tous les datagrammes de la transaction. Quand des données sont renvoyées du serveur vers le client, les numéros de port source et de port de destination sont inversés dans l’en-tête du datagramme.
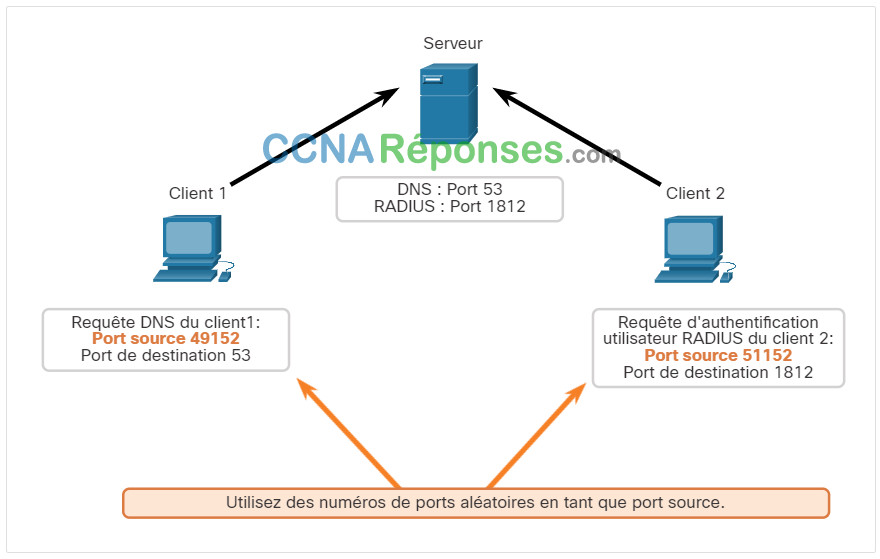
Cliquez sur chaque bouton pour obtenir une illustration de deux hôtes demandant des services à partir du serveur d’authentification DNS et RADIUS.
- Clients envoyant des requêtes UDP
- Ports destination des requêtes UDP
- Ports source des requêtes UDP
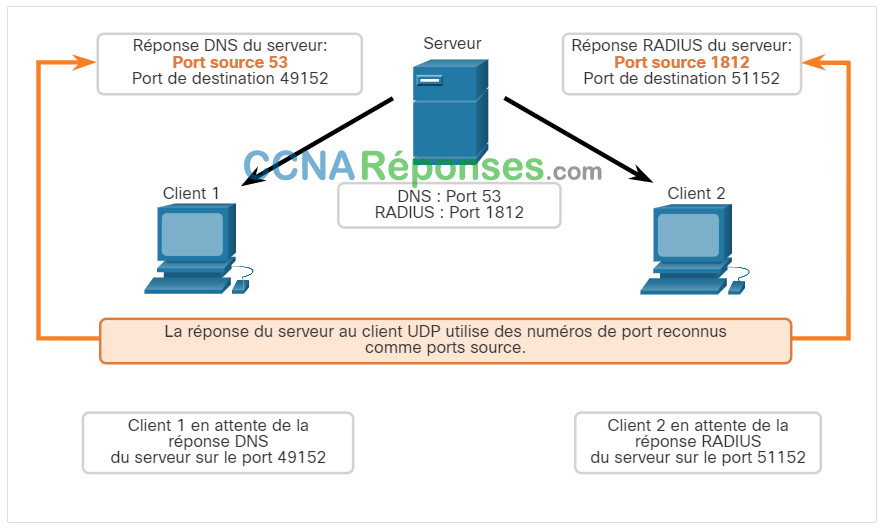
- Destination de la réponse UDP
- Ports source des réponses
Le client 1 envoie une requête DNS en utilisant le port 53 bien connu tandis que le client 2 demande les services d'authentification RADIUS en utilisant le port 1812 enregistré.
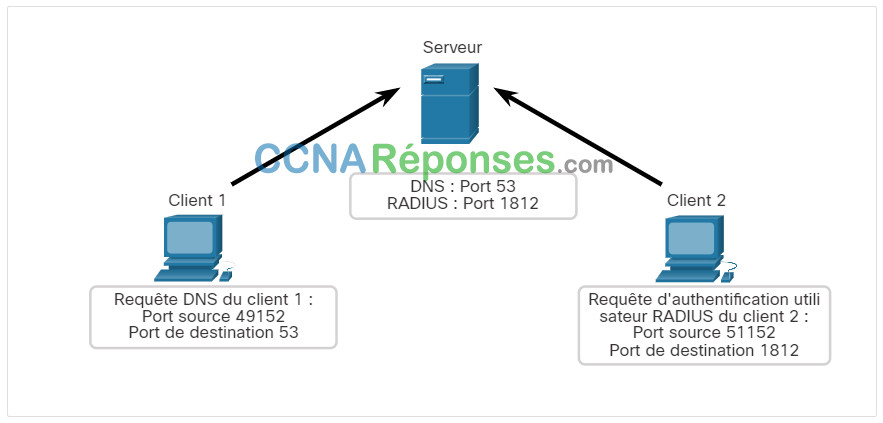
Les requêtes des clients génèrent dynamiquement des numéros de port source. Dans ce cas, le client 1 utilise le port source 49152 et le client 2 utilise le port source 51152.
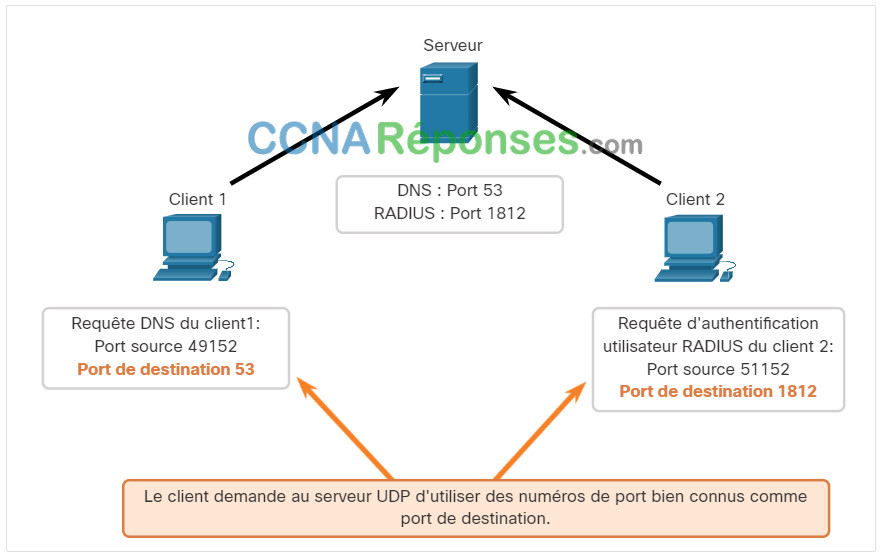
Lorsque le serveur répond aux demandes du client, il inverse les ports de destination et source de la demande initiale.
Dans la réponse du serveur à la demande DNS est maintenant le port de destination 49152 et la réponse d'authentification RADIUS est maintenant le port de destination 51152.
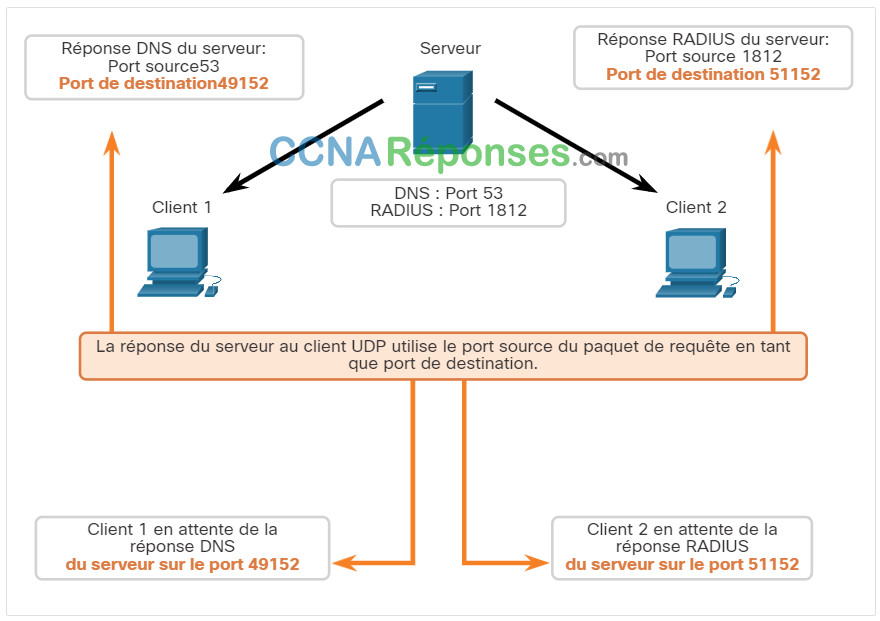
Les ports source dans la réponse du serveur sont les ports de destination d'origine dans les demandes initiales.
14.8 Module pratique et questionnaire
14.8.1 Packet Tracer – Communications TCP et UDP
Dans cette activité, vous explorerez la fonctionnalité des protocoles TCP et UDP, le multiplexage et la fonction des numéros de port pour déterminer quelle application locale a demandé les données ou envoie les données.
14.8.2 Qu’est-ce que j’ai appris dans ce module?
Transport des données
La couche transport est le lien entre la couche application et les couches inférieures qui sont responsables de la transmission du réseau. La couche de transport est responsable des communications logiques entre les applications exécutées sur différents hôtes. La couche transport comprend à la fois les protocoles TCP et UDP. Les protocoles de couche de transport spécifient comment transférer des messages entre les hôtes et sont responsables de la gestion des exigences de fiabilité d’une conversation. La couche de transport est responsable du suivi des conversations (sessions), de la segmentation des données et de la réassemblage des segments, de l’ajout d’informations d’en-tête, de l’identification des applications et du multiplexage des conversations. Le TCP est en état, fiable, reconnaît les données, renvoie les données perdues et livre les données dans un ordre séquentiel. Utilisez TCP pour le courrier électronique et le Web. L’UDP est apatride, rapide, a une faible surcharge, ne nécessite pas d’accusé de réception, ne renvoie pas les données perdues et livre les données dans l’ordre où elles arrivent. Utilisez UDP pour VoIP et DNS.
Aperçu du TCP
TCP établit les sessions, assure la fiabilité, assure la livraison de même ordre et prend en charge le contrôle des flux. Un segment TCP ajoute 20 octets de surcharge en tant qu’informations d’en-tête lors de l’encapsulation des données de la couche d’application. Les champs de l’en-tête TCP sont les suivants : ports source et destination, numéro de séquence, numéro d’accusé de réception, longueur de l’en-tête, réservé, bits de contrôle, taille de la fenêtre, somme de contrôle et urgent. Les applications qui utilisent le TCP sont HTTP, FTP, SMTP et Telnet.
Aperçu du UDP
UDP reconstruit les données dans l’ordre où elles sont reçues, les segments perdus ne sont pas réenvoyés, aucun établissement de session et UDP n’informe pas l’expéditeur de la disponibilité des ressources. Les champs d’en-tête UDP sont les suivants : Ports source et destination, longueur et somme de contrôle. Les applications qui utilisent UDP sont DHCP, DNS, SNMP, TFTP, VoIP et vidéo conférence.
Numéros de port
Les protocoles de couches de transport TCP et UDP utilisent des numéros de port pour gérer plusieurs conversations simultanées. C’est pourquoi les champs d’en-tête TCP et UDP identifient un numéro de port d’application source et de destination. Les ports sources et de destination sont placés à l’intérieur du segment. Les segments sont ensuite encapsulés dans un paquet IP. Le paquet IP contient l’adresse IP de la source et de la destination. La combinaison de l’adresse IP source et du numéro de port source, ou de l’adresse IP de destination et du numéro de port de destination, est appelée interface de connexion. L’interface de connexion sert à identifier le serveur et le service demandés par le client. Il y a une gamme de numéros de port de 0 à 65535. Cette gamme est divisée en groupes: Ports connus, Ports enregistrés, Ports privés et/ou dynamiques. Il y a quelques numéros de port connus qui sont réservés aux applications courantes telles que FTP, SSH, DNS, HTTP et autres. Il est parfois nécessaire de savoir quelles connexions TCP actives sont ouvertes et s’exécutent sur un hôte en réseau. L’utilitaire netstat est un utilitaire de réseau important qui peut être utilisé pour vérifier ces connexions.
Processus de communication du TCP
Chaque processus de demande s’exécutant sur un serveur est configuré pour utiliser un numéro de port. Le numéro de port est soit attribué automatiquement, soit configuré manuellement par un administrateur système. Les processus serveur TCP sont les suivants: clients qui envoient des requêtes TCP, demandent des ports de destination, demandent des ports source, répondent aux demandes de port de destination et de port source. Pour mettre fin à une seule conversation TCP, quatre échanges sont nécessaires pour mettre fin aux deux sessions. La terminaison peut être initiée par le client ou le serveur. La poignée de main à trois voies établit que le périphérique de destination est présent sur le réseau, vérifie que le périphérique de destination dispose d’un service actif et accepte les demandes sur le numéro de port de destination que le client initiateur a l’intention d’utiliser, et informe le périphérique de destination que le client source a l’intention d’organiser une session de communication sur ce numéro de port. Les six indicateurs de bits de contrôle sont: URG, ACK, PSH, RST, SYN et FIN.
Fiabilité et contrôle des flux
Pour que le message original soit compris par le destinataire, toutes les données doivent être reçues et les données de ces segments doivent être réassemblées dans l’ordre original. Des numéros d’ordre sont affectés à l’en-tête de chaque paquet. Quelle que soit la conception d’un réseau, la perte de données se produit occasionnellement. TCP fournit des moyens de gérer les pertes de segment. Parmi elles se trouve un mécanisme de retransmission des segments pour les données sans accusé de réception. Aujourd’hui, les systèmes d’exploitation hôtes utilisent généralement une fonctionnalité TCP facultative appelée reconnaissance sélective (SACK), négociée au cours de la poignée de main à trois voies. Si les deux hôtes prennent en charge SACK, le récepteur peut explicitement reconnaître quels segments (octets) ont été reçus, y compris les segments discontinus. L’hôte émetteur n’aurait donc qu’à retransmettre les données manquantes. Le contrôle de flux aide à maintenir la fiabilité des transmissions TCP en réglant le flux de données entre la source et la destination pour une session donnée. Pour cela, l’en-tête TCP inclut un champ de 16 bits appelé taille de fenêtre. Le processus d’envoi d’accusés de réception par la destination en fonction du traitement des octets reçus et d’ajustement continu de la fenêtre d’envoi de la source porte le nom de « fenêtres glissantes ». Une source peut transmettre 1 460 octets de données dans chaque segment TCP. Il s’agit du MSS typique qu’un périphérique de destination peut recevoir. Pour éviter et contrôler les congestions, le TCP utilise plusieurs mécanismes de traitement des congestions. C’est la source qui réduit le nombre d’octets non reconnus qu’elle envoie et non la taille de la fenêtre déterminée par la destination.
Communication du UDP
Le protocole UDP est un protocole simple offrant des fonctions de couche transport de base. Lorsque les datagrammes UDP sont envoyés à une destination, ils empruntent souvent des chemins différents et arrivent dans le mauvais ordre. Le protocole UDP n’effectue pas de suivi des numéros d’ordre comme le fait le protocole TCP. Il n’a en effet aucun moyen de réordonnancer les datagrammes pour leur faire retrouver leur ordre de transmission d’origine. Le protocole UDP se contente donc de réassembler les données dans l’ordre dans lequel elles ont été reçues, puis de les transmettre à l’application. Si l’ordre des données est important pour l’application, cette dernière doit identifier l’ordre correct et déterminer le mode de traitement des données. Les applications serveur basées sur l’UDP se voient attribuer des numéros de port connus ou enregistrés. Quand le protocole UDP reçoit un datagramme destiné à l’un de ces ports, il transmet les données applicatives à l’application appropriée d’après son numéro de port. Le processus client UDP sélectionne dynamiquement un numéro de port dans une plage de numéros de ports et il l’utilise en tant que port source pour la conversation. Le port de destination est généralement le numéro de port réservé affecté au processus serveur. Après qu’un client a sélectionné les ports source et destination, la même paire de ports est utilisée dans l’en-tête de tous les datagrammes utilisés dans la transaction. Quand des données sont renvoyées du serveur vers le client, les numéros de port source et de port de destination sont inversés dans l’en-tête du datagramme.